nlp中的Attention注意力机制+Transformer详解

本文以QA形式对自然语言处理中注意力机制(Attention)进行总结,并对Transformer进行深入解析。
目录
一、Attention机制剖析
1、为什么要引入Attention机制?
2、Attention机制有哪些?(怎么分类?)
3、Attention机制的计算流程是怎样的?
4、Attention机制的变种有哪些?
5、一种强大的Attention机制:为什么自注意力模型(self-Attention model)在长距离序列中如此强大?
(1)卷积或循环神经网络难道不能处理长距离序列吗?
(2)要解决这种短距离依赖的“局部编码”问题,从而对输入序列建立长距离依赖关系,有哪些办法呢?
(3)自注意力模型(self-Attention model)具体的计算流程是怎样的呢?
二、Transformer(Attention Is All You Need)详解
1、Transformer的整体架构是怎样的?由哪些部分组成?
2、Transformer Encoder 与 Transformer Decoder 有哪些不同?
3、Encoder-Decoder attention 与self-attention mechanism有哪些不同?
4、multi-head self-attention mechanism具体的计算过程是怎样的?
5、Transformer在GPT和Bert等词向量预训练模型中具体是怎么应用的?有什么变化?
一、Attention机制剖析
1、为什么要引入Attention机制?
根据通用近似定理,前馈网络和循环网络都有很强的能力。但为什么还要引入注意力机制呢?
计算能力的限制:当要记住很多“信息“,模型就要变得更复杂,然而目前计算能力依然是限制神经网络发展的瓶颈。
优化算法的限制:虽然局部连接、权重共享以及pooling等优化操作可以让神经网络变得简单一些,有效缓解模型复杂度和表达能力之间的矛盾;但是,如循环神经网络中的长距离以来问题,信息“记忆”能力并不高。
可以借助人脑处理信息过载的方式,例如Attention机制可以提高神经网络处理信息的能力。
2、Attention机制有哪些?(怎么分类?)
当用神经网络来处理大量的输入信息时,也可以借鉴人脑的注意力机制,只 选择一些关键的信息输入进行处理,来提高神经网络的效率。按照认知神经学中的注意力,可以总体上分为两类:
聚焦式(focus)注意力:自上而下的有意识的注意力,主动注意——是指有预定目的、依赖任务的、主动有意识地聚焦于某一对象的注意力;
显著性(saliency-based)注意力:自下而上的有意识的注意力,被动注意——基于显著性的注意力是由外界刺激驱动的注意,不需要主动干预,也和任务无关;可以将max-pooling和门控(gating)机制来近似地看作是自下而上的基于显著性的注意力机制。
在人工神经网络中,注意力机制一般就特指聚焦式注意力。
3、Attention机制的计算流程是怎样的?
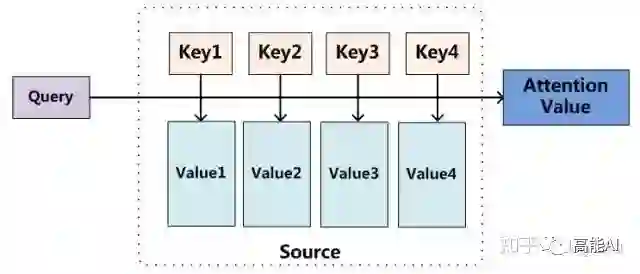
