EfficientNet: 模型的联合等比例扩张

Overall
卷积网络出现以来,有很多工作来通过增大模型宽度,深度和输入图像的分辨率来获得更好的结果。但是,这几个因素其实是相辅相成的,论文[1]统一了这几个参数的变化,得到了EfficientNet,在图像分类领域又刷新了记录,成为了继AlexNet, VGG, ResNet, Inception, Xception, DenseNet, MobileNet, NASNet之后的又一经典网络结构。
模型尺寸变化
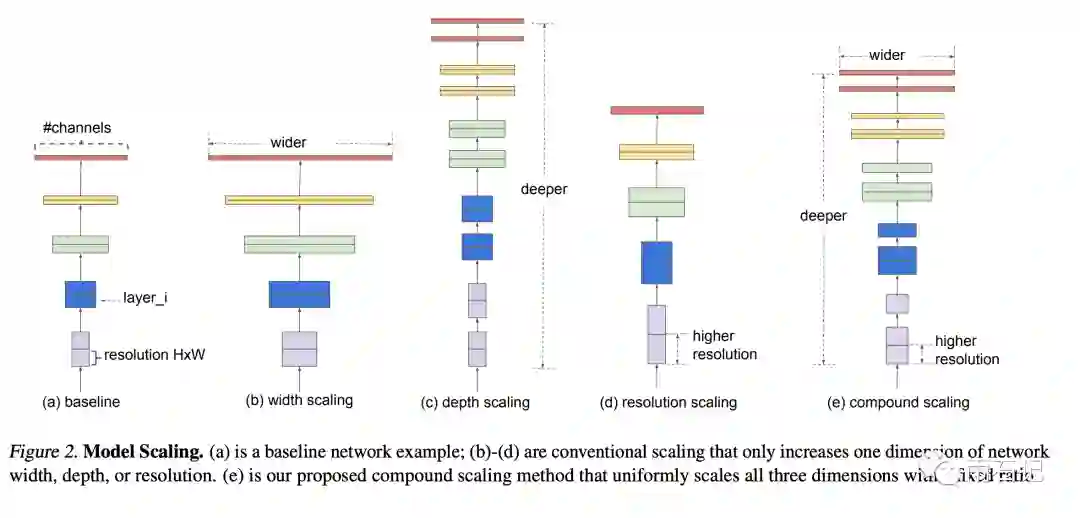
如上面所说,模型可以更宽,可以更深,也可以让输入图像变大。如下图所示:
-
更深: 最常见的改进模型的方法,但是加深后会遇到问题,梯度消失和增益消减。梯度消失问题会影响模型的训练,所以有了残差连接,批归一化等方式来缓解;增益消减是指模型深到一定程度后再继续增加效果的提升就不明显了比如ResNet就将模型从101层加深到了1000层,得到的准确率类似。 -
更宽: 很常见的改进模型的方法,常用于小尺寸的模型,加宽模型后能捕捉更多细粒度特征,训练起来也不会有太大的困难。但是一个宽而浅的模型是无法捕捉高级特征的。 -
