协作的力量——2021-2022年度《大数据系统基础》成果展示

来源:数据派THU
本文约6287字,建议阅读10分钟
本文介绍
了清华大学各研究单位及其研究项目。

实践单位:清华大学核能与新能源技术研究院
项目名称:核电厂关键敏感设备健康评估与寿命预测建模分析研究
小组成员:
张文济(组长) 核研院
李京人 土木系
刘书呈 机械系
罗儒维 工物系
项拓宇 工物系
范祥祺 工物系
牛恒 建筑学院
指导老师:黄晓津 周树桥 郭超
研究目标:核电厂运行工况复杂且设备测点有限,一旦发生故障,难以迅速准确的定位,且定位过程依赖专家判断,故障诊断延误可能给核电厂带来安全风险和巨大的经济损失。本项目依托清华-中国核电数字化研究中心,基于秦山、福清、三门等一线核电厂的实际运行数据,采用机理+数据的方法进行故障预测与诊断相关的建模分析研究。本项目为ASP-2智慧管理原型系统开发工作的一部分,旨在实现从设备数据到征兆判断再到失效推理的完整过程。
研究成果:本次课程为该项目的第二期。在第一期开展过程中,本项目已实现数据预处理和趋势征兆离散化判断算法、基于专家知识的规则库约简、失效决策推理算法等。本期项目针对上述任务做出了3个方面的改进,同时完成了3项新增任务。
改进:
1. 数据预处理的滤波优化:优化数据预处理时使用的中值滤波为小波滤波,在此前中值滤波的窗口大小选择会直接影响算法结果,该不确定参数在优化后消失。
2. 征兆判断算法的参数调整和完备性检验:利用实际和模拟数据,很好地完成了针对12种趋势征兆+6种阈值征兆判断的测试,证明当前征兆判断算法,在合理调节各类参数的情况下,支持对18种征兆的判断。
3. 专家知识驱动的规则库优化:考虑专家知识的不完备性,计算粗糙集模型中的上下近似集;优化决策表的属性约简和值约简算法,提高计算效率;采用python实现上述优化算法。
新增:
1. 解决趋势征兆判断时输入数据长度选择问题:实际趋势征兆判断时数据是随时间推移的,输入数据长度大小选择不确定影响算法判断的实时性和准确性性,在本期中研究设计分段拟合算法给出了针对测点的输入数据长度合理参考值。
2. 开发独立可调的趋势征兆判断可视化工具:使用Django开源框架,开发了可视化调试工具,支持获取数据趋势征兆判断结果和数据输入长度参考值。
3. 数据驱动的规则分类系统研究:采用Python实现了基于数据的模糊规则和信任规则提取方法,并采用UCI数据完成验证。
典型成果及应用图例:
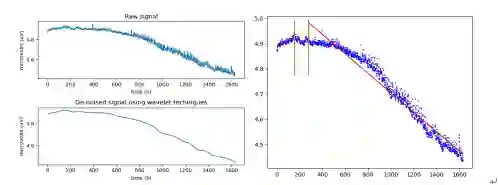
使用分段拟合算法获得数据输入长度参考值,取最短分段间隔为该值。
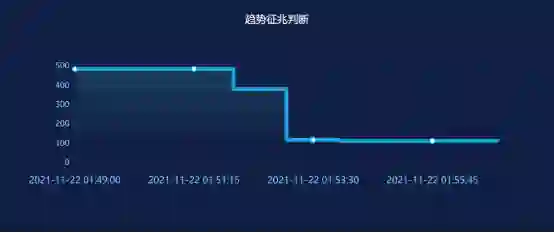

可视化工具界面
同学们的收获:
张文济:作为该项目的组长,我在此期间收获颇丰,从统筹大家的工作到最后的汇报演讲,都是对于我能力全面的锻炼。
李京人:通过本次大数据实践项目,学到了很多新的知识,同时也在现实项目中,锻炼了自己的大数据分析和可视化能力。
刘书呈:本次项目实践使我了解到了数据驱动的方法,同时提升了调试代码的能力。有幸遇到了一群靠谱的队友和负责的老师,这对我来说也是一段非常宝贵的经历。
项拓宇:一开始我是一个电脑里都没有装python的小白,项目过程中遇到了许多困难,但在老师的帮助与鼓励下,我坚持到最后并实现了基于模糊规则库的分类算法。
罗儒维:很感谢这次项目中给力的队友和悉心指教的老师及助教们,对于数据处理以及算法实现有了一些基本的了解。
范祥祺:一开始觉得每周要做的东西好多好繁琐,但在老师和队友们的帮助和鼓励下,我完成了自己负责的部分,收获满满。
牛恒:通过本次大数据课程实践任务,让我将课堂所学与实际应用相结合,加深了对大数据概念的理解。在完成过程中,小组团结一心,共同克服了许多看上去令人生畏的难题,同时感谢项目导师为我们提供的鼓励与帮助!
企业导师点评:
同学们从熟悉本项目一期工作着手,实现了对一期工作的优化改进,测试了原有征兆判断算法的完备性。并且分别对输入数据长度选择和数据驱动的规则分类系统进行了探索性研究,开展了趋势征兆判断可视化工具的开发工作,均相应获得了阶段性的成果。
通过本项目,同学们已经初步掌握大数据分析的思路和相关工具,尝试了将大数据课程中所学理论方法在重要领域的实际应用。相关探索性的工作很好地锻炼了同学们的学术思维,相互配合的过程也体现了同学们良好的协作能力。
大数据课程设置本项实践环节,为同学们学以致用、加深对大数据方法和应用途径的理解、提高科研能力提供了良好的平台。
实践单位:湖南智享未来生物科技有限公司
项目名称:细胞和微生物形态识别与分类
小组成员:
郝宇飞(组长)工业工程
高明亮 工业工程
方浩宇 软件学院
指导老师:许东(企业导师)邓圣旺(项目协调)陈轶(医学专家)杨雅文(助教)
研究目标: 智享未来公司研制的显微镜主要用于临床诊断,企业已完成显微镜硬件研制部分,并实现了样品的自动拍照。但传统的诊断方式需要人工对照片中的微生物个体进行分类和技术,这种方式工作量大、效率低下。企业希望研制一种能自动识别显微照片中的微生物个体的显微镜系统,同时提供自动分类和计数的功能,从而提高用户的工作效率。另一方面,企业希望其显微镜产品能在经济欠发达地区进行推广,用智能化的手段解决专业医疗工作者缺乏的问题。这就要求系统能在配置较低的计算机中运行。用户希望通过项目研究,识别准确率达到92%以上,识别时间小于10秒。
研究成果:
本项目主要结合深度学习和计算机视觉技术,完全满足了用户提出的需求。在用临床实际测数据试中,在包括人工识别难例样本的情况下,识别准确率达到了96%,达到了业内领先水平。在性能方面,系统在Intel i7-8750无GPU加速的情况下识别时间小于2秒,在虚拟机中用纯CPU计算识别时间小于6秒。在识别类型方面,我们不仅达到了现有样本类别全覆盖,还通过数据合成等数据增广方法实现了更多微生物个体的识别。在业务流程改进方面,我们通过和临床医生沟通,改进了某些人工标识别难例样本的传统方法,采用了实时可调节置信度的设计,使得系统更符合信息化应用特点。我们在本项目研究实现的算法模块,目前已和显微镜上位机系统的对接,并应用于企业实际产品中。

样本识别效果示例
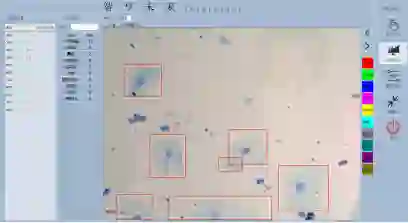
系统在显微镜上位机中的应用情况

系统在现场应用情况
同学们的收获:
郝宇飞:通过大数据基础课的项目实践,一方面强化了我们用数据思维解决实际问题的方法,另一方面也帮助企业解决了实际问题。这种以任务为导向的教学方式,不仅使我们所学的知识更加牢固,也能避免理论和实际脱节的风险。我们的项目之所以能取得现在的成果,是大家共同努力的结果。尽管在项目实现中遇到不少困难,我们还是设法解决了。
高明亮:将企业生产制造过程中遇到的现实问题引入课堂激发团队探寻解决方案的教学方式很赞!我们团队选择的课题是“细胞和微生物形态识别与分类”,属于计算机视觉(CV)在医学影像领域的落地应用。CV与医学影像的结合对于我个人是一个全新的知识领域,团队协作在项目的推进过程中发挥了重要的作用。由于编程技术是我的弱项,因此我承担了更多的需求沟通与项目管理相关工作。项目干系人涉及在职学生、显微镜厂家、医生、上位机开发人员等多类型角色,对需求的准确理解是项目成功的关键,因此项目前期团队便与企业方建立了良好的例会沟通机制,每次例会均会形成正式的会议纪要并公布,以确保双方对会议结论及下一步计划时间节点理解上的一致性。带着明确的目标学习相关技术,有的放矢,通过课程项目的训练,个人对CV的技术原理、与医学影像相结合的商业应用建立了初步认知。
方浩宇:通过细胞和微生物形态识别项目的研究工作,结合企业实践应用经验,将人工智能技术,尤其是深度学习技术与医疗等相关行业的具体应用场景相结合,可以有效解决行业一些典型痛点问题,把行业从业人员从低效重复的劳动中解放出来,显著提升行业业务技术水平。在技术研究方面,图像识别领域涉及的技术内容还是相对广泛的。为了解决企业对图像目标识别率低的问题,我们重点针对样本标注、图像增强、算法筛选及超参数调优等方面进行了相应的研究,深刻体会到人工智能技术在数据工程与数据科学技术领域的博大精深,值得研究的方向和内容也很多。同时,软件实践和参数调优的工作不简单,对企业实践的应用落地也很重要。我们团队在队长的带领下,大家的共同努力帮助企业解决了关键痛点问题,完成了项目目标。团队成员通过项目在相关领域增强了个人知识外,还收获了团队友谊,感谢学校设置这个课程给了我们这么好的学习和实践经历。
企业导师点评:
“细胞和微生物形态识别与分类”是根据湖南智享未来生物科技有限公司真实需求而开展的产学研结合项目。项目结合企业自主研发的全动化生物光学显微镜,最终实现了产品的智能化,解决了产品推入市场关键环节。该项目符合国家大力支持和发展智能医疗政策,基本做到了更精准、更便捷、更低廉的方式实现病人快速筛查诊断,具有重要的经济价值和良好的社会效应。实施过程中结合数据科学和医学专业知识分析方法,极大提升了识别的准确程度,团队成员不仅通过深度学习等方法研究解决了算法问题,还完成了与公司上位机软件的对接,为最终实际应用提供了方便。与传统的大数据算法必须借助GPU、大数据平台不同,该系统在普通电脑上使用CPU计算即可快速运行,达到了同行领先的识别率,落实了临床上有效检测问题。在项目实施过程中,时间安排合理、团队成员配合默契、与企业沟通及时高效。
实践单位:网帅科技(北京)有限公司
项目名称:态极时空知识图谱城市交通分析
小组成员:
王荣鑫(组长) 水利系
李妍慧 航院
康佳霖 医学院
刘康 水利系
张禹 水利系
李舸 水利系
王筱淳 环境学院
企业导师:胡庆勇、王志永
研究目标:
(1)借助网帅态极数据平台、厦门市路网数据、订单数据和机动车GPS数据,实现厦门市交通数据的映射和导入,分析出租车/网约车的城市出行特征。
(2)构建交通流时空知识图谱,实现可视化检索功能,方便用户更好地感知交通数据并参与深度探索过程。
(3)基于已构建的可计算路网,用图分析进行交通流预测,实现从点预测到网预测的突破,为用户提供科学合理的交通预测数据。
研究成果:
项目系统性地梳理了包括数据关系分析、本体及属性映射、数据导入及知识提取、图数据库导入等环节的数据分析映射流程,并应用于厦门市路网数据,实现了基于MDFS平台的城市出行特征分析和数据导入。
在此基础上,项目基于MDFS时空知识图谱搭建了可视化检索框架,设计实现了引导查询、精细化组合等检索功能,大大提升了用户感知数据和参与数据探索的能力。
同时,项目基于MDFS进行交通流时空数据测算,搭建了交通流时空图卷积神经网络模型,针对厦门市部分交通流数据进行训练预测,实现了接近90%准确率的交通流预测,全网路段单次预测未来12小时耗时仅2.324ms,实现了项目中交通流预测从点预测到网预测的突破,为用户获取更为合理的交通预测数据提供了可能。
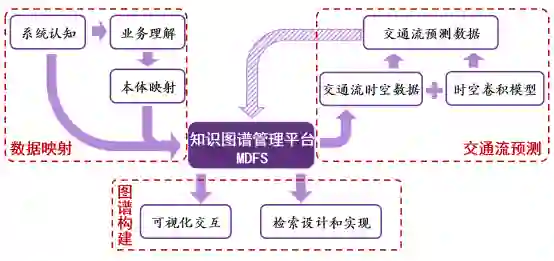
图 1 实践项目系统设计架构

图 2 可视化检索界面设计及功能实现
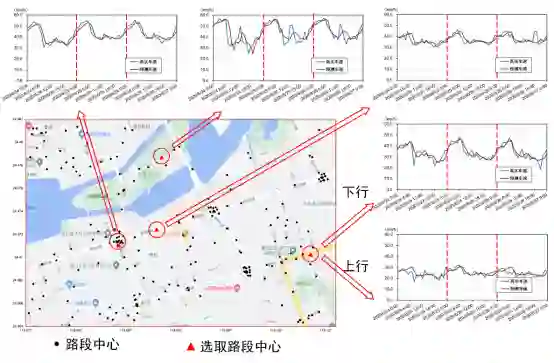
图 3 交通流预测结果
同学们的收获:
王荣鑫:熟悉了NEO4J 、GP等数据库操作,切身感受大数据技术应用,尝试挖掘大数据背后的语义,也体验到了大数据系统的协作性。
李妍慧:有幸与老师探索智慧交通领域的前沿问题,在交通流预测模型搭建工作中对交通流预测领域有了近距离接触,深入行业解决实际问题。
康佳霖:参与学习了知识图谱大数据系统等前沿热门领域,并应用于城市交通分析中,了解了技术发展趋势及技术应用价值,体验到前沿技术对社会的服务!