Attention机制的实质其实就是一个寻址(addressing)的过程,如上图所示:给定一个和任务相关的查询Query向量 q,通过计算与Key的注意力分布并附加在Value上,从而计算Attention Value,这个过程实际上是Attention机制缓解神经网络模型复杂度的体现:不需要将所有的N个输入信息都输入到神经网络进行计算,只需要从X中选择一些和任务相关的信息输入给神经网络。
注意力机制可以分为三步:一是信息输入;二是计算注意力分布α;三是根据注意力分布α 来计算输入信息的加权平均。
step1-信息输入:用X = [x1, · · · , xN ]表示N 个输入信息;
step2-注意力分布计算:令Key=Value=X,则可以给出注意力分布

我们将 

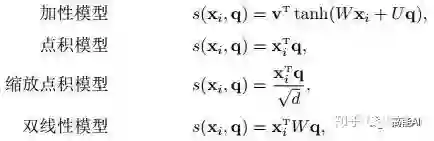
step3-信息加权平均:注意力分布

这种编码方式为软性注意力机制(soft Attention),软性注意力机制有两种:普通模式(Key=Value=X)和键值对模式(Key!=Value)。
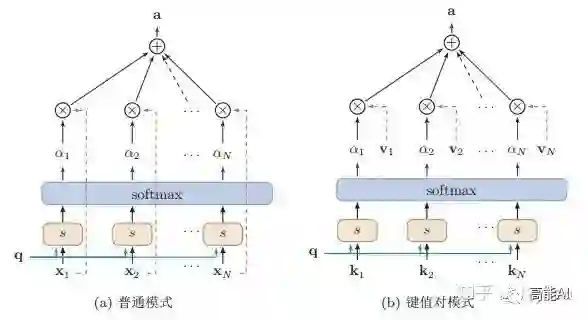
4、Attention机制的变种有哪些?
与普通的Attention机制(上图左)相比,Attention机制有哪些变种呢?
变种1-硬性注意力:之前提到的注意力是软性注意力,其选择的信息是所有输入信息在注意力 分布下的期望。还有一种注意力是只关注到某一个位置上的信息,叫做硬性注意力(hard attention)。硬性注意力有两种实现方式:(1)一种是选取最高概率的输入信息;(2)另一种硬性注意力可以通过在注意力分布式上随机采样的方式实现。硬性注意力模型的缺点:
硬性注意力的一个缺点是基于最大采样或随机采样的方式来选择信息。因此最终的损失函数与注意力分布之间的函数关系不可导,因此无法使用在反向传播算法进行训练。为了使用反向传播算法,一般使用软性注意力来代替硬性注意力。硬性注意力需要通过强化学习来进行训练。——《神经网络与深度学习》
变种2-键值对注意力:即上图右边的键值对模式,此时Key!=Value,注意力函数变为:

变种3-多头注意力:多头注意力(multi-head attention)是利用多个查询Q = [q1, · · · , qM],来平行地计算从输入信息中选取多个信息。每个注意力关注输入信息的不同部分,然后再进行拼接:
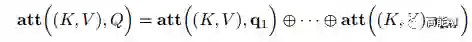
5、一种强大的Attention机制:为什么自注意力模型(self-Attention model)在长距离序列中如此强大?
(1)卷积或循环神经网络难道不能处理长距离序列吗?
当使用神经网络来处理一个变长的向量序列时,我们通常可以使用卷积网络或循环网络进行编码来得到一个相同长度的输出向量序列,如图所示:

从上图可以看出,无论卷积还是循环神经网络其实都是对变长序列的一种“局部编码”:卷积神经网络显然是基于N-gram的局部编码;而对于循环神经网络,由于梯度消失等问题也只能建立短距离依赖。
(2)要解决这种短距离依赖的“局部编码”问题,从而对输入序列建立长距离依赖关系,有哪些办法呢?