更大分辨率: 一般来说,增大分辨率能带来模型效果的提升,所以经典网络的输入图像也是在变大,从最初的224x224,到299x299,再到331x331,480x480等。
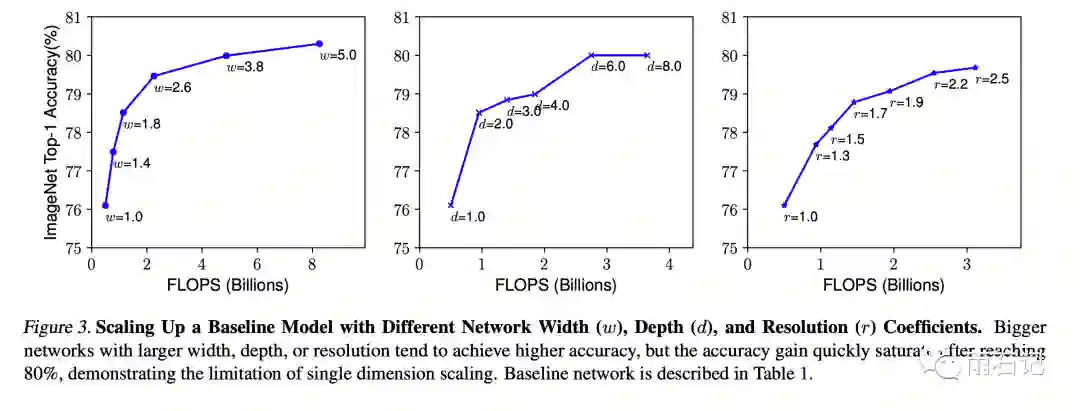
下图中反应了只改变一个方面,模型效果和计算量的关系图。可以看到,都是达到一定程度后,增长就变得很平缓。
联合等比例扩张问题建模
卷积可以看做是一个操作F,那么经过一个卷积层就是Yi=Fi(Xi)。很多经典网络比如ResNet的结构是层级制: 即在一个图像大小下,经过多层卷积,然后再将图像大小缩小,进入下一个层级。
所以,网络结构可以表示成:
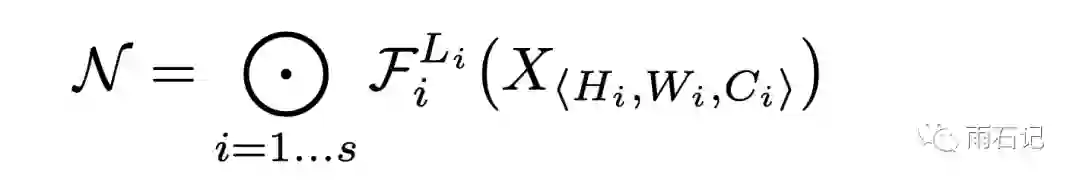
其中,L表示在某层重复卷积多少遍,H,W,C指的是在某层中间结果的长宽和通道数目。
所以问题就建模如下:

找到一组d,w,r,使得在满足内存和计算量的前提下,准确率最高。
更进一步的,这几个参数的变化是有关系的,比如当分辨率增大,一般需要加深层次来保证最后一层的视野域也等比例增大,从而捕捉类似的高级别特征,同样的也需要加宽来捕捉更多细粒度的特征。
