论文浅尝 - AAAI2020 | 多模态基准指导的多模态自动文摘
论文笔记整理:刘雅,天津大学硕士。

链接:
https://aaai.org/ojs/index.php/AAAI/article/view/6525
动机
近年来,随着计算机视觉以及自然语言处理技术的发展,多模态自动文摘技术逐渐成为学术界和工业界研究的热点。当前的多模态自动文摘受限于数据集本身的原因只能采用文本模态的负对数似然损失作为目标函数训练整个网络,同时利用注意力机制来辅助挑选图片。这种做法容易带来模态偏差的问题,即整个网络会倾向于优化文本生成的质量而忽视了图片的挑选过程。该论文提出了多模态基准指导的多模态自动文摘方法。基本想法是优化多模态摘要训练的目标函数,即在文本损失的基础上增加图片选择的损失函数。
亮点
论文亮点主要包括:
(1)提出一种新的评估指标,该论文是第一个从信息完整性的角度评估多模式摘要的方法,该方法学习了模型摘要和参考摘要的联合多模式表示形式。包含信息完整性的评估指标与人类判断的相关性更好。
(2)提出一种多模态损失函数,以多模态参考为指导,以利用摘要生成和图象选择中的损失
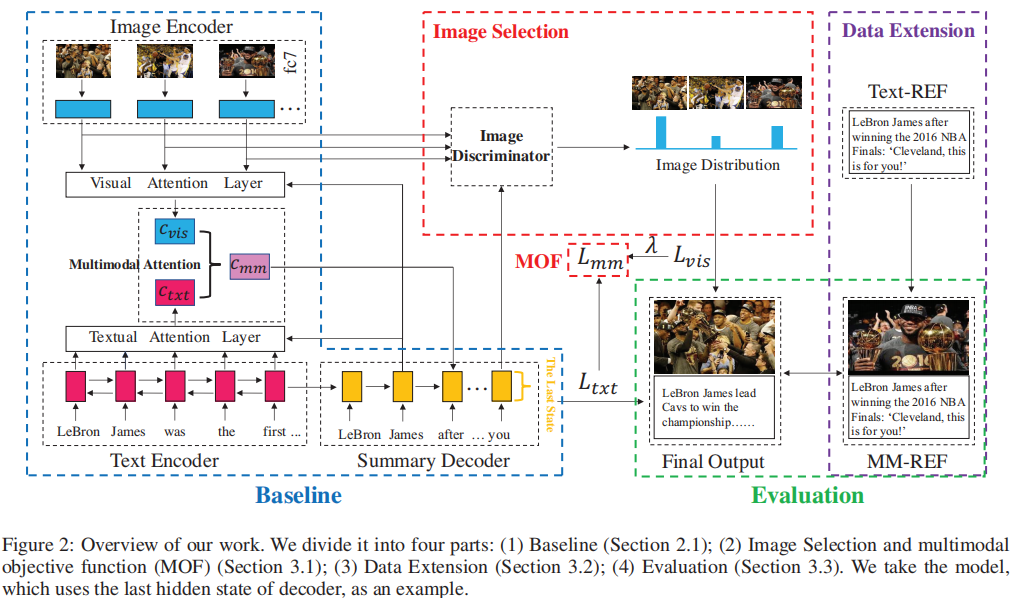
概念及模型
该方法由三部分组成:
首先利用数据集本身的特征将只有文本基准的训练数据扩展至多模态基准,主要采用两种方式,即直接使用输入图片的顺序对图片进行排序或者使用图片的文字描述与标准文本摘要参考答案之间的ROUGE值大小对输入图片进行排序。
在模型上添加图片判别器用于训练图片挑选的过程,模型的损失函数也由文本的损失函数及图片挑选的损失函数加权求和而成。
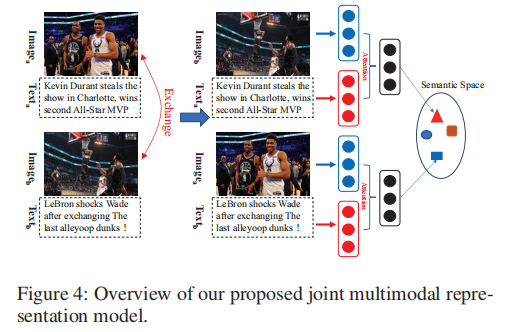
通过数据集中的图片和文本描述构造文本-图片对齐片段从而用来训练能够更好地评价多模态片段的评价模型,具体而言论文将两对图片-描述的文本部分(或图像部分)进行交换去构造两个匹配的多模态片段。
模型整体框架如下:
多模态匹配片段构造示意图如下:
多模态目标函数
为了在训练中利用多峰参考,论文提出了一种多峰目标函数,该函数除了考虑文本摘要的负对数似然损失外,还考虑了图像选择的交叉熵损失。论文将多模态摘要分解为两个任务:摘要生成和文本图像关系识别。为此,论文提出了一种图像识别器来指导图像选择。图像鉴别器将确定图像是否与文本内容有关。我们应用多任务学习来同时训练两个子任务。在多任务设置中,共享两个子任务的文本编码器和摘要解码器。论文使用另一个图片解码器将全局图象特征g转化为g’.