如果要建立输入序列之间的长距离依赖关系,可以使用以下两种方法:一 种方法是增加网络的层数,通过一个深层网络来获取远距离的信息交互,另一种方法是使用全连接网络。——《神经网络与深度学习》
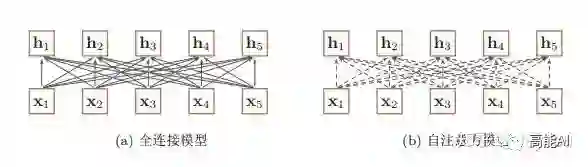
由上图可以看出,全连接网络虽然是一种非常直接的建模远距离依赖的模型, 但是无法处理变长的输入序列。不同的输入长度,其连接权重的大小也是不同的。
这时我们就可以利用注意力机制来“动态”地生成不同连接的权重,这就是自注意力模型(self-attention model)。由于自注意力模型的权重是动态生成的,因此可以处理变长的信息序列。
总体来说,为什么自注意力模型(self-Attention model)如此强大:利用注意力机制来“动态”地生成不同连接的权重,从而处理变长的信息序列。
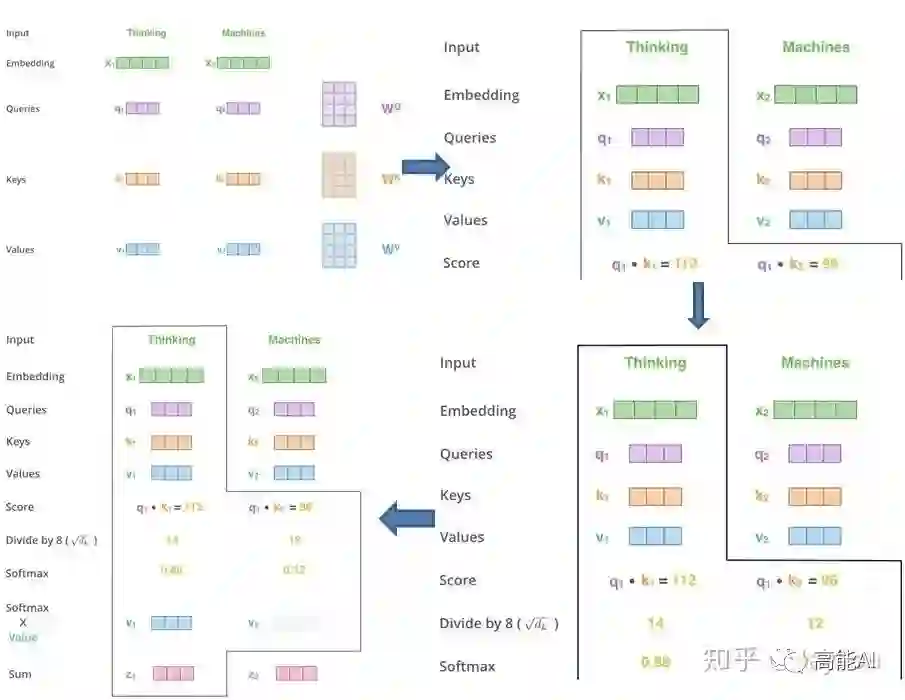
(3)自注意力模型(self-Attention model)具体的计算流程是怎样的呢?
同样,给出信息输入:用X = [x1, · · · , xN ]表示N 个输入信息;通过线性变换得到为查询向量序列,键向量序列和值向量序列:

上面的公式可以看出,self-Attention中的Q是对自身(self)输入的变换,而在传统的Attention中,Q来自于外部。
注意力计算公式为:
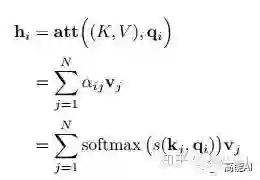
自注意力模型(self-Attention model)中,通常使用缩放点积来作为注意力打分函数,输出向量序列可以写为:

二、Transformer(Attention Is All You Need)详解
从Transformer这篇论文的题目可以看出,Transformer的核心就是Attention,这也就是为什么本文会在剖析玩Attention机制之后会引出Transformer,如果对上面的Attention机制特别是自注意力模型(self-Attention model)理解后,Transformer就很容易理解了。
1、Transformer的整体架构是怎样的?由哪些部分组成?
