华为天才少年谢凌曦:关于视觉识别领域发展的个人观点
![]()
新智元报道

新智元报道
【新智元导读】计算机视觉识别领域的发展如何?华为天才少年谢凌曦分享了万字长文,阐述了个人对其的看法。
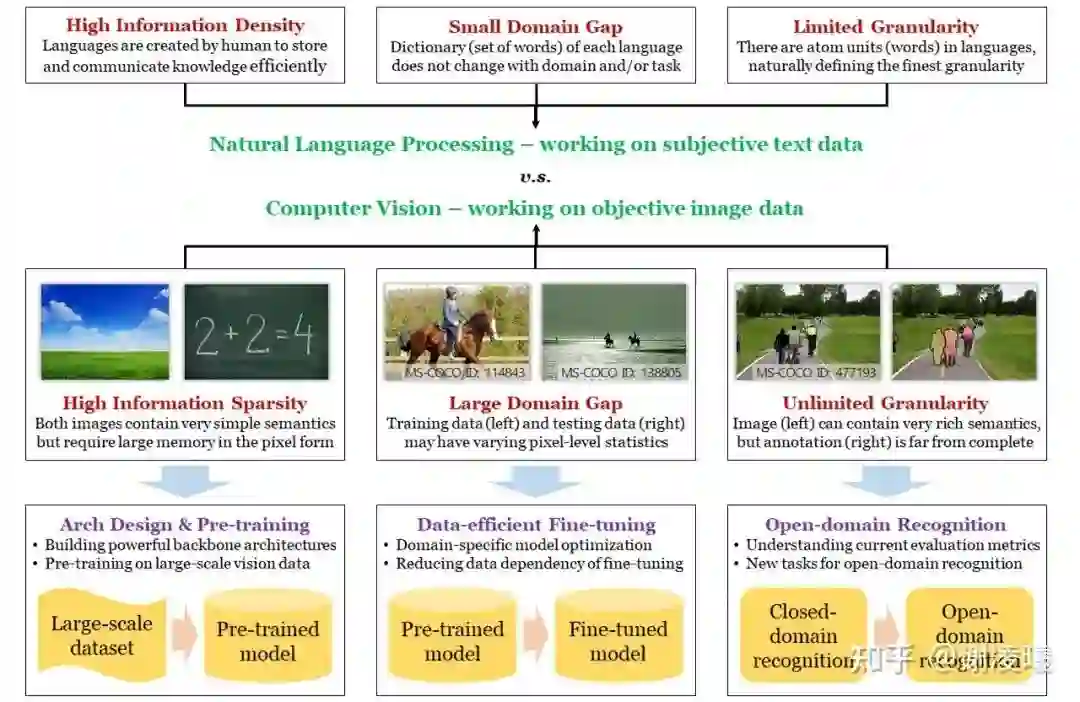
CV的三大基本困难和对应的研究方向
-
语义稀疏性 :解决方案为构建高效计算模型(神经网络)和视觉预训练。此处的主要逻辑在于,想要提升数据的信息密度,就必须假设数据的非均匀分布(信息论)并对其建模(即学习数据的先验分布)。目前,最为高效的建模方式有两类,一类是通过神经网络架构设计,来捕捉数据无关的先验分布(例如卷积模块对应于图像数据的局部性先验、transformer模块对应于图像数据的注意力先验);一类是通过在大规模数据上的预训练,来捕捉数据相关的先验分布。这两个研究方向,也是视觉识别领域最为基础、受到关注最多的研究方向。
-
域间差异性 :解决方案为数据高效的微调算法。根据以上分析,网络体量越大、预训练数据集体量越大,计算模型中存储的先验就越强。然而,当预训练域和目标域的数据分布具有较大差异时,这种强先验反而会带来坏处,因为信息论告诉我们:提升某些部分(预训练域)的信息密度,就一定会降低其他部分(预训练域没有包含的部分,即预训练过程中认为不重要的部分)的信息密度。现实中,目标域很可能部分或者全部落在没有包含的部分,导致直接迁移预训练模型的效果很差(即过拟合)。此时,就需要通过在目标域进行微调来适应新的数据分布。考虑到目标域的数据体量往往远小于预训练域,因而数据高效是必不可少的假设。此外,从实用的角度看,模型必须能够适应随时变化的域,因而终身学习是必须。
-
无限粒度性 :解决方案为开放域识别算法。无限粒度性包含开放域特性,是更高的追求目标。这个方向的研究还很初步,特别是业界还没有能被普遍接受的开放域识别数据集和评价指标。这里最本质的问题之一,是如何向视觉识别中引入开放域能力。可喜的是,随着跨模态预训练方法的涌现(特别是2021年的CLIP),自然语言越来越接近成为开放域识别的牵引器,我相信这会是未来2-3年的主流方向。然而,我并不赞成在追求开放域识别的过程中,涌现出的各种zero-shot识别任务。我认为zero-shot本身是一个伪命题,世界上并不存在也不需要zero-shot识别方法。现有的zero-shot任务,都是使用不同方法,将信息泄露给算法,而泄露方式的千差万别,导致不同方法之间难以进行公平对比。在这个方向上,我提出了一种被称为按需视觉识别的方法,以进一步揭示、探索视觉识别的无限粒度性。
以下简要分析各个研究方向
-
2012-2017年,手工构建更深的卷积神经网络,探索一般优化技巧。关键词:ReLU、Dropout、3x3卷积、BN、跳跃连接,等。在这个阶段,卷积操作是最基本的单元,它对应于图像特征的局部性先验。
-
2017-2020年,自动构建更复杂的神经网络。其中,网络架构搜索(NAS)盛行一时,最后定型为基础工具。在任意给定的搜索空间中,自动设计都能够达到稍微更好的结果,且能够快速适配不同的计算开销。
-
2020年至今,起源于NLP的transformer模块从被引入CV,利用attention机制,补足了神经网络的远距离建模能力。如今,大部分视觉任务的最优结果,都借助于包含transformer的架构所达到。
-