可以通过两种方式显示文本信息:(1)文本编码器的最后一个隐藏状态;或(2)摘要解码器的最后隐藏状态。为了将两个向量投影到一个联合语义空间中,论文使用两个具有ReLU激活功能的多层感知器将文本向量和视觉向量转换为Itxt和Ivis。图象和文本信息之间的相关性可以表示为:
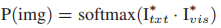
图像分为文本相关和非文本相关,这意味着可以将文本-图像关系识别视为分类任务。因此,论文采用了交叉熵损失:
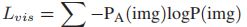
其中PA(img)表示图像的实际概率分布(如果选择排名前k位的图像作为目标,则图像的概率为1 / k。)。最后,将交叉熵损失(由超参数λ加权)添加到摘要生成的损失函数中,以产生一个同时考虑了文本参考和图像参考的新损失函数:
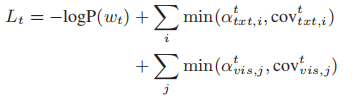
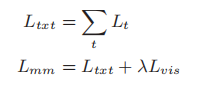
联合多模态表示
在跨模式检索中,输入是一对图像和一个文本。但是在该论文提出的模型中,输入变成一对多模态分段(ma,mb),其中ma =(Imagea,Texta)和mb =(Imageb,Textb)。关键问题是如何构建训练数据。MSMO数据集中有很多图像字幕对,并且假定每个图像都与相应的字幕相匹配。因此,通过交换两个图像标题对的图像(或文本)以获得匹配的多模态分段对(ma*,m*b),其中m*a =(Imageb,Texta)和m*b =(Imagea ,Textb)。值得注意的是,由于m*b中的Imagea与m*a中的Texta相匹配,而m*a中的Imageb与m*b中的Textb相匹配,因此m*a在语义上与m*b相匹配对图像和文本进行编码,然后使用多模式注意力机制融合文本向量和图像特征。最后模型是在一个新的最大利润率损失下训练的:
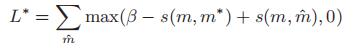
其中(m,m *)是匹配的多模态分段对,(m,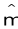
理论分析
实验
