国家千人计划教授任奎:数据安全的现状与趋势(全文)
宅客频道编者按:数据安全的问题存在于数据的整个生命周期,从数据采集、流转、传输到数据使用,其中尤为受到关注的是数据的机密性、完整性以及可用性。在6月30日举办的CCF-GAIR智能安全专场中,浙江大学网络空间安全研究中心主任,国家千人计划特聘教授,IEEE Fellow 任奎带来了《数据安全:现状与趋势》的演讲。
任奎本硕毕业于浙江大学,2007年于美国伍斯特理工学院获博士学位,2017年成为纽约州立大学冠名教授。任奎教授主要从事云安全、物联网安全与隐私保护等领域的前沿研究工作。
任奎教授2016年当选IEEE会士, 2017年当选ACM杰出科学家。他获得了IEEE通信分会安全技术委员会技术成就奖 、纽约州立大学校长杰出研究奖,纽约州立大学布法罗分校杰出学者奖 、纽约州立大学布法罗分校工程学院年度资深学者奖 、美国国家自然科学基金的青年成就奖 、伊利诺伊理工学院卓越研究奖。任奎教授发表了200余篇同行评议的期刊与会议文章,获得了包括IEEE ICDCS’17、IWQoS’17,ICNP’11在内的多篇最佳论文奖。他的H-Index为58,文章总引用次数超过23000,单篇论文引用次数超过2000。
2018 全球人工智能与机器人峰会(CCF-GAIR)于6月29日在深圳召开。本次大会共吸引超过2500余位 AI 业界人士参会,其中包含来自全球的 140 位在人工智能领域享有盛誉的顶级嘉宾。
以下是任奎在现场的演讲,宅客频道做了不改变原意的编辑整理。

我是浙江大学的任奎,今天很高兴能和大家分享在数据安全上我们的一些思考。
显然数据安全的问题存在于数据的整个生命周期,从数据采集、流转和传输到数据使用。通常情况下我们会在数据生命周期的各个环节里关注数据的机密性,完整性以及可用性。
首先在机密性方面,互联网出现之初数据泄露事件就不断发生,且愈演愈烈。比如去年美国最大的一家信用卡公司之一Equifax,泄露了高达1.47亿条的用户数据。其中不仅包括姓名,还涉及到在美国是非常私密的社保卡信息,以及信用卡信息等。除了这种直接的数据泄露,还有进一步的隐私泄露,比如今年4月份,德国邮政出售选民信息,这些选民信息看起来没有太多私人的信息,但是根据这些信息我们可以用人工智能的模型进一步挖掘,得到很多政治倾向,可能给选举结果带来明显影响。也就是说,数据的机密性一方面是数据的直接泄露,另一方面是在直接泄露基础上进一步做隐私的挖掘。
从技术手段的角度看,在不妨碍数据可使用性的条件下,怎样保障数据的机密性?
第一是数据加密技术,第二是访问控制策略技术,第三是隐私保护技术。
具体来说,数据加密技术在最近几年研究较多,从学术界的角度而言,主要谈到的有可搜索加密,在安全多方计算的角度,近年学术界慢慢看到了工业界的现实和需求,不少学术界成果也开始慢慢往工业界迁移。
在访问控制策略方面,目前有很多基于生物特征的访问控制策略,指纹、脸部识别等技术飞速发展,也包括基于属性、角色的访问控制策略越来越成熟,基于属性加密的技术越来越被大家认可,开始真正应用到访问策略控制里面去。
在隐私保护技术方面,过去十几年最重要技术之一的就是差分隐私保护。
具体来讲,可搜索加密是什么?
