点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
影视作品里许多特效场景都需要借助绿幕完成,在技术不过硬的时候,常会发生「五毛特效」的惨案。来自谷歌的研究者发明了一种 Bling Bling 的「LED 蛋」3D 人体捕获装置:先把表演者请进「蛋」里一阵猛拍,然后进行重建和渲染,就能任意切换人物所处的环境,连光照、阴影都可以根据环境进行调整,简直完美。
![]()
「灯光」在影视作品、游戏和虚拟环境中的作用至关重要——有时候它是决定一个场景表演质量的关键,这个很容易理解。
比如某些古装剧的某些场景会让人非常出戏,除了演员的演技太差之外,很有可能是因为光效不太自然,盯着电视机屏幕时,你甚至能想象出来演员头顶的摄影棚。
![]()
在影视制作过程中,想要复制完美的光效仍然是个难题。
随着计算机视觉技术的演进,计算机已经能够比较「自然」地还原人脸形状、皮肤纹路,但是在模拟灯光条件这一块还是缺乏写实感。
谷歌这个全新的系统可以完美还原人物周围的光影效果,使得合成的影像看起来更加逼真。
通过与 AR 等技术的融合,该系统可以无缝地将捕捉到的人体融合到现实世界中或电影、游戏等中的数字场景。
它可能会彻底变革 3D 捕获技术领域。
![]()
![]()
这个「LED 蛋」实际上名为 Relightables,它可以捕捉人身上的反射信息,即光线与皮肤的交互,这是数字 3D 人物看起来是否逼真的关键。
之前的研究要么使用平面照明,要么需要计算机生成人物。
谷歌的系统不仅能捕捉人身上的反射信息,还能记录人在 3D 环境中自由移动时的信息。
因此,该系统能够在任意环境中重新调整人物的光照。
![]()
图 1:
Relightables 系统,这个体积捕获设置将传统的计算机视觉流程与深度学习的最新进展相结合,可以在任意环境中重现高质量模型。
论文地址:https://dl.acm.org/citation.cfm?id=3356571
在之前的研究中,相机只从单一的视角和光照条件下记录人体。但谷歌的系统可以让用户在任意视角和条件下查看被记录的人,
不需要绿幕来创建特效
,可以实现更加灵活的照明条件。
在 11 月 17 日-20 日于澳大利亚举行的 ACM SIGGRAPH 亚洲展览会上,谷歌公开展示了 Relightables 系统。
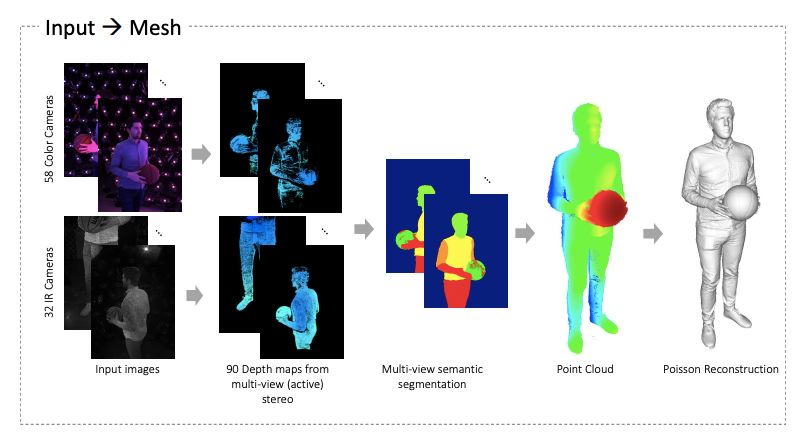
谷歌的 Relightables 系统工作流程可分为三个部分:
捕捉、重建和渲染
