【不含CPU,超越GPU 1000x】Wave公司发布数据流处理架构DPU

新智元编译
来源:nextplatform.com
作者:Nicole Hemsoth
编译:闻菲
【新智元导读】Wave Computing 在日前举行的高性能芯片峰会Hot Chips上介绍了他们的数据流处理器产品DPU(Dataflow Processing Unit),加速神经网络训练,号称速度是GPU的1000x,训练GoogleNet 42万图像/秒。同时,DPU使用了不含CPU的架构,他们认为,数据流架构是有效训练高性能神经网络的唯一方式。

要建立起一家成功的芯片初创公司可不是件容易的事情,但有资本支持的Wave Computing,却在一块很小但很重要的市场——AI训练芯片——牢牢站稳了脚跟,至少目前为止。
距离成立之初已经过去7年,目前该公司最新的DPU多核架构早先体验项目终于开放,也让Wave在聚焦深度学习数据流处理架构上更进一步。
日前,Wave Computing的CTO以及DPU(Dataflow Processing Unit)首席架构师Dr. Chris Nicol,在高性能芯片产业峰会Hot Chips上表示,他们的产品DPU在加速神经网络训练上能够超越GPU 1000x——实在是很大胆的宣言,考虑到GPU在目前深度学习训练市场的地位——Nicol相信早期用户试用后能够证实他们对DPU的这一宣称。
Wave Computing的观点是,数据流架构是有效训练高性能神经网络的唯一方式。CPU在他们的系统中完全没有出现。
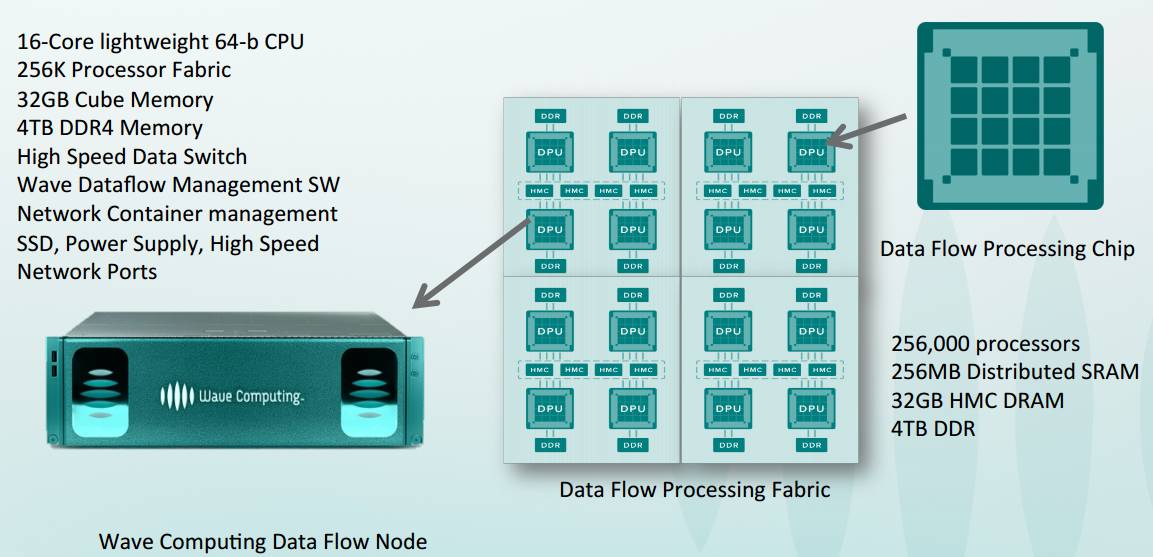
2016年,Wave Computing 的 DPU刚刚揭幕时的设计信息

今年Hot Chips大会上揭幕的架构和设计资料:每秒Teraops峰值181,图中展示的是8-bit运算,但也可以做16、24、32甚至64位。有16,000个处理元件和超过8,00个算术单元,运行功率平均6.7 GHz。采用独特的自定时机制,使用全局异步/本地同步定时同步机制来解决各种处理元件之间定时的问题。
Nicol在将目标问题应用于多核(manycore)策略方面有丰富的经验。他帮助建立了澳大利亚研发机构NICTA,后者的重点是嵌入式多核系统和软件,Nicol还在澳大利亚建立了贝尔实验室研究所,与人共同开发了第一个多处理器SoC。虽然深度学习训练不是嵌入式计算问题,但Nicol表示,大规模训练走出数据中心的那天终将到来。Wave还没有开发符合这一思路的系统,但是Nicol的背景和声明表明,Wave Computing公司可能展开研究,更多地推动神经网络训练走向边缘。这也是Wave的DPU在未来可能具有潜力的地方。
DPU拥有16,000个处理元件,超过8,000个算术单元——再次强调,没有CPU在这里协调。所有的核都以6.7GHz运行(平均),使用粗粒度可重构架构——这个设计与其他深度学习硬件初创公司培育的产品大为不同。DPU有独特的自定时机制(self-timing mechanism),当没有数据通过时,DPU进入睡眠状态。
DPU可以看做一种混合FPGA和多核处理器,能处理数千个元素的数据流图的静态调度。有关板上设计和核与核之间的通信,具体看下面。