如果视觉识别任务没有明显改变,那么不论是自动设计,或者加入更复杂的计算模块,都无法将CV推向新的高度。视觉识别任务的可能改变,大致可以分为输入和输出两个部分。输入部分的可能改变如event camera,它可能会改变规则化处理静态或者时序视觉信号的现状,催生特定的神经网络结构;输出部分的可能改变,则是某种统一各种识别任务的框架(方向3会谈到),它有可能让视觉识别从独立任务走向大一统,从而催生出一种更适合视觉prompt的网络架构。
-
如果一定要在卷积和transformer之间做取舍,那么transformer的潜力更大,主要因为它能够统一不同的数据模态,尤其是文本和图像这两个最常见也最重要的模态。
-
可解释性是一个很重要的研究方向,但是我个人对于深度神经网络的可解释性持悲观态度。NLP的成功,也不是建立在可解释性上,而是建立在过拟合大规模语料库上。对于真正的AI来说,这可能不是太好的信号。
方向1b:视觉预训练
-
有监督预训练的发展相对清晰。由于图像级分类数据最容易获取,因此早在深度学习爆发之前,就有了日后奠定深度学习基础的ImageNet数据集,并被沿用至今。ImageNet全集超过1500万的数据规模,至今没有被其他非分类数据集所超越,因此至今仍是有监督预训练上最常用的数据。另外一个原因,则是图像级分类数据引入了较少bias,因而对于下游迁移更加有利——进一步减少bias,就是无监督预训练。
-
无监督预训练,则经历了曲折的发展历程。从2014年开始,出现了第一代基于几何的无监督预训练方法,如根据patch位置关系、根据图像旋转等进行判断,同时生成式方法也在不断发展(生成式方法可以追溯到更早的时期,此处不赘述)。此时的无监督预训练方法,还显著地弱于有监督预训练方法。到了2019年,对比学习方法经过技术改进,首次显现出在下游任务上超越有监督预训练方法的潜力,无监督学习真正成为CV界关注的焦点。而2021年开始,视觉transformer的兴起催生了一类特殊的生成式任务即MIM,它逐渐成为统治性方法。
-
除了纯粹的有监督和无监督预训练,还有一类介于两者之间的方法,是跨模态预训练。它使用弱配对的图像和文本作为训练素材,一方面避免了图像监督信号带来的bias,一方面又比无监督方法更能学习弱语义。此外,在transformer的加持下,视觉和自然语言的融合也更自然、更合理。
-
从实际应用上看,应该将不同的预训练任务结合起来。也就是说,应当收集混合数据集,其中包含少量有标签数据(甚至是检测、分割等更强的标签)、中量图文配对数据、大量无任何标签的图像数据,并且在这样的混合数据集上设计预训练方法。
-
从CV领域看,无监督预训练是最能体现视觉本质的研究方向。即使跨模态预训练给整个方向带来了很大的冲击,我依然认为无监督预训练非常重要,必须坚持下去。需要指出,视觉预训练的思路很大程度上受到了自然语言预训练的影响,但是两者性质不同,因而不能一概而论。尤其是,自然语言本身是人类创造出来的数据,其中每个单词、每个字符都是人类写下来的,天然带有语义,因此从严格意义上说,NLP的预训练任务不能被视为真正的无监督预训练,至多算是弱监督的预训练。但是视觉不同,图像信号是客观存在、未经人类处理的原始数据,在其中的无监督预训练任务一定更难。总之,即使跨模态预训练能够在工程上推进视觉算法,使其达到更好的识别效果,视觉的本质问题还是要靠视觉本身来解决。
-