比如怎么利用云端数据的机密框架,当用户把数据外包到云上,这个云跟它不在一个信任域里面,所以希望对数据库加密起来,如此一来不论云是主动还是被动的,用户想看到数据就是密文。
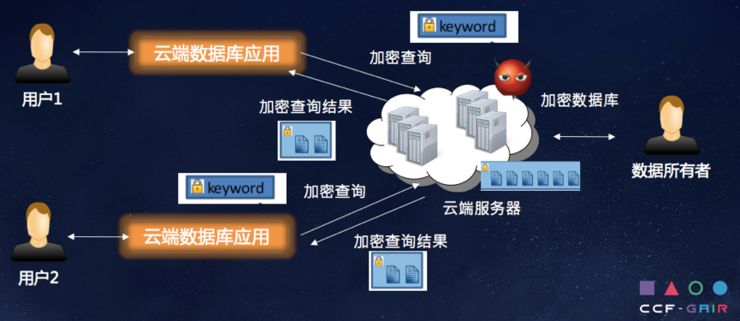

另外是基于属性的访问控制。我觉得在密码学领域里面,ABE是一个相对新的工具,这个工具的弊端是在目前情况下,文件存储的大小、角度都会有一些相对较大,但它的优势是把用户抽象成一堆属性的结合,当上传文件的时候,给这个文件属性,就会有一个访问控制策略,当开始去访问控制策略的时候,会把用户属性和文件属性以及访问控制策略的决策数共同计算,来查看用户是否有能力接触这个数据文件,但这一数据文件本身可以和加密结合起来,基于属性的访问策略可以实现更复杂的访问策略。
还有一个例子是差分隐私,目前谷歌和iOS都开始使用这一技术。收集整体数据的时候会暴露用户的所有隐私,那是否可以先将个人数据做一些扰动,对敏感数据做随机响应。
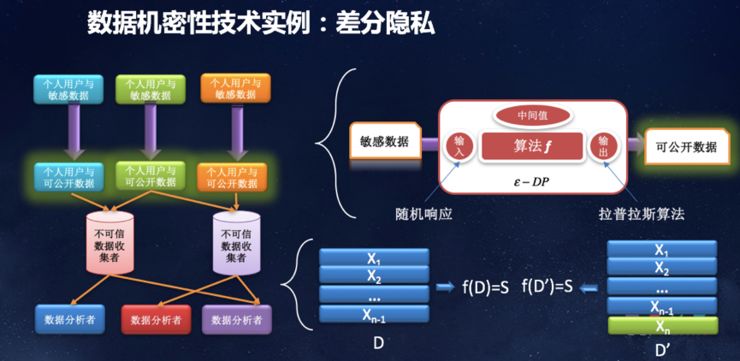
为什么差分隐私保护是很好的工具?它给予了一个定量的方法去衡量你把隐私能够保护得比较好,对任意两个只相差一条数据记录的数据库,这两个数据库在面对相同查询返回结果的时候,差距不会太大。这是非常好的一件事情,可以有一个定量的方法保护隐私强度。
在数据完整性方面,面临的威胁是数据篡改。任何不被授权的数据改动都是不被允许的,会影响数据的完整性。这里有一个例子,互联网诈骗团伙通过修改软件代码篡改数据,然后把模拟操盘的获利操作截图发布到社交平台欺骗大家。
数据完整性需求存在于数据采集传输、数据存储和数据使用等多个阶段。在数据采集和传输阶段,可以用数据分装和签名技术防止数据篡改;传输时候有一些丢包恢复的机制,即便有一些包被丢掉了,不用同传也可以有本地数据、数据审计;在数据使用的时候怎么保证完整性,可验证计算等等手段来进行保护。

数字签名大家都知道,首先数据的上传者拥有数据文件,有哈希算法,然后进行签名,得到文件和签名一起的信息。这一信息经过传输后,在接受端如果接收到的文件被篡改了,是没办法成功比对的,相当于不管你是对数据本身做的修改,或者对签名做的修改,最终导致的结果就是不匹配,也就意味着数据在传输过程中或者采集过程中被篡改了。
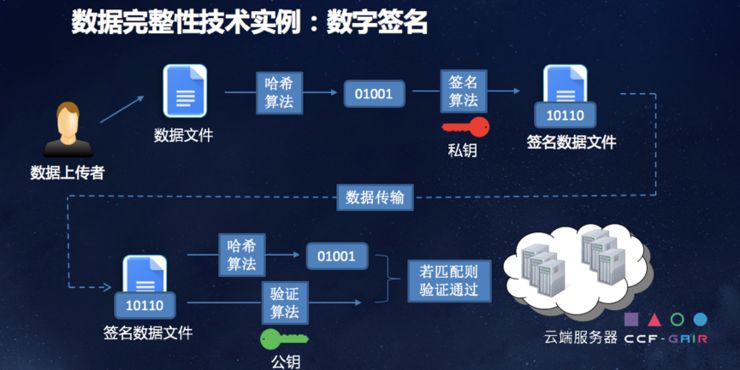
这是在有数据进行比对的情况,还有一种在云存储的情况。
当个人用户或者企业用户没有本地数据时候,比如一开始就把数据放在云端,此时的云端数据是否有被篡改过,有没有被丢失,数据完整性如何得到检验?就要做云的存储数据比对,上传到云端之前,可以把数据和相关的元素放在云里面。在未来的时间节点上,想要检测这些数据在云里是不是被正确存储就进行随机抽样。这样计算量和带宽要求可以控制在合理范围之内,并拿回来进行验证。以此做到在没有本地数据存储、所有数据都在云端的情况下,依然可以在未来时不时的检测我的数据是不是被云丢失或者被云篡改了。
当然这个云不一定是故意的,云可能本身被入侵了,这里面更具体的问题还在于当我的数据有动态的更新怎么办,当用户有不停的新用户和旧用户的动态变化怎么办,所以云数据审计的技术还一直在不停的开发和完善当中。
讲一下安全外包计算。在当前情况下,一方面是个人和中小企业用户,面对云,计算任务可以是非常广阔的,可搜索加密就是计算任务,我也可以让它帮我进行一些非常大规模的优化运算,我可以让云做很多不同类型的计算,这时候就存在一个问题,如果我在本地没有那么多计算资源和存储资源应该怎么办?