DPU板上设计(上)与核与核之间的通信策略(下)
在接受 The Next Platform采访时,Nicol说:“现在的异构计算有一个问题,主机或控制器总是在CPU上运行,加速器就听之任之。你的runtime API在CPU上运行,slave必须等CPU告诉它该做什么它才做什么。我们想要彻底改变这一点。”
Nicol指出,加速器架构(特别是GPU)有两个问题,一是加载新的内核时有延迟,二是为了解决第一个问题,使用MCU在运行时将程序移入移出。程序本身决定何时发生这种情况——程序与MCU通信,DMA将程序传入和传出芯片,并控制其传播信号。芯片上还有一个程序缓存。最终的结果是,没有CPU的架构在一个offload model中有更多的性能收益。
像这样的技术堆叠起来会实现非常厉害的架构。当然,为了应对没有CPU和其他灵活性问题,这还需要很多的修改,因此也使得DPU的性能和效率基准值得关注。
硬件之外,软件也值得关注,特别是对于新的架构,软件如何运作以及用户如何进行交互也是不能不说的问题。对此,Nicols说:“深度学习实际上是一个在深度学习软件之上编程的数据流图,在像我们这样的处理器上运行,可以在运行时组装数据流图。”
Nicols说:“工作流生成数据流图来训练网络;例如,在运行(runtime)时,我们从TensorFlow获取数据流图,并在runtime直接将其转换,在没有CPU的情况下执行,并映射到数据流芯片上。”

Inception V4在Wave编译器处理示意图
“这是一个粗粒度的可重构阵列,它类似于空间计算(spatial computing)。”Nicol说:“当程序在多核处理器上运行时,仍然需要分区,这也是在芯片有这么多核的问题所在。OpenCL不是解决之道。”Wave有自己的空间编译器。在他们紧密耦合处理器架构上,processor直接通信(相比使用register)速度更快。
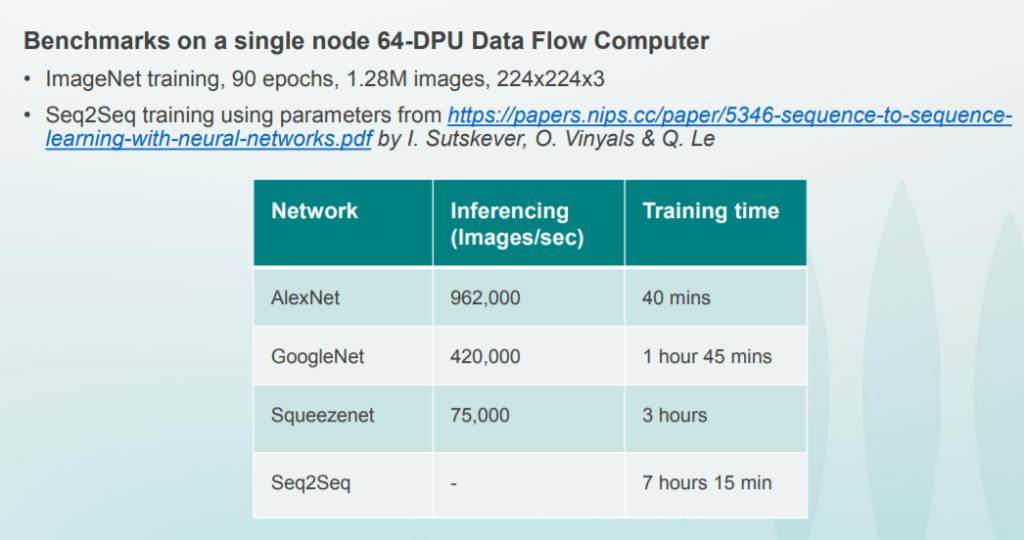
Wave系统的早期试用数据
了解更多&编译来源:
https://www.nextplatform.com/2017/08/23/first-depth-view-wave-computings-dpu-architecture-systems/





