Github项目推荐 | PyTorch代码规范最佳实践和样式指南

AI 科技评论按,本文不是 Python 的官方风格指南。本文总结了使用 PyTorch 框架进行深入学习的一年多经验中的最佳实践。本文分享的知识主要是以研究的角度来看的,它来源于一个开元的 github 项目。
根据经验,作者建议使用 Python 3.6+,因为以下功能有助于写出干净简单的代码:
支持 Python 3.6 以后的输入。
自 Python 3.6 起支持 f 字符串
Python Styleguide 概述
作者尝试按照 Google Styleguide for Python 进行操作,这里是 Google 提供的 python 代码详细样式指南(https://github.com/google/styleguide/blob/gh-pages/pyguide.md)。
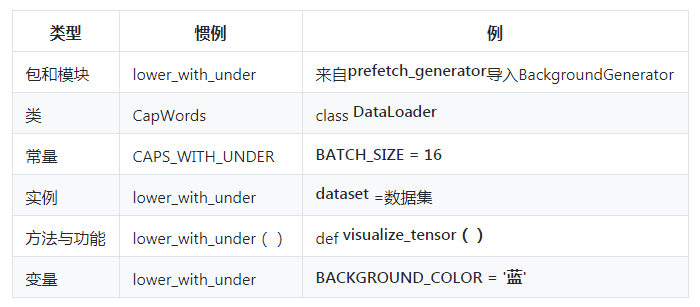
常见的命名约定:
Jupyter Notebook与Python脚本
一般来说,建议使用 Jupyternotebook 进行初步探索和使用新的模型和代码。如果你想在更大的数据集上训练模型,就应该使用 Python 脚本。在这里,复用性更为重要。
推荐使用的工作流程是:
从Jupyter笔记本开始
探索数据和模型
在 notebook 的单元格中构建类/方法
将代码移动到python脚本中
在服务器上训练/部署
注意,不要将所有层和模型放在同一个文件中。最佳做法是将最终网络分离为单独的文件(networks.py),并将层、损耗和 ops 保存在各自的文件(layers.py、losses.py、ops.py)中。完成的模型(由一个或多个网络组成)应在一个文件中引用,文件名为 yolov3.py、dcgan.py 这样。
在PyTorch中构建神经网络
我们建议将网络拆分为更小的可重用部分。网络由操作或其它网络模块组成。损失函数也是神经网络的模块,因此可以直接集成到网络中。
继承自 nn.module 的类必须有一个 forward 方法来实现各个层或操作的 forward 传递。
使用 self.net(input),可以在输入数据上使用 nn.module。这只需使用对象的 call()方法。
output = self.net(input)
PyTorch 中的一个简单网络
对于具有单个输入和单个输出的简单网络,请使用以下模式:
class ConvBlock(nn.Module):
def __init__(self):
super(ConvBlock, self).__init__()
block = [nn.Conv2d(...)]
block += [nn.ReLU()]
block += [nn.BatchNorm2d(...)]
self.block = nn.Sequential(*block)
def forward(self, x):
return self.block(x)
class SimpleNetwork(nn.Module):
def __init__(self, num_resnet_blocks=6):
super(SimpleNetwork, self).__init__()
# here we add the individual layers
layers = [ConvBlock(...)]
for i in range(num_resnet_blocks):
layers += [ResBlock(...)]
self.net = nn.Sequential(*layers)
def forward(self, x):
return self.net(x)
需要注意的是:
重用简单的、循环的构建块,例如 ConvBlock,它由相同的循环模式(卷积、激活、归一化)组成,并将它们放入单独的nn.模块中。
作者构建了一个所需层的列表,最后使用 nn.Sequential()将它们转换为模型。在 list 对象之前使用 * 操作符来展开它。
在前向传导中,我们只是通过模型运行输入。
pytorch 中跳过连接的网络
class ResnetBlock(nn.Module):
def __init__(self, dim, padding_type, norm_layer, use_dropout, use_bias):
super(ResnetBlock, self).__init__()
self.conv_block = self.build_conv_block(...)
def build_conv_block(self, ...):
conv_block = []
conv_block += [nn.Conv2d(...),
norm_layer(...),
nn.ReLU()]
if use_dropout:
conv_block += [nn.Dropout(...)]