很显然要有一个安全外包计算的手段来做这样一件事,我想让云帮我处理我的数据,计算我的数据,但是我不想云知道数据的内容,也不想让云知道数据计算的结果,还要保证云能够对我的数据进行完整正确的计算,并且结果返还给我的时候,我能够验证。
可以想象,做这些事情的同时也要付出额外的代价,但代价不能太大,如果太大的话就不如在本地进行。所以这些在个人用户和云之间的不对称性,以及怎样适应这个不对称性,成了安全外包计算上非常重要的设计考虑。
云从多个用户那收集不同的数据,放在一起进行计算,比如说我有一个网贷公司,这个公司从别的网贷公司或者其他银行收集过来这些数据,要将数据放在一块进行计算来决定某一个或者某一类用户的信用分数。这种情况下每个数据公司对自己数据的隐私保护都是有要求的,相互之间可能是冲突的,我不信任你,你不信任我,这种情况怎么解决?
我前阵子去硅谷访问,有一个初创公司就是做风控的安全计算。其实大家拥有各自数据的时候,相互之间并不信任,但是数据只有联合起来才能产生更大的价值。当前的解决方案很多时候完全是非技术的,比如大家共同信任一家公司,就都把数据放到那一家公司去,原因是这家公司在市场上存在了几十年,口碑较好。大家想要数据时候,都问那家公司要。
这显然是非技术的手段,这家公司并一定在保护数据安全方面有技术能力,事实上这是一家市场调查公司,并不是一个技术公司。计算任务需要多方多步操作的时候,数据的完整性和正确性就变得非常复杂,如何从技术上保证数据完整性就变得非常有挑战性。
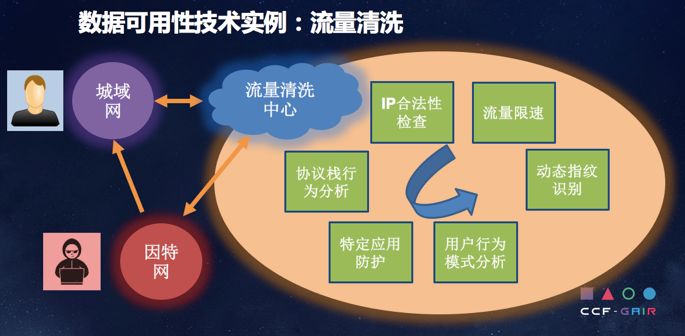
在数据可用性方面,面临的威胁主要是DDos攻击,防御技术手段主要是本地防护、云端防护和源端防护。大家都在多管齐下,把这些攻击带来的坏的影响控制在最低范围内。
当然一个重要的技术就是流量清洗,不管是域名解析还是其他方法,在智能防护上他会把你的流量进行分析,通过IP合法性检查、流量限速、动态指纹识别、特定应用防护等等,去做DDos防护,这也是数据可用性实例。
人工智能的发展使数据安全的保障有了更强有力的工具,这是好的方面。不好的方面,人工智能也可以被攻击者恶意利用产生更严重的问题。
分别举几个例子,第一个就是人工智能算法可以用来做精确高效的信息过滤,对谷歌来说,谷歌的邮箱可以过滤高达99.9%的垃圾邮件,这就是利用人工智能算法来做过滤。目前为止垃圾邮件还是非常严重的问题,我大概常用的三个邮箱,每个邮箱每天还是有很多垃圾邮件,并不能很准确过滤,人工智能算法可以帮助我们在这方面取得更重要的突破。
还有一个例子是安全多样的身份认证,人工智能算法能够帮助我们更精确,更不容易被欺骗,比如人脸识别。当然人工智能算法本身也可以做人脸识别的欺骗,这永远是双刃剑。
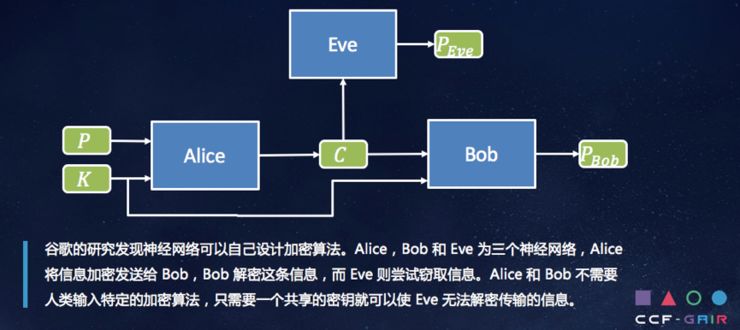
人工智能还能生成新的加密算法,Alice和Bob和Eve是三个神经网络,A和B之间共享一个Key,但是没有一个算法,这种情况下经过多轮的训练之后,A和B之间可以用它们自己产生的算法来对数据进行加密,E却不能解密。就是我只是让A和B之间有了一个密钥而已,并没有事先加载任何具体加密算法。这就是在人工智能年代,可以利用AI算法来做很多很好的事情。
Kogan 随后将数据卖给了剑桥分析(这一行为违背了 Facebook 的安全协议以及小程序的用户协议)。剑桥分析利用5000万 Facebook 用户数据建立模型,找出“低开放心性,高情绪不稳定性”的选民针对性地投放广告,试图影响2016年美国大选结果。
当然我只是说试图影响,不能说确实影响了。所以说在人工智能年代,AI算法被用来去挖掘用户的隐私,用户隐私更加难以被保障,尤其是大数据年代,你可以在不同的数据源里把数据提取出来,带来的负面的效应也非常之大。
人工智能算法也可以用来生成以假乱真的音频和视频,第一个例子是音频,Adobo公司研发的语音编辑软件Voco,只用一个20分钟的录音进行训练,就可以生成出你任意的声音内容。另外德国慕尼黑工业大学的学者在研究中可以将视频中的人脸做出任何输入的表情,AI可以用来产生你从来没有说过的话,以假乱真,你没做过的动作和语音配合起来,已经非常接近真实。
还有大大失效的CAPTCHA检测,为了检测你是人还是机器,给你一些图象,图象对人理解是容易的,但是对机器是比较难的。去年12月份在科学杂志上发表的文章称一家公司使用了一个RCN网络,对单一的文本CAPTCHA可以达到90%的确认率,而且训练不需要大量的数据集。
另外,北京大学的学者提出基于生成式对抗网络GAN的恶意软件生成器MalGan,经过训练之后可以生成杀毒软件难以检测的对抗样本。这都是人工智能给你带来坏的方面。
第三个方面我想讲AI自身数据安全的问题,前面是人工智能可以帮助我们,人工智能可以做恶,这里是人工智能自身的安全问题。主要包括三个方面的安全:一个是训练数据安全,一个是模型参数安全,一个是AI应用安全。
在训练数据安全方面,训练数据有时候是我们花大价钱得来的,比如说人脸数据以及一些医学应用数据,如人体的MRI,是以非常大的代价得来的。如果这个训练数据被偷走了,成本浪费是一个方面,另一方面涉及到用户隐私泄露。比如人脸数据等。
还有模型参数安全,花了很大代价训练出来的模型,模型的价值在于参数,如果被你轻易学走拿去了,对企业来说是巨大的损失。
还有AI应用安全,在这个图里,对人眼来看这还是一个STOP的标签,但是一些算法认不出,那在智能驾驶来说就是很致命的问题。

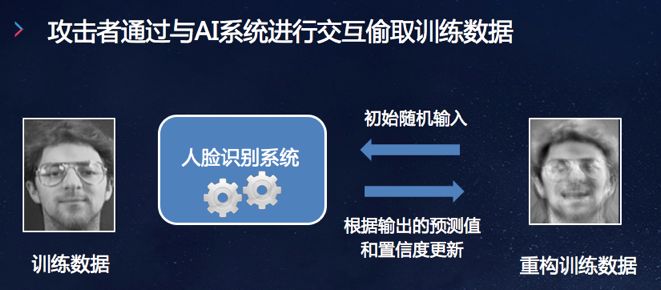
左边的人脸数据通过人脸识别系统,给它一个随机输入,然后进行不停的更新,经过多轮训练之后可以拿到右边的数据,最终可以把右边的数据给拿出来,你看到对于人脸来说,我看到右边这张脸,已经可以看出来他是谁了。
训练数据安全还有一种,当我做合作学习的时候,大家都是上传本地参数,可以保护本地隐私,最新研究发现,在很多情况下仍然有可能造成本地的训练数据泄露。
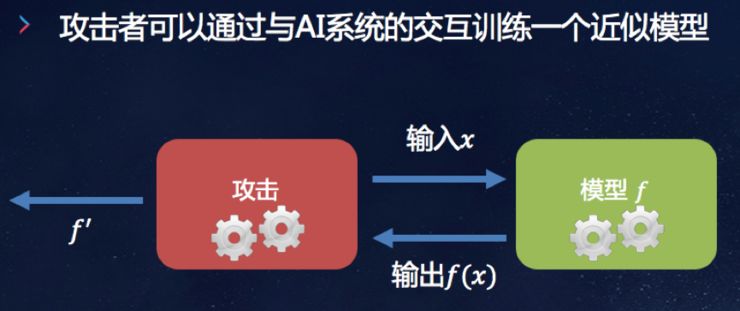
模型参数安全,攻击者可以与AI系统进行交互,这个模型如果是线性模型的话,就把它的参数求到,如果是非线性的话,利用梯度学习重新获得近似的学习,可以得到99%的准确率,跟原先训练好的模型,可以把参数给拿到。
如果我已经知道模型参数了,甚至可以把模型的超参数也可以拿到,参数是你训练出来的,但是超参数不是不能从数据里得到,而是人工指定的,人工指定的值则是大量的摸索实践经验得来的。这就表明,参数和超参数都有可能被窃取。


最后想讲讲数据安全的新规范。
合规和新的数据法律给学术界和工业界都提出了非常多的挑战,从我们国家来说,从网络安全法到个人信息和重要数据评估安全到信息安全技术数据评估指南,这些都是给你一些法律的框架,你必须要合规。
其实对工业界来说,特别是现在有些系统要求使用国产密码,在系统开发的时候,你必须要具备这些技术。
另一方面,一些走在前沿的隐私保护的东西,给技术上提出很多新的挑战,如果一旦不合规的话,给企业带来的法律义务非常的重。比如说GDPR,从今年的5月25号已经正式开始贯彻了,GDPR规定了遗忘权,一个人的数据应该可以被遗忘在网上。但这是很困难的事情,你的数据一旦被网站上备份过,不同的服务器上流转过,怎么保证这些信息在所有的地方都被删掉了呢?
包括AI模型可解释性,我同意张钹院士的说法,AI有很长的路要走,比如你要取代一个医生,你要看一个CT片子,医生说它不是肿瘤,医生承担责任。机器说不是肿瘤,可以解释吗?出了问题怎么办? 因为现在很多AI模型没有可解释性,如果我要求你一定要有可解释性,怎么办?这也在技术上有非常大的挑战,当然还有很多其他挑战像可迁移性。
AI给我们提出了很多挑战,新的法律法规也给我们从技术上和合规上提出很多新的挑战,所以数据安全依然任重而道远,我的分享就到这,谢谢大家。
问答环节:
宅客频道:您在演讲中提到了AI自身数据安全的三个问题,包括训练数据安全,模型参数安全,以及AI应用安全。针对这三个方面的攻击已有实例了吗?还是处于实验室模拟攻击阶段?以及有何方式防御。
任奎:针对这三个方面的攻击大多处于实验室模拟攻击阶段,还未出现影响恶劣的相关实例,但这些攻击仍应受到高度重视。其原因有二:一是演讲中所提到的窃取训练数据和模型参数的攻击较为隐蔽,不易被现有的检测系统发现。因而这类攻击可能已在现实中存在并造成严重损失,只是尚未被发现报道。二是现有攻击手段已经可以被恶意使用于现有的AI系统及AI模型平台上。例如,演讲中提到的爱荷华大学团队的关于模型超参数窃取的工作,相关实验是在亚马逊云计算平台(AWS)上进行的。实验表明他们所提出的攻击可以准确地窃取存储在AWS上的机器学习模型的超参数 [1]。另外,伯克利团队在STOP 标志上贴上设计好的贴纸,导致 YOLO自动驾驶识别系统无法识别该STOP标志 [2]。在自动驾驶汽车的试行至正式投入使用的过程中,这类攻击如果被恶意使用,那后果将不堪设想。
目前来看,针对于前面提到的这些攻击,有效的防御措施还比较少。如有关训练数据,模型参数的窃取攻击一般比较隐蔽,现有的系统平台难以及时发现并处理。针对这个问题,一个潜在的防御手段是利用差分隐私技术,对模型的部分输出(如置信值)进行扰动,以防攻击者获取到更多的信息。针对AI应用安全中的对抗样本问题,近些年各类防御方法不断涌现,但其中很多都已被新的攻击算法攻破。例如,在ICLR2018上发表的8个防御工作中,7个已被新出现的攻击算法攻破 [3]。因此,在研究出有效的对抗样本防御系统前,我们可能还有很长的路要走。
参考文献:
[1] Wang, Binghui, and Neil Zhenqiang Gong. "Stealing hyperparameters in machine learning." IEEE SAP 2019
[2] Evtimov, Ivan, et al. "Robust Physical-World Attacks on Deep Learning Models." arXiv preprint arXiv:1707.08945 1 (2017).