目前多模态自动文摘的数据集还比较匮乏,这项工作在MSMO数据集上进行实验验证。一般图文式摘要的评价关注三个方面的指标:图片准确率(IP)、文本摘要的ROUGE值(ROUGE-L)以及系统输出中图片文本的相关度(Msim)。该论文引入一个新的自动评价指标MRmax用来直接度量两个多模态信息之间的相似度(输出和参考答案的最大相似度)。MMAE是对IP、ROUGE和Msim的组合,MMAE++是IP、ROUGE、Msim和MRmax四个自动评价指标的组合。利用与人工打分之间的相关度来对比不同的自动评价指标。
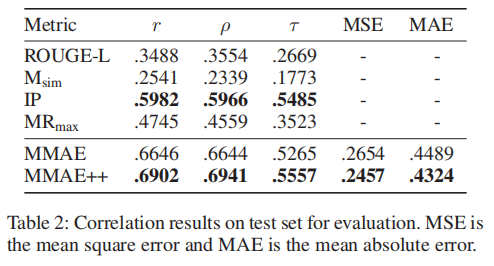
下表给出了不同的自动评价指标与人工打分的相关度,可以看出融入了直接测量多模态片段的评价指标MR之后,新的自动评价模型MMAE++相比于MMAE在与人工打分的相关度上有一个显著的提升。为了衡量论文提出的多模态基准指导的模型,论文同多个强基线模型进行了对比,包括融入全局或者局部视觉特征的多模态注意力机制的生成式自动文摘模型(ATG、ATL)、层次化的多模态自动文摘模型(HAN)以及基于图模型的抽取式自动文摘模型(GR)
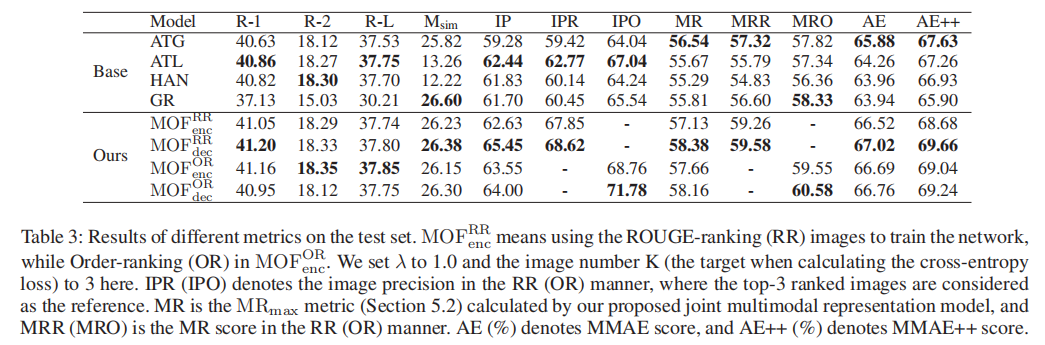
下表给出了不同模型生成的图文式摘要的质量对比,可以看出在引入多模态基准指导后,模型的图片挑选质量(IP)得到了显著的改善,并且文本生成质量也有略微改进,从而生成更高质量的图文摘要。相对于使用编码器隐层状态而言,采用解码器隐层状态去进行图片选择效果会更好。另一方面,使用图片描述与文本摘要之间ROUGE值的大小对图片排序获得的多模态基准对于模型的指导作用更加明显。
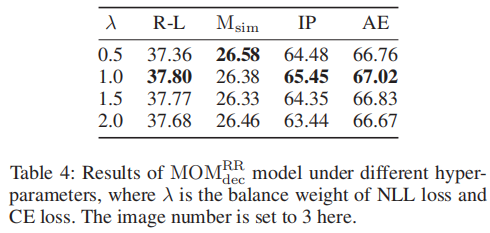
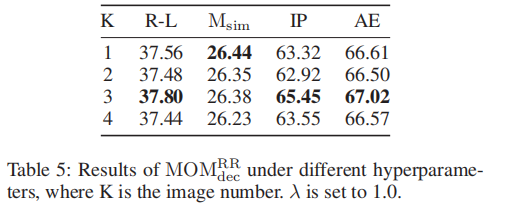
同时,本论文也对比了不同的图片选择损失函数权重对于模型性能的影响,可以看到当图片和文本的损失函数的权重都相同时,图文摘要的质量是最好的。
总结
在本文中,论文着重于通过提出一种多模式目标函数来改进多模式摘要,该目标函数同时考虑了文本摘要生成的负对数似然损失和图像选择的交叉熵损失。实验表明,该模型可以在真实的人工标记测试集和自动构建的测试集上提高多模式输出的质量。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。