当前,纯视觉无监督预训练的本质在于从退化中学习。这里的退化,指的是从图像信号中去除某些已经存在的信息,要求算法复原这些信息:几何类方法去除的是几何分布信息(如patch的相对位置关系);对比类方法去除的是图像的整体信息(通过抽取不同的view);生成类方法如MIM去除的是图像的局部信息。这种基于退化的方法,都具有一个无法逾越的瓶颈,即退化强度和语义一致性的冲突。由于没有监督信号,视觉表征学习完全依赖于退化,因此退化必须足够强;而退化足够强时,就无法保证退化前后的图像具有语义一致性,从而导致病态的预训练目标。举例说,对比学习从一张图像中抽取的两个view如果毫无关系,拉近它们的特征就不合理;MIM任务如果去除了图像中的关键信息(如人脸),重建这些信息也不合理。强行完成这些任务,就会引入一定的bias,弱化模型的泛化能力。未来,应该会出现一种无需退化的学习任务,而我个人相信,通过压缩来学习是一条可行的路线。
方向2:模型微调和终身学习
-
迁移学习:假设 Dpre 或者 Dtrain 和 Dtest 的数据分布大不相同; -
弱监督学习:假设 Dtrain 只提供了不完整的标注信息; -
半监督学习:假设 Dtrain 只有部分数据被标注; -
带噪学习:假设 Dtrain 的部分数据标注可能有误; -
主动学习:假设 Dtrain 可以通过交互形式标注(挑选其中最难的样本)以提升标注效率; -
持续学习:假设不断有新的 Dtrain 出现,从而学习过程中可能会遗忘从 Dpre 学习的内容; -
……
-
从孤立的setting向终身学习的统一。从学术界到工业界,必须抛弃“一次性交付模型”的思维,将交付内容理解为以模型为中心,配套有数据治理、模型维护、模型部署等多种功能的工具链。用工业界的话说,一个模型或者一套系统,在整个项目的生命周期中,必须得到完整的看护。必须考虑到,用户的需求是多变且不可预期的,今天可能会换个摄像头,明天可能会新增要检测的目标种类,等等。我们不追求AI能自主解决所有问题,但是AI算法应该有一个规范操作流程,让不懂AI的人能够遵循这个流程,新增他们想要的需求、解决平时遇到的问题,这样才能让AI真正平民化,解决实际问题。对于学术界,必须尽快定义出符合真实场景的终身学习setting,建立起相应的benchmark,推动这一方向的研究。
-
在域间差异明显的情况下,解决大数据和小样本的冲突。这又是CV和NLP的不同点:NLP已经基本不用考虑预训练和下游任务的域间差异性,因为语法结构和常见单词完全一样;而CV则必须假设上下游数据分布显著不同,以致于上游模型未经微调时,在下游数据中无法抽取底层特征(被ReLU等单元直接滤除)。因此,用小数据微调大模型,在NLP领域不是大问题(现在的主流是只微调prompt),但是在CV领域是个大问题。在这里,设计视觉友好的prompt也许是个好方向,但是目前的研究还没有切入核心问题。
方向3:无限细粒度视觉识别任务

-
基于分类的方法:这包括传统意义上的分类、检测、分割等方法,其基本特点是给图像中的每个基本语义单元(图像、box、mask、keypoint等)赋予一个类别标签。这种方法的致命缺陷在于,当识别的粒度增加时,识别的确定性必然下降,也就是说,粒度和确定性是冲突的。举例说,在ImageNet中,存在着“家具”和“电器”两个大类;显然“椅子”属于“家具”,而“电视机”属于“家电”,但是“按摩椅”属于“家具”还是“家电”,就很难判断——这就是语义粒度的增加引发的确定性的下降。如果照片里有一个分辨率很小的“人”,强行标注这个“人”的“头部”甚至“眼睛”,那么不同标注者的判断可能会不同;但是此时,即使是一两个像素的偏差,也会大大影响IoU等指标——这就是空间粒度的增加引发的确定性的下降。