[3] Athalye, Anish, Nicholas Carlini, and David Wagner. "Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples." arXiv preprint arXiv:1802.00420 (2018).
宅客频道:在您看来,目前国外安全领域学术界和产业界结合趋势是什么,以及是否有值得国内学习的地方?(可结合具体案例)
任奎:网络空间安全是新信息时代的全球性问题,部分发达国家对这一问题给予了广泛关注与深入探讨。以美国为例,学术界和产业界有着较为成熟的分工合作体系与运行机制,共同推动安全领域的技术发展和创新。一方面,从美国各大高校范围来看,该方面有着诸多典型案例。比如,斯坦福大学将学科研与人才培养体制与政府和企业需求直接对接,与来自硅谷的企业实现了深层次的融合。加州大学伯克利分校每年举行业界交流会,使实验室每位成员与业界人员交流。当学生在研究的问题上遇到了瓶颈,教授会让学生短期进入工业界实习,以了解研究方向和研究目的。另一方面,美国产业界为了自身可持续性地发展,非常注重和学术界的联系。为了加强该联系,多种运营模式应运而生。如在企业社团模式下,研究社团负责收集企业的需求并反馈到学术界,大学教授则可以根据自己的研究兴趣匹配相应项目和经费。另外,还存在较为新兴的企业联合资助模式,若干公司联合起来直接定向资助某个大学的实验室,实现学校与企业的互惠互利。
最近几年,安全方向国内学术界与产业界之间的联系态势活跃。近期浙江大学阿里巴巴集团联合成立的“AZFT网络空间安全实验室” 致力于推动‘产学研用’的一体化发展,也引发了学术界和产业界的广泛关注。
参考文献:http://blog.sciencenet.cn/blog-414166-795432.html
宅客频道:您刚刚有提到数据遗忘权这一问题,针对这一权利向来有不同声音,首先是所有权,大数据时代海量数据的所有权属于谁?如果用户拥有数据遗忘权又怎么保证相应数据完全被删除?是否有相应技术可以解决这一问题?您是如何看待的。
任奎:在大数据时代,所有的数据所有权应当属于用户。海量数据的采集和使用均应获得来自用户的授权。数据遗忘权并不是一个新的概念。欧盟委员会早在2012年就提议,应当在互联网上为人们赋予“被遗忘权” ,即人们有权利要求移除自己负面或过时的个人信息搜寻结果。今年6月28日,美国加州签署了AB375 数据隐私法案,规定掌握用户数据超过5万的公司必须允许用户查阅和删除自己被收集的数据。然而在实际中是很难保证数据完全被删除的,主要原因在于数据可以被复制和转移,即使在某个指定公司的服务器中被删除了,但不能保证数据没有被存其他地方。目前在技术层面上还没有较好的解决方案,只能通过从法律层面上对侵犯数据遗忘权的行为进行惩罚来保障用户的权利。
参考文献:http://www.it007.org/nd.jsp?id=48
http://www.360doc.com/content/16/1015/14/21733879_598618933.shtml
戳蓝字查看更多精彩内容 探索篇 ▼ 真相篇 ▼ “老婆,开门”,隔壁老王带来的恐惧 人物篇 ▼ 更多精彩正在整理中…… |
---
“喜欢就赶紧关注我们”
宅客『Letshome』
雷锋网旗下业界报道公众号。
专注先锋科技领域,讲述黑客背后的故事。
长按下图二维码并识别关注