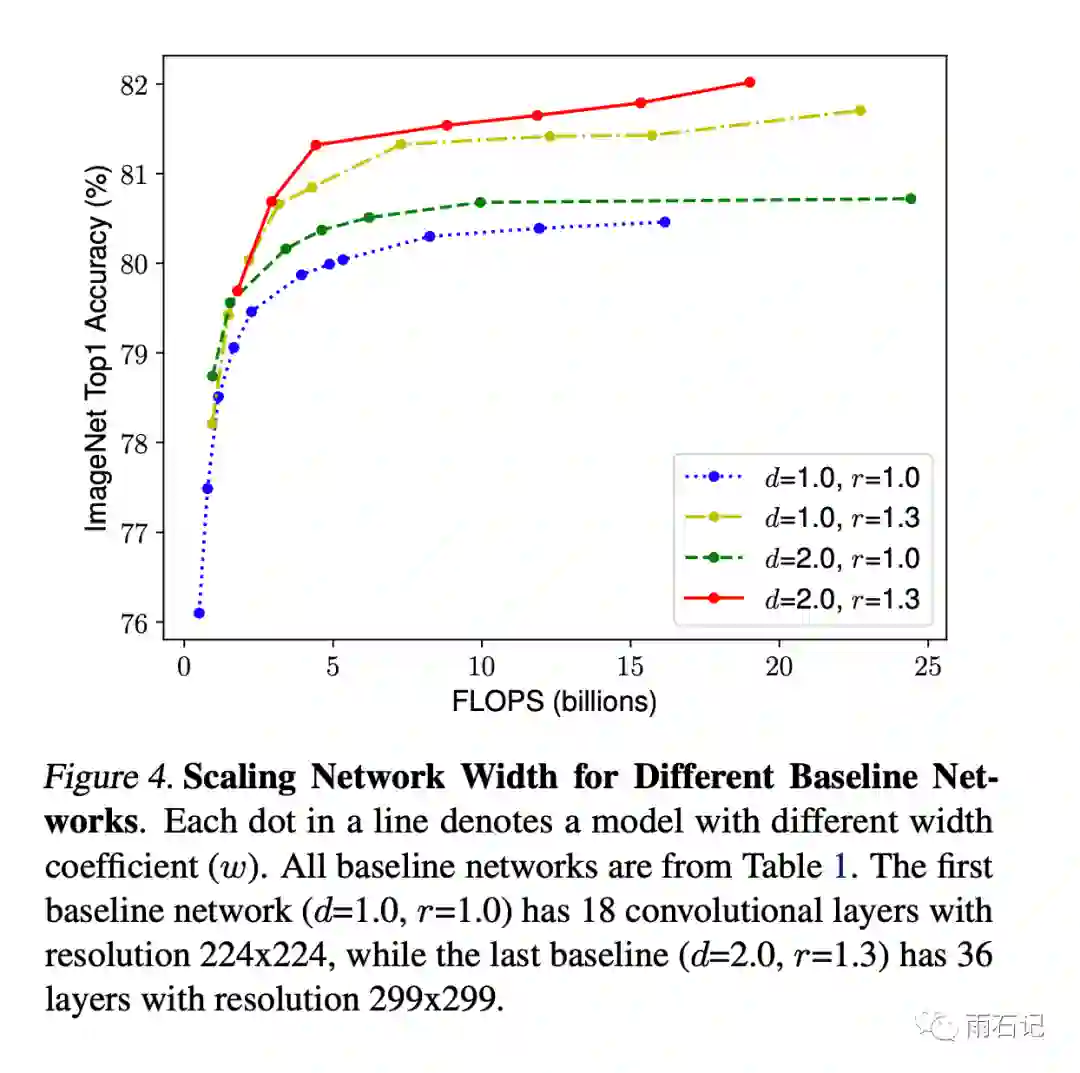
下图中反应了在给定几组d,r的值后,变化w得到的效果,可以看到,不同的参数组合得到的结果是不同的。
所以,进一步的,建模如下,假设alpha,beta,gamma都是定值,那么这个建模方法相当于把三个参数变成了一个参数phi。而alpha,beta,gamma的含义是,假设计算量能扩大2倍,那么有多少是分配给depth,width和resolution的。
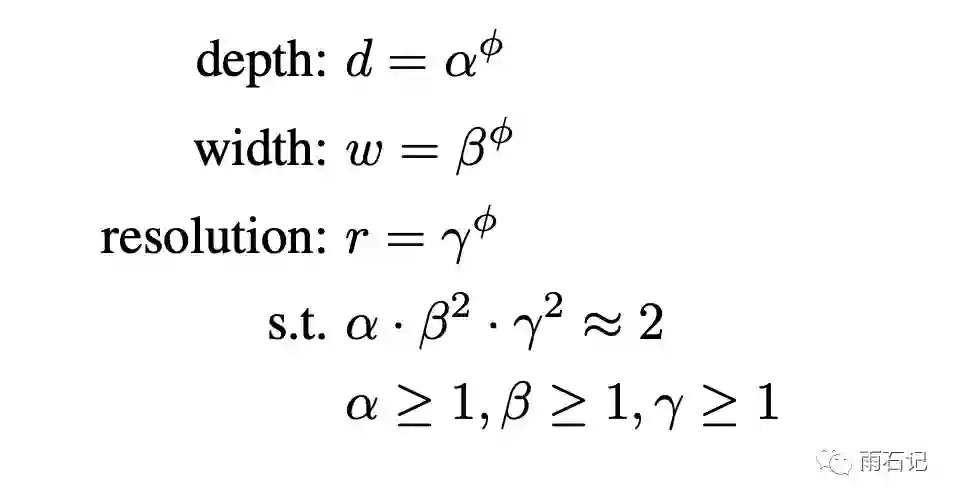
那么为什么alpha要和beta和gamma的平方去相乘呢,这是因为,深度增大为2倍,计算量会增大2倍,而宽度和resolution增大为2倍,计算量会增大4倍。所以beta和gamma做平方意味着深、宽和分辨率三个因素是等价的。
参数搜索
使用MnasNet方法搜索出来的模型作为baseline。
MnasNet稍后在另外的文章里展开讲。
然后使用两个阶段的方式来搜索参数。
-