-
语言驱动的方法:这包括CLIP带动的视觉prompt类方法,以及存在更长时间的visual grounding问题等,其基本特点是利用语言来指代图像中的语义信息并加以识别。语言的引入,确实增强了识别的灵活性,并带来了天然的开放域性质。然而语言本身的指代能力有限(想象一下,在一个具有上百人的场景中指代某个特定个体),无法满足无限细粒度视觉识别的需要。归根结底,在视觉识别领域,语言应当起到辅助视觉的作用,而已有的视觉prompt方法多少有些喧宾夺主的感觉。
-
开放性:开放域识别,是无限细粒度识别的一个子目标。目前看,引入语言是实现开放性的最佳方案之一。 -
特异性:引入语言时,不应被语言束缚,而应当设计视觉友好的指代方案(即识别任务)。 -
可变粒度性:并非总是要求识别到最细粒度,而是可以根据需求,灵活地改变识别的粒度。

-
按需视觉识别中的request,本质上是一种视觉友好的prompt。它既能够达到询问视觉模型的目的,又避免了纯语言prompt带来的指代模糊性。随着更多类型的request被引入,这个体系有望更加成熟。
-
按需视觉识别,提供了在形式上统一各种视觉任务的可能性。例如,分类、检测、分割等任务,在这一框架下得到了统一。这一点可能对视觉预训练带来启发。目前,视觉预训练和下游微调的边界并不清楚,预训练模型究竟应该适用于不同任务,还是专注于提升特定任务,尚无定论。然而,如果出现了形式上统一的识别任务,那么这个争论也许就不再重要。顺便说,下游任务在形式上的统一,也是NLP领域享有的一大优势。
在上述方向之外
-
在识别领域,传统的识别指标已经明显过时,因此人们需要更新的评价指标。目前,在视觉识别中引入自然语言,是明显且不可逆的趋势,但是这样还远远不够,业界需要更多任务层面的创新。
-
生成是比识别更高级的能力。人类能够轻易地识别出各种常见物体,但是很少有人能够画出逼真的物体。从统计学习的语言上说,这是因为生成式模型需要对联合分布 p(x,y) 进行建模,而判别式模型只需要对条件分布 p(y|x) 进行建模:前者能够推导出后者,而后者不能推导出前者。从业界的发展看,虽然图像生成质量不断提升,但是生成内容的稳定性(不生成明显非真实的内容)和可控性仍有待提升。同时,生成内容对于识别算法的辅助还相对较弱,人们还难以完全利用虚拟数据、合成数据,达到和真实数据训练相媲美的效果。对于这两个问题,我们的观点都是,需要设计更好、更本质的评价指标,以替代现有的指标(生成任务上替代FID、IS等,而生成识别任务需要结合起来,定义统一的评价指标)。
-
1978年,计算机视觉先驱David Marr设想,视觉的主要功能,在于建立环境的三维模型,并且在交互中学习知识。相比于识别和生成,交互更接近人类的学习方式,但是现在业界的研究相对较少。交互方向研究的主要困难,在于构建真实的交互环境——准确地说,当前视觉数据集的构建方式来源于对环境的稀疏采样,但交互需要连续采样。显然,要想解决视觉的本质问题,交互是本质。虽然业界已经有了许多相关研究(如具身智能),但是还没有出现通用的、任务驱动的学习目标。我们再次重复计算机视觉先驱David Marr提出的设想:视觉的主要功能,在于建立环境的三维模型,并且在交互中学习知识。计算机视觉,包括其他AI方向,都应该朝着这个方向发展,以走向真正的实用。
结语
作者声明


登录查看更多
相关内容
Arxiv
31+阅读 · 2021年11月1日


相关VIP内容
相关资讯