。首先,研究者设计了一个全新的主动深度深度传感器,用来捕捉 12.4MP 的深度图。然后,他们展示了如何设计一个混合几何和机器学习重建流程来处理高分辨率输入并输出一个体积视频。接下来,他们利用在 60Hz 频率下获得的两种交替颜色梯度照明图像中的信息,为动态表演者生成时间上一致的光照图像。
![]()
图 8:
Relightables 流程(第一部分)。
首先,原始图像将用于重建高质量 3D 模型。
![]()
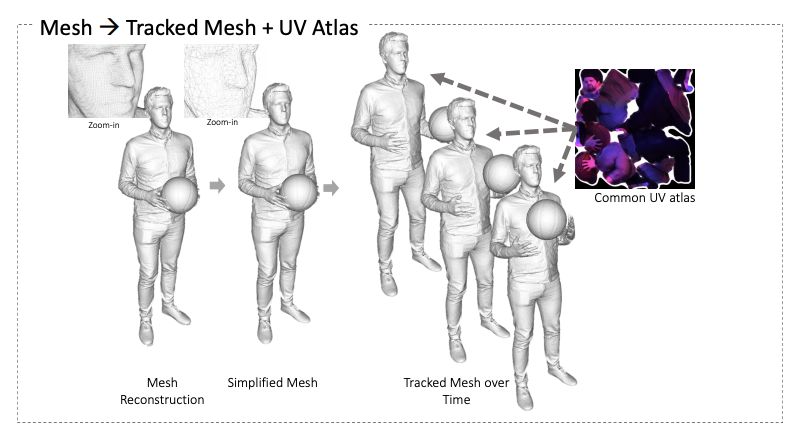
图 9:
Relightables 流程(第 2 部分)。
对该网格进行下采样,随时间推移跟踪并进行参数化。
![]()
图 10:
Relightables 流程(第 3 部分)。
最后,由两个梯度照明条件推断出反射率图。
该系统的核心依赖于一个包含多视角(主动)立体深度传感器的灯光球面舞台,舞台周围有 331 个可编程的灯以及 90 个高分辨率 12.4MP 重建相机。
![]()
捕捉人体所用的相机包含 32 个红外(IR)相机和 58 个 RGB 相机。
红外传感器提供准确、可信赖的 3D 数据,RGB 相机捕捉高质量几何法线贴图和纹理。
这些相机以 60Hz 的频率记录原始视频,研究者基于球面梯度照明交替使用两种不同的照明条件。
![]()
捕捉 600 帧(10 秒)的图像可以生成 650GB 的数据。
对于每个部分,研究者还记录了一个几何校正序列和一个 50 帧的 clean-plate 序列(即没有人的舞台)。
后者用于在实际表演过程中分割表演者。
接下来,研究者将数据上传到公共存储库中,第一个阶段是生成每个「机位」的深度图、分割图和 3D 网格 [Kazhdan 和 Hoppe 2013]。
他们用一个对齐算法来处理重建网格的序列,如此一来,长的子序列就可以共享常见的三角定位(triangulation)。
研究者提出了一种新的方法来解决关键帧的选择问题,将其转变为一个 MRF 推理问题来解决。
每个独特的三角定位都被参数化为普通的 2D 纹理空间,该空间可以和所有共享该三角定位的帧共享。
每个网格都有两个可用的梯度球形照明图像,从中可以生成反照率、法线、光泽度和环境光遮挡图。
这些图与标准渲染引擎兼容,可用在任何设定的光线条件下重新生成渲染图像。
整个系统是非常复杂的一个处理流程,研究者在论文中分析了系统的主要模块,从而验证提出的方法。
这些模块评估包括深度预测、图像分割、最优网格追踪、UV 参数化、纹理对齐等等,这一部分只简要展示几大模块的效果,更多的评估效果可参考原论文。
![]()
对于深度估计模块,图像展示了 SAD 和 VGG 在基于 RGB 图像做立体匹配的效果。
我们可以看到论文采用的 VGG 要提供更加平滑的结果。
研究者表示,从立体视角中抽取深度图像特征非常重要,他们表示尽管 VGG 这类深度模型非常强大,但它在牛仔裤等少纹理的区域效果还是不够好。
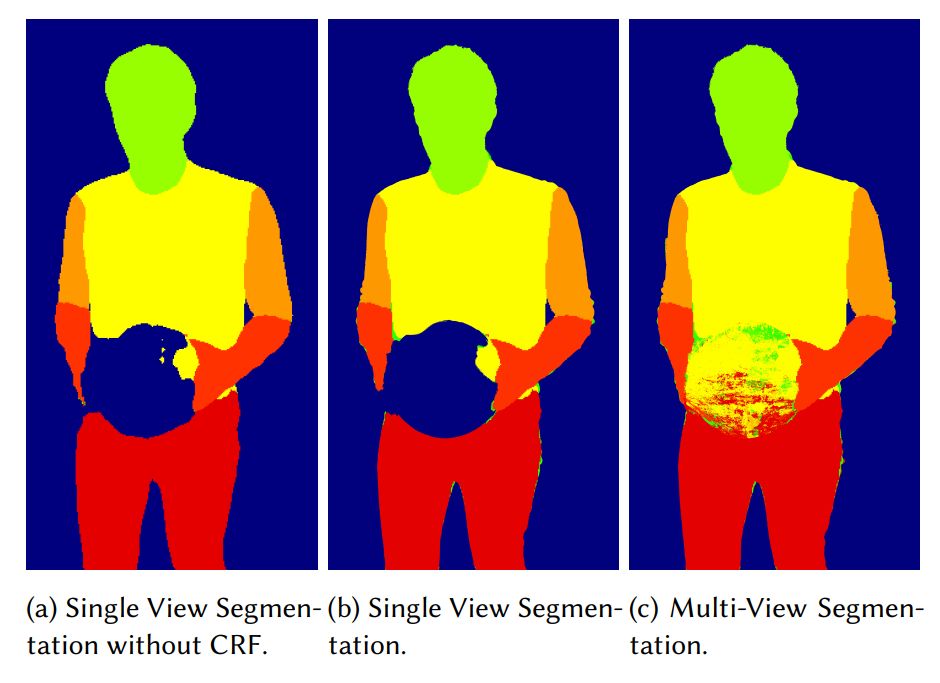
对于分割模块,研究者使用深度学习将先验知识都嵌入到 CRF 中,包括前景与背景的颜色和深度信息。
![]()
研究者的立体分割能够标注手上的篮球,这在单图像分割是做不到的。
![]()
相比 Collet 等人最佳的体积重建模型,研究者重现实现了很多模块。
如下所示为研究者提出的分割方法与 Collet 等人方法的对比。
其中研究者的方法能生成高质量的结果,而 Collet 也能生成非常令人满意的纹理网格,只不过 Collet 缺失了高频细节。
![]()
图 19:
研究者的重构结果与 Collet 方法的对比,由于更高的分辨率、深度相机和光度立体法估计,研究者的方法展示了更多的几何细节。
参考链接:https://techxplore.com/news/2019-11-google-captures-character-virtually-environment.html
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、检测分割识别、三维视觉、医学影像、GAN、自动驾驶、计算摄影、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
![]()
投稿也欢迎联系:simiter@126.com
![]()
长按关注计算机视觉life
推荐阅读
最全综述 | 医学图像处理
最全综述 | 图像分割算法
最全综述 | 图像目标检测
目标检测技术二十年综述
现在投身于计算机视觉是否明智?
如何激怒一个自动驾驶(无人驾驶、智能汽车)爱好者?
原来CNN是这样提取图像特征的。。。
计算机视觉方向简介 | 人体骨骼关键点检测综述
计算机视觉方向简介 | 人脸识别中的活体检测算法综述
计算机视觉方向简介 | 目标检测最新进展总结与展望
计算机视觉方向简介 | 人脸表情识别
计算机视觉方向简介 | 人脸颜值打分
计算机视觉方向简介 | 深度学习自动构图
计算机视觉方向简介 | 基于RGB-D的3D目标检测
计算机视觉方向简介 | 人体姿态估计
最新AI干货,我在看 ![]()