令phi=1,假设有2倍资源,给alpha, beta和gamma做grid search,找到最优值为alpha=1.2, beta=1.1, gamma=1.15。得到EfficientNet-B0结构。 -
保持alpha,beta,gamma不变,增大phi,来得到不同的网络结构,即EfficientNet-B1到B7。
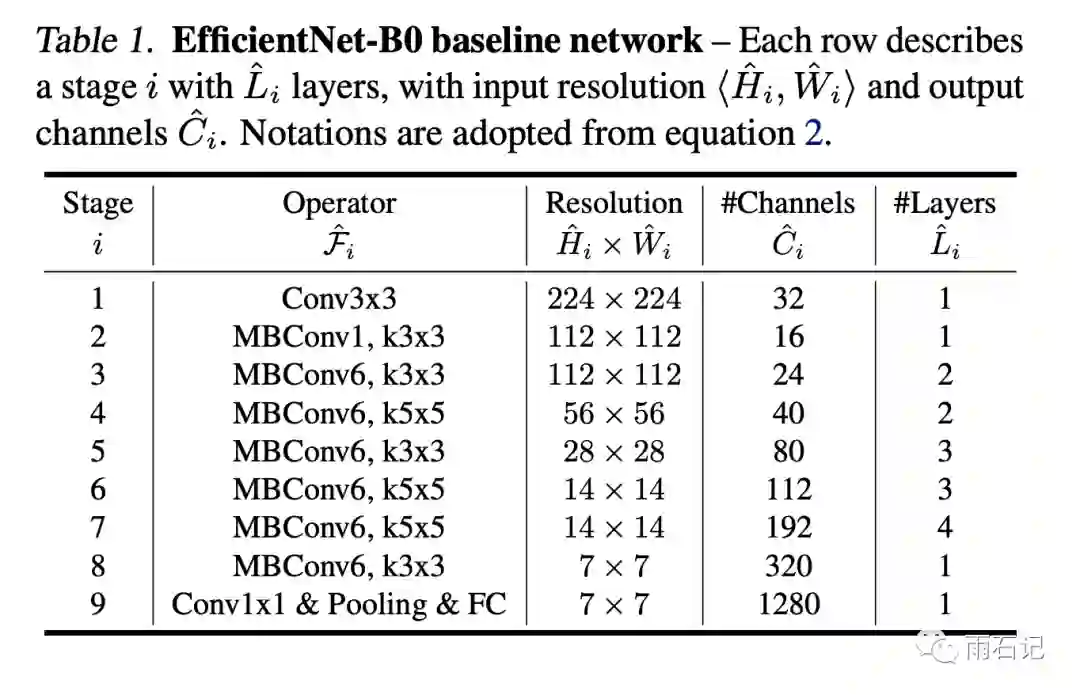
得到的网络结构如下:
EfficientNet与其他网络结构的对比
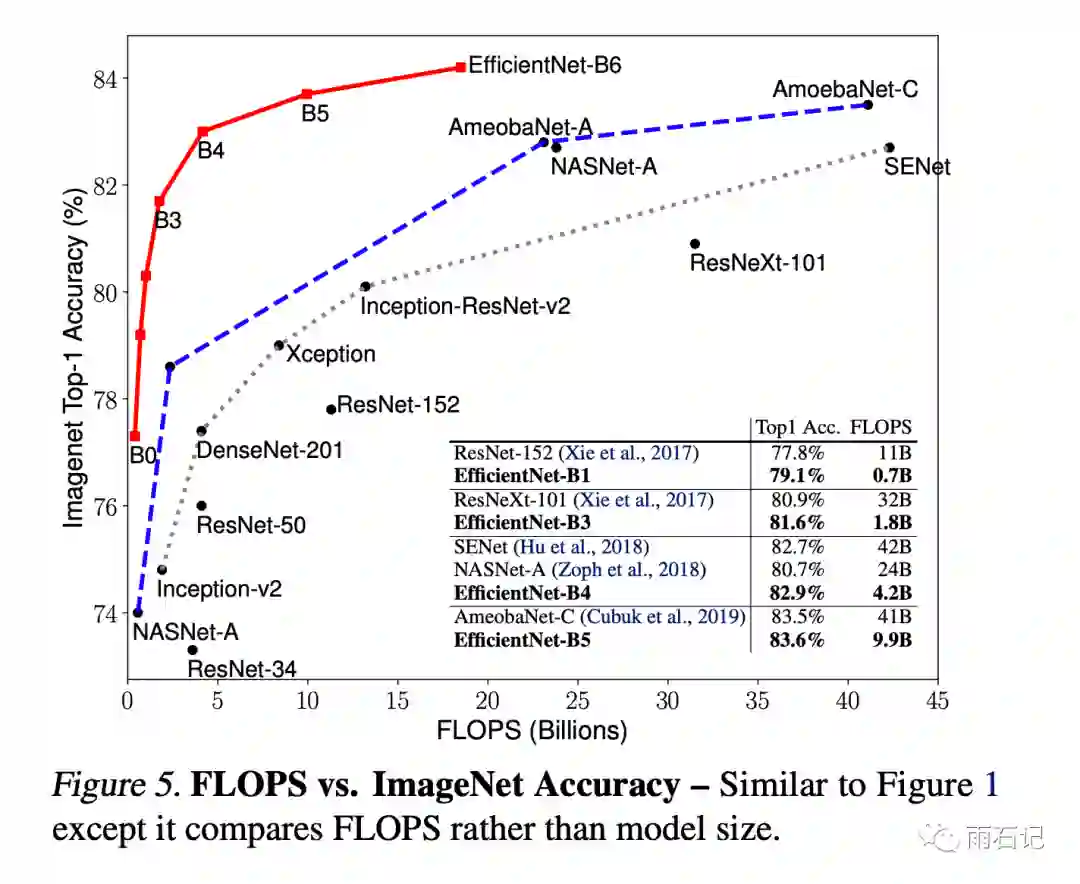
如下图,在同样的计算量下,EfficientNet系列明显能获得非常显著的提升。
参考文献
-
[1]. Tan, Mingxing, and Quoc V. Le. "Efficientnet: Rethinking model scaling for convolutional neural networks." arXiv preprint arXiv:1905.11946 (2019).
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏