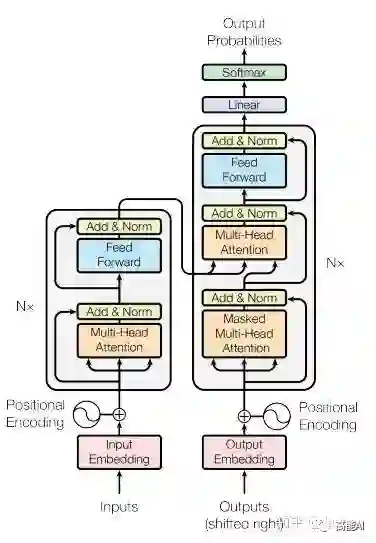
Transformer其实这就是一个Seq2Seq模型,左边一个encoder把输入读进去,右边一个decoder得到输出:
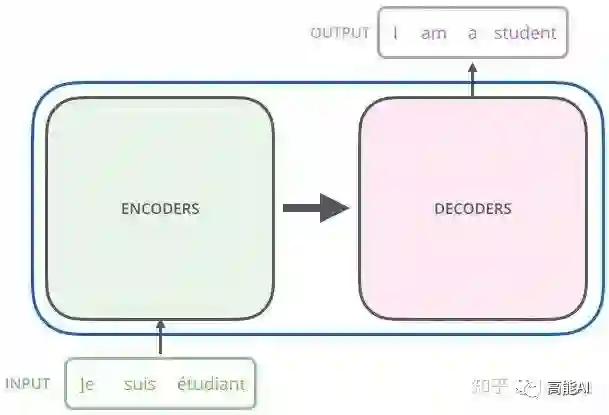
Transformer=Transformer Encoder+Transformer Decoder
(1)Transformer Encoder(N=6层,每层包括2个sub-layers):
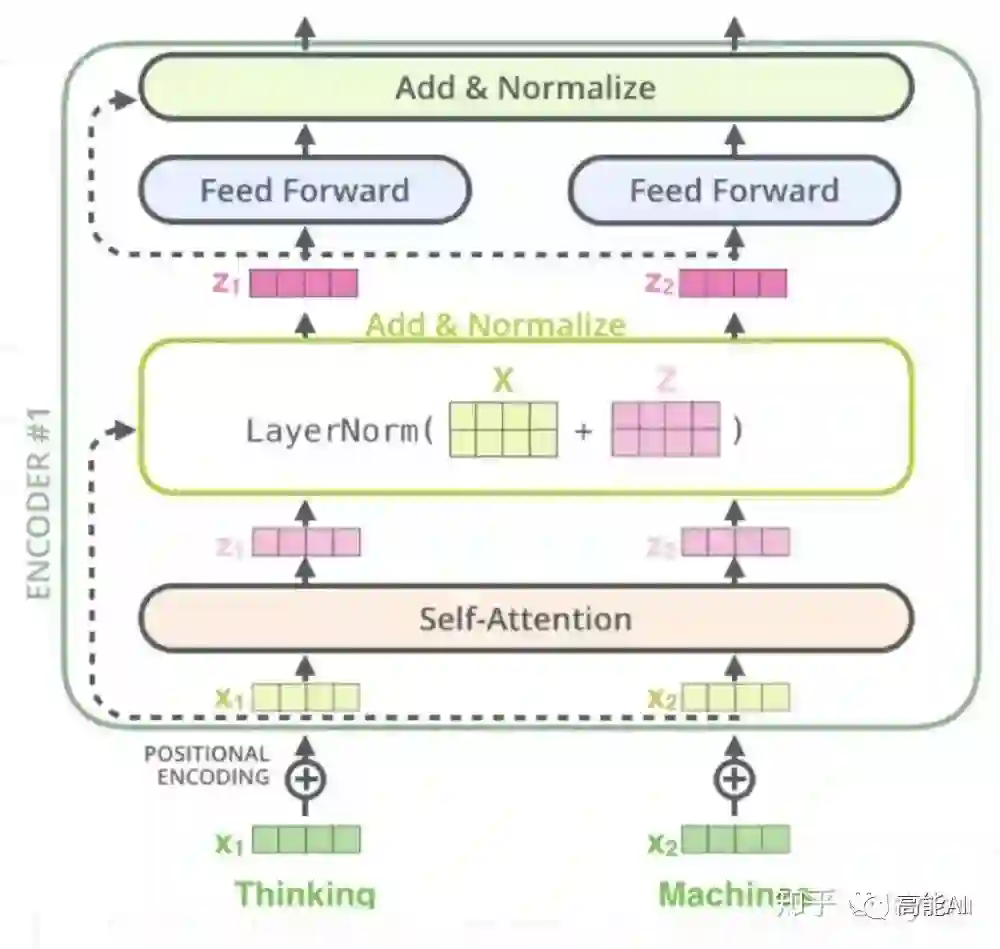
sub-layer-1:multi-head self-attention mechanism,用来进行self-attention。
sub-layer-2:Position-wise Feed-forward Networks,简单的全连接网络,对每个position的向量分别进行相同的操作,包括两个线性变换和一个ReLU激活输出(输入输出层的维度都为512,中间层为2048):
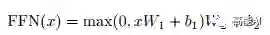
每个sub-layer都使用了残差网络:

(2)Transformer Decoder(N=6层,每层包括3个sub-layers):
