MIT韩松组推出升级版AutoML方法,一个网络适配所有硬件
新智元报道
新智元报道
来源:ArXiv
编辑:元子
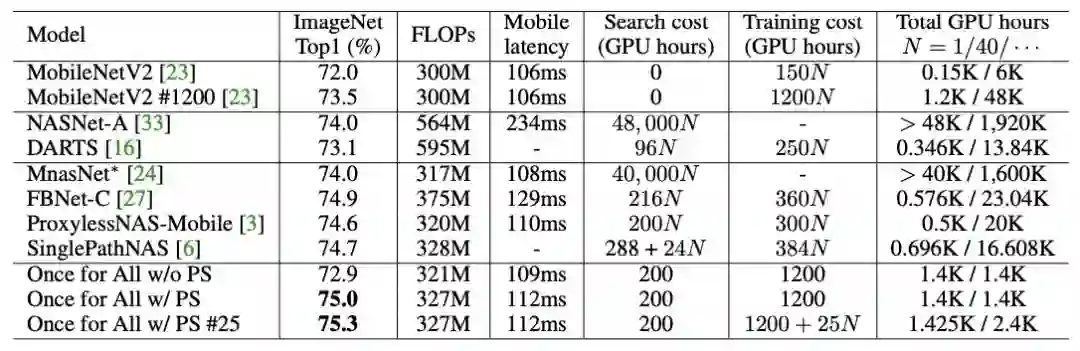
【新智元导读】麻省理工学院韩松团队推出了“一劳永逸”(OFA)网络,该网络与ImageNet上最先进的AutoML方法达到相同或更高的水平精度,OFA所需GPU小时数比ProxylessNAS少14倍,GPU小时数比FBNet少16倍,GPU小时数比MnasNet少1142倍。部署方案越多,对NAS的节省就越多。
万能,多么让人心动的一个词。人类总是追求一个放之四海而皆准的解决方案,一劳永逸的解决所有问题。
事实上,随着人工智能不知不觉的进入生活、工作的方方面面,一个问题逐步浮出水面。
起初,人工智能模型可以针对不同硬件进行定制,从而达到非常好的性能表现。但是电子产品基本上每年至少更新一代,旧有的硬件产品却不会紧接着被淘汰。5年前的iPhone 6s依然有大批使用者,和拥有神经网络加速器的iPhone X Max并存于世。
人工智能模型需要一个“万能模板”,可以针对不同的硬件自动进行适配,而非人工为不同硬件进行定制。
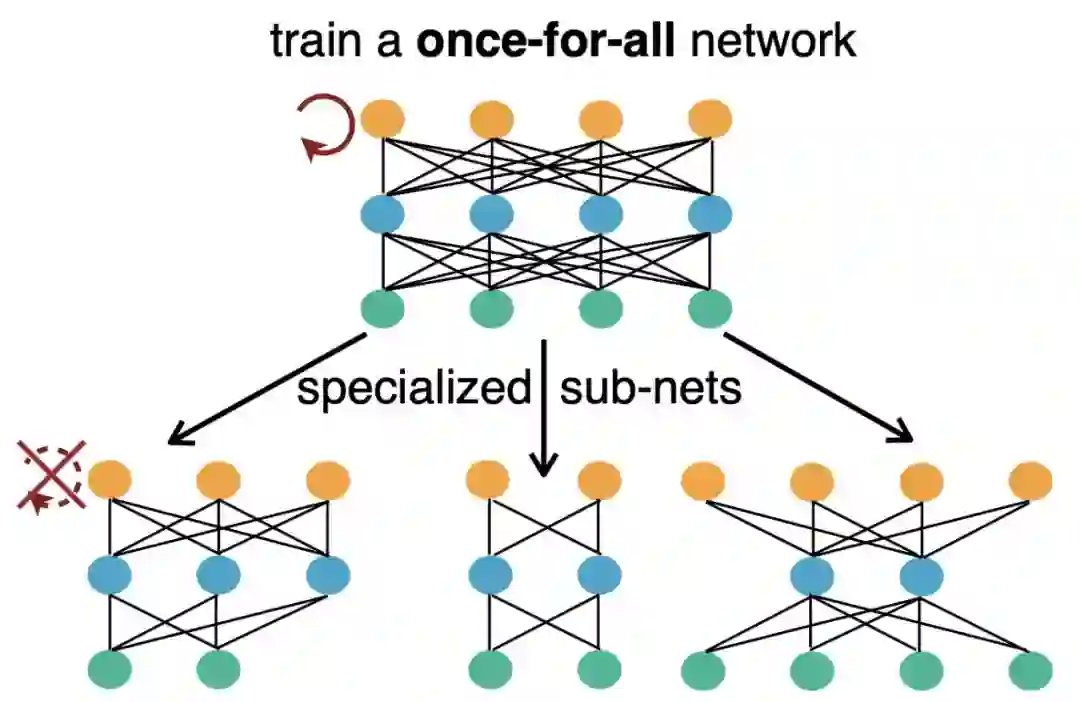
目前比较流行的做法,要么手动设计,要么使用AutoML来搜索专门的神经网络,并针对每种情况从头开始训练,缺点很明显,贵,且麻烦。
去年,MIT韩松团队提出了 AutoML 模型压缩(AutoML for Model Compression,简称 AMC),利用强化学习来提供模型压缩策略。

论文地址:
https://arxiv.org/pdf/1802.03494.pdf
这种基于学习的压缩策略优于传统的基于规则的压缩策略,具有更高的压缩比,在更好地保持准确性的同时节省了人力。
今年,韩松团队再次提出一劳永逸OFA(Once for All),这是一种将模型训练与架构搜索分离的新方法,用于高效的神经网络设计,以处理许多部署场景。
具体的实现原理是这样:研究人员首先将目标定义为获得网络的权重,从而使得每个子网仍然可以达到与使用相同架构配置(深度,宽度,内核大小和分辨率)独立训练的网络相同的准确度。
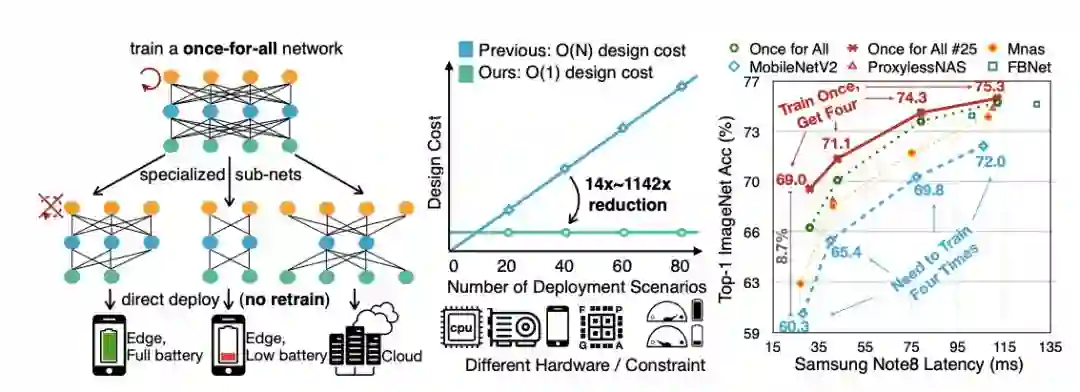
相比现有的网络,OFA网络实现了一项重大创新:让AI直接搜索最佳子网成为可能,从此研究人员不需要为每个场景设计和训练模型。与ImageNet上最先进的AutoML方法达到相同或更高的水平精度,训练时间显著加快,支持更大的搜索空间(10^19子网)。
为了更有效的训练一个巨大的的OFA网络,防止许多子网络之间的干扰,研究人员提出了一种渐进式收缩算法,该算法能够训练一次性网络以支持超过10^19个子网络,同时保持与独立训练的网络相同的精度,从而节省非经常性工程(NRE)成本。
在各种硬件平台(移动/CPU/GPU)和效率限制上的广泛实验表明,OFA始终达到与SOTA神经架构搜索(NAS)方法相同(或更好)的ImageNet精度。
值得注意的是,在处理多个部署方案时,OFA比NAS快几个数量级(N)。N=40时,OFA所需GPU小时数比ProxylessNAS少14倍,GPU小时数比FBNet少16倍,GPU小时数比MnasNet少1,142倍。部署方案越多,对NAS的节省就越多。
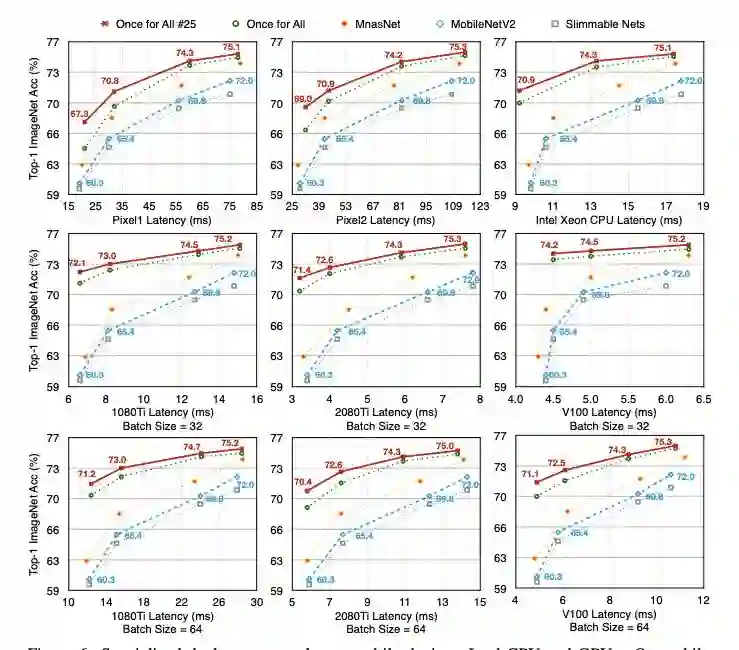
与采用搜索算法查找子网的大多数AutoML方法不同,研究人员从OFA网络中随机抽取子网的子集来构建其准确性和延迟表。这使他们能够在给定特定硬件平台的情况下直接查询表以找到相应的子网。查询表的成本可以忽略不计,从而避免了其他方法中总成本的线性增长。
但所有的“万能”产品都有一个通病,那就是成本高,OFA一次性训练成本大约是定制模型的12倍。不过研究人员表示,通过额外的部署方案可以降低这种高昂的一次性成本。
正如托尔金巨著指环王中,至尊魔戒背面蚀刻的铭文一样:“一个戒指统治他们,一个戒指找到他们,一个戒指把他们全部和黑暗绑在绑在阴影所在的魔多。”
“一劳永逸”网络,是否会成为至尊网络呢?
论文地址:
https://arxiv.org/pdf/1908.09791.pdf