conv_block += [nn.Conv2d(...),
norm_layer(...)]
return nn.Sequential(*conv_block)
def forward(self, x):
out = x + self.conv_block(x)
return out
在这里,ResNet 块的跳过连接直接在前向传导中实现。PyTorch 允许在前向传导时进行动态操作。
PyTorch中具有多个输出的网络
对于需要多个输出的网络,例如使用预训练的 VGG 网络构建感知损失,我们使用以下模式:
class Vgg19(nn.Module):
def __init__(self, requires_grad=False):
super(Vgg19, self).__init__()
vgg_pretrained_features = models.vgg19(pretrained=True).features
self.slice1 = torch.nn.Sequential()
self.slice2 = torch.nn.Sequential()
self.slice3 = torch.nn.Sequential()
for x in range(7):
self.slice1.add_module(str(x), vgg_pretrained_features[x])
for x in range(7, 21):
self.slice2.add_module(str(x), vgg_pretrained_features[x])
for x in range(21, 30):
self.slice3.add_module(str(x), vgg_pretrained_features[x])
if not requires_grad:
for param in self.parameters():
param.requires_grad = False
def forward(self, x):
h_relu1 = self.slice1(x)
h_relu2 = self.slice2(h_relu1)
h_relu3 = self.slice3(h_relu2)
out = [h_relu1, h_relu2, h_relu3]
return out
请注意:
这里使用 torchvision 提供的预训练模型。
这里把网络分成三部分,每个部分由预训练模型的层组成。
通过设置 requires_grad = False 来冻结网络。
我们返回一个包含三个输出部分的列表。
自定义损失
虽然 PyTorch 已经有很多标准的损失函数,但有时也可能需要创建自己的损失函数。为此,请创建单独的文件 losses.py 并扩展 nn.module 类以创建自定义的损失函数:
class CustomLoss(nn.Module):
def __init__(self):
super(CustomLoss,self).__init__()
def forward(self,x,y):
loss = torch.mean((x - y)**2)
return loss
推荐使用的用于训练模型的代码结构
请注意,作者使用了以下模式:
我们使用 prefetch_generator 中的 BackgroundGenerator 在后台加载 batch。有关详细信息,请参阅这里:
https://github.com/IgorSusmelj/pytorch-styleguide/issues/5
我们使用 tqdm 来监控训练进度并显示计算效率。这有助于我们在数据加载管道中找到瓶颈在哪里。
# import statements
import torch
import torch.nn as nn
from torch.utils import data
...
# set flags / seeds
torch.backends.cudnn.benchmark = True
np.random.seed(1)
torch.manual_seed(1)
torch.cuda.manual_seed(1)
...
# Start with main code
if __name__ == '__main__':
# argparse for additional flags for experiment
parser = argparse.ArgumentParser(description="Train a network for ...")
...
opt = parser.parse_args()
# add code for datasets (we always use train and validation/ test set)
data_transforms = transforms.Compose([
transforms.Resize((opt.img_size, opt.img_size)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
train_dataset = datasets.ImageFolder(
root=os.path.join(opt.path_to_data, "train"),
transform=data_transforms)
train_data_loader = data.DataLoader(train_dataset, ...)
test_dataset = datasets.ImageFolder(
root=os.path.join(opt.path_to_data, "test"),
transform=data_transforms)
test_data_loader = data.DataLoader(test_dataset ...)
...
# instantiate network (which has been imported from *networks.py*)
net = MyNetwork(...)
...
# create losses (criterion in pytorch)
criterion_L1 = torch.nn.L1Loss()
...
# if running on GPU and we want to use cuda move model there
use_cuda = torch.cuda.is_available()
if use_cuda:
net = net.cuda()
...
# create optimizers
optim = torch.optim.Adam(net.parameters(), lr=opt.lr)
...
# load checkpoint if needed/ wanted
start_n_iter = 0
start_epoch = 0
if opt.resume:
ckpt = load_checkpoint(opt.path_to_checkpoint) # custom method for loading last checkpoint
net.load_state_dict(ckpt['net'])
start_epoch = ckpt['epoch']
start_n_iter = ckpt['n_iter']
optim.load_state_dict(ckpt['optim'])
print("last checkpoint restored")
...
# if we want to run experiment on multiple GPUs we move the models there
net = torch.nn.DataParallel(net)
...
# typically we use tensorboardX to keep track of experiments
writer = SummaryWriter(...)
# now we start the main loop
n_iter = start_n_iter
for epoch in range(start_epoch, opt.epochs):
# set models to train mode
net.train()
...
# use prefetch_generator and tqdm for iterating through data
pbar = tqdm(enumerate(BackgroundGenerator(train_data_loader, ...)),
total=len(train_data_loader))
start_time = time.time()
# for loop going through dataset
for i, data in pbar:
# data preparation
img, label = data
if use_cuda:
img = img.cuda()
label = label.cuda()
...
# It's very good practice to keep track of preparation time and computation time using tqdm to find any issues in your dataloader
prepare_time = start_time-time.time()
# forward and backward pass
optim.zero_grad()
...
loss.backward()
optim.step()
...
# udpate tensorboardX
writer.add_scalar(..., n_iter)
...
# compute computation time and *compute_efficiency*
process_time = start_time-time.time()-prepare_time
pbar.set_description("Compute efficiency: {:.2f}, epoch: {}/{}:".format(
process_time/(process_time+prepare_time), epoch, opt.epochs))
start_time = time.time()
# maybe do a test pass every x epochs
if epoch % x == x-1:
# bring models to evaluation mode
net.eval()
...
#do some tests
pbar = tqdm(enumerate(BackgroundGenerator(test_data_loader, ...)),
total=len(test_data_loader))
for i, data in pbar:
...
# save checkpoint if needed
...
用 PyTorch 在多个 GPU 上进行训练
PyTorch 中有两种不同的模式去使用多个 GPU 进行训练。根据经验,这两种模式都是有效的。然而,第一种方法得到的结果更好,需要的代码更少。由于 GPU 之间的通信较少,第二种方法似乎具有轻微的性能优势。
分割每个网络的批输入
最常见的方法是简单地将所有网络的批划分为单个 GPU。
因此,在批大小为 64 的 1 个 GPU 上运行的模型将在批大小为 32 的 2 个 GPU 上运行。这可以通过使用 nn.dataparallel(model)自动包装模型来完成。
将所有网络打包到超级网络中并拆分输入批
这种模式不太常用。Nvidia 的 pix2pixhd 实现中显示了实现此方法的存储库。
什么该做什么不该做
避免在 nn.Module 的 forward 方法中使用 numpy 代码
numpy 代码在 CPU 上运行的速度比 torch 代码慢。由于 torch 的开发理念和 numpy 类似,所以 pytorch 支持大多数 numpy 函数。
将数据加载器与主代码分离
数据加载管道应该独立于你的主要训练代码。PyTorch 使后台工作人员可以更高效地加载数据,但不会干扰主要的训练过程。
不要每个步骤都输出结果日志
通常,我们对模型进行数千步的训练。因此,不要在每一步记录结果就足以减少开销。尤其是,在训练过程中将中间结果保存为图像成本高昂。
使用命令行参数
在代码执行期间使用命令行参数设置参数(批大小、学习速率等)非常方便。跟踪实验参数的一个简单方法是只打印从 parse_args 接收到的字典:
...
# saves arguments to config.txt file
opt = parser.parse_args()
with open("config.txt", "w") as f:
f.write(opt.__str__())...
如果可能,使用 .detach()从图表中释放张量
pytorch跟踪所有涉及张量的自动微分操作。使用 .detach()防止记录不必要的操作。
使用 .item()打印标量张量
你可以直接打印变量,但是建议使用 variable.detach()或 variable.item()。在早期的 pytorch 版本中,必须使用 .data 来访问变量的张量。
在 nn.Module 上使用 call 方法而不是 forward
这两种方法不完全相同,下面的例子就可以看出这一点:
output = self.net.forward(input)
# they are not equal!
output = self.net(input)
另外,原文中还有关于常见问题的解答,感兴趣的可以移步这里:
https://github.com/IgorSusmelj/pytorch-styleguide