刘康:通过大数据实践感受到了一个项目从理论到落地的艰辛,同时也对大数据技术应用有了切实的理解,不再是一行行代码而具有了现实的承载物。
张禹:学习了一些高效的数据处理算法,提高了对交通大数据整理与归纳的能力。
李舸:学习了知识图谱的基本原理,基于已有平台梳理知识图谱的形成过程,同时初步了解了大数据的分析方式。
王筱淳:构建知识图谱是之前没有接触过的知识,了解到构建检索可视化界面的方法框架,加深了对大数据系统构建的理解。
企业导师点评:
本次实践项目小组成员系统性地进行数据关系分析,并在MDFS上实现了本体及属性映射、数据导入及知识提取、图数据库导入等知识存储全流程,并应用于厦门市路网数据及特征数据构建了厦门市路网城市特征知识图谱。基于MDFS时空知识图谱搭建了可视化检索框架,实现了引导查询、精细化组合等检索功能,提升了用户知识获取和参与知识探索的能力,为业务人员更方便直观的查看所有知识。项目基于MDFS在上面知识图谱构建后使用知识共享能力进行交通流时空数据测算,搭建了交通流时空图卷积神经网络模型,针对厦门市部分交通流数据进行训练预测,实现了接近90%准确率的交通流预测,全网路段单次预测未来12小时耗时仅2.324ms,实现了项目中交通流预测从点预测到网预测的突破,并将结果回到MDFS系统中,为用户获取更为合理的交通预测数据提供了可能。小组实现了从业务建模-知识提取-知识服务-知识应用整体流程。
本次实践项目为了是小组成员体验到实际业务场景,我们以真项目、真研发、真数据、真场景出发,从项目端到端整体进行项目研发过层。整体项目在组长带领下共分成了3个小组,分别是数据组、图谱组、预测组,每个小组成员都划分了自己的任务,在这样细化任务后同学们做到了团队合作,而不是单打独斗。每个成员认真的完成自己的任务并及时汇报。
每个同学出色的做到自己的任务是什么这么做、目标是什么为什么、时间线是何时。在项目期间同学们每个星期认真准备本周项目进度报告、下个星期阶段目标。积极参与每次项目例会。遇到问题及时提出、及时讨论解决。不仅仅发挥了业务技能水平,更很好的做到了团队合作,共同努力的实现项目目标。
课程介绍:
《大数据系统基础》分为《大数据系统基础A》和《大数据系统基础B》两部分,是清华大学大数据能力提升项目的基础模块必修课,开设于秋季学期。内容是设计与实现一个数据分析系统架构,并基于这一系统架构完成数据分析任务。组织形式是学生根据项目具体需求,组建院系交叉融合的项目小组,在校内导师和企业导师的共同指导下完成项目任务。欢迎企业积极贡献项目和数据,并指派特定的企业导师指导学生完成相应项目。
《大数据系统基础A》注重大数据系统应用,重点讲授大数据系统工具的概念、应用场景以及商业价值,通过对一系列与大数据相关的计算机系统知识的学习和动手实践,让学生理解大数据系统的软硬件架构、目前可用的工具、技术上存在的挑战,培养学生在工作中应用与选择大数据工具的能力,同时也为有志于继续深入学习大数据专业课程的学生创造基础。课程的主要内容包括:大数据生命周期、大数据软件栈、系统实践DWF、数据存储HDFS、时序数据IoTDB、数据质量分析过程与实战、Python语言、内存计算Spark、结构化数据Spark SQL、流计算Flink、系统实践FloK。
《大数据系统基础B》注重大数据系统开发,重点介绍大数据管理的工具平台、开发环境、基本原理,使得学生熟悉典型大数据工具与平台的特性,掌握大数据处理的基本开发方式,巩固和加深大数据分析的基础知识。课程的主要内容包括:大数据生命周期、大数据软件栈、数据导入Kafka、数据存储HDFS、非结构化数据Cassandra、时序数据IoTDB、分布式计算MapReduce、内存计算Spark、结构化数据Spark SQL、流计算Flink。
课程自开设以来就深受学生欢迎,其最大特色是突破了传统的教学方式,学生通过自行组队,以小组的形式在实际的企业项目中运用所学知识动手完成实践任务。今年,经过授课教师的严格把关和层层遴选,课程共引进了近20家来自业界的真实项目,行业数据多样化,领域涉及工业、石油化工、保险、交通、健康医疗和智慧城市等。