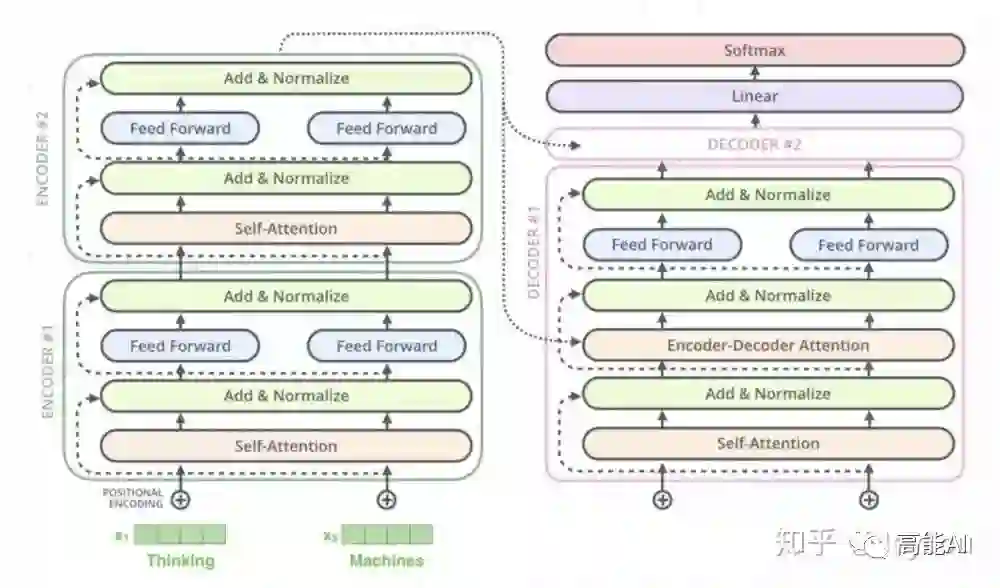
sub-layer-1:Masked multi-head self-attention mechanism,用来进行self-attention,与Encoder不同:由于是序列生成过程,所以在时刻 i 的时候,大于 i 的时刻都没有结果,只有小于 i 的时刻有结果,因此需要做Mask。
sub-layer-2:Position-wise Feed-forward Networks,同Encoder。
sub-layer-3:Encoder-Decoder attention计算。
2、Transformer Encoder 与 Transformer Decoder 有哪些不同?
(1)multi-head self-attention mechanism不同,Encoder中不需要使用Masked,而Decoder中需要使用Masked;
(2)Decoder中多了一层Encoder-Decoder attention,这与 self-attention mechanism不同。
3、Encoder-Decoder attention 与self-attention mechanism有哪些不同?
它们都是用了 multi-head计算,不过Encoder-Decoder attention采用传统的attention机制,其中的Query是self-attention mechanism已经计算出的上一时间i处的编码值,Key和Value都是Encoder的输出,这与self-attention mechanism不同。代码中具体体现:
## Multihead Attention ( self-attention)
self.dec = multihead_attention(queries=self.dec,
keys=self.dec,
num_units=hp.hidden_units,
num_heads=hp.num_heads,
dropout_rate=hp.dropout_rate,
is_training=is_training,
causality=True,
scope="self_attention")
## Multihead Attention ( Encoder-Decoder attention)
self.dec = multihead_attention(queries=self.dec,
keys=self.enc,
num_units=hp.hidden_units,
num_heads=hp.num_heads,
dropout_rate=hp.dropout_rate,
is_training=is_training,
causality=False,
scope="vanilla_attention")4、multi-head self-attention mechanism具体的计算过程是怎样的?
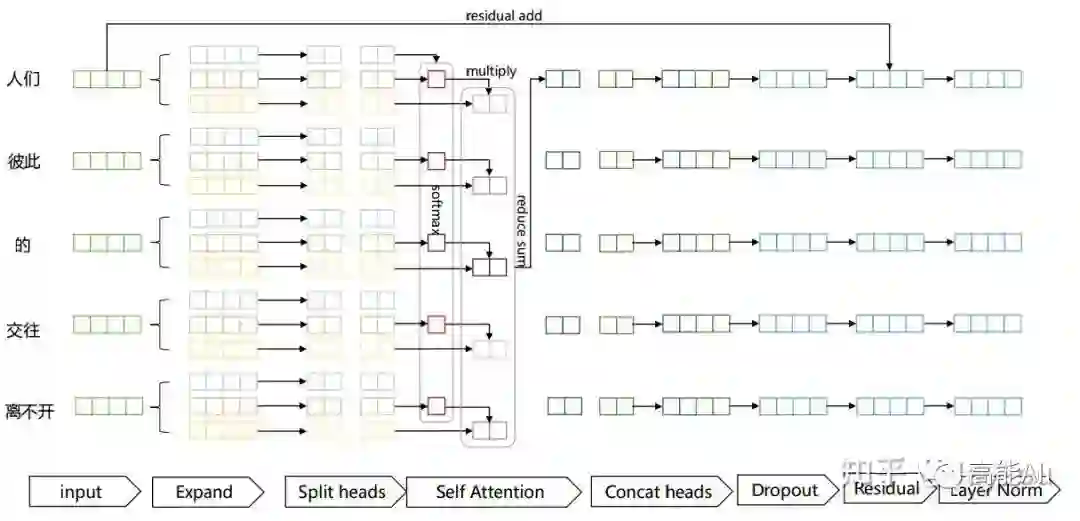
Transformer中的Attention机制由Scaled Dot-Product Attention和Multi-Head Attention组成,上图给出了整体流程。下面具体介绍各个环节:
Expand:实际上是经过线性变换,生成Q、K、V三个向量;
Split heads: 进行分头操作,在原文中将原来每个位置512维度分成8个head,每个head维度变为64;
Self Attention:对每个head进行Self Attention,具体过程和第一部分介绍的一致;
Concat heads:对进行完Self Attention每个head进行拼接;
上述过程公式为:

5、Transformer在GPT和Bert等词向量预训练模型中具体是怎么应用的?有什么变化?
GPT中训练的是单向语言模型,其实就是直接应用Transformer Decoder;
Bert中训练的是双向语言模型,应用了Transformer Encoder部分,不过在Encoder基础上还做了Masked操作;
BERT Transformer 使用双向self-attention,而GPT Transformer 使用受限制的self-attention,其中每个token只能处理其左侧的上下文。双向 Transformer 通常被称为“Transformer encoder”,而左侧上下文被称为“Transformer decoder”,decoder是不能获要预测的信息的。
Reference
《神经网络与深度学习》
Attention Is All You Need
谷歌BERT解析----2小时上手最强NLP训练模型
细讲 | Attention Is All You Need
深度学习中的注意力模型(2017版)
推荐阅读
百度aistudio事件抽取比赛总结——记一次使用MRC方式做事件抽取任务的尝试
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,点个在看吧👇


