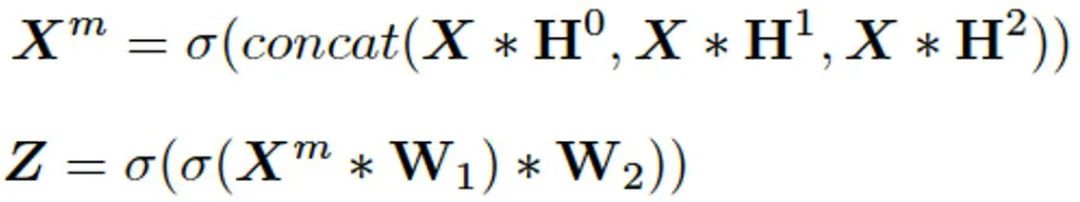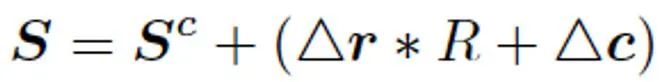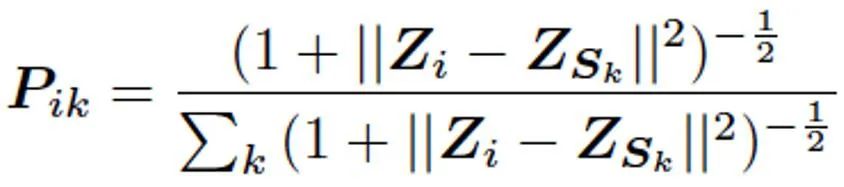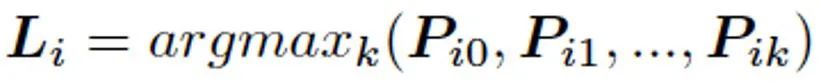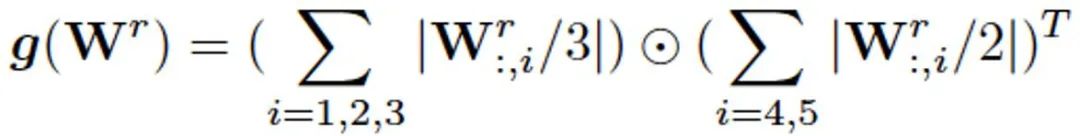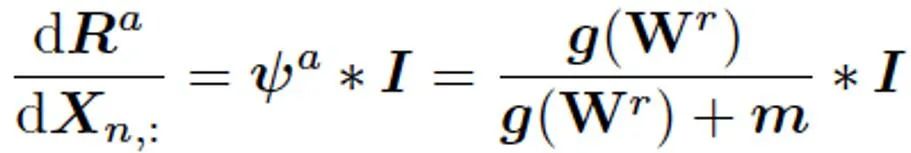利用持续学习中梯度缩放控制的方法,北大、北邮、字节跳动提出的新方法相比经典算法在参数量降低近 20 倍的同时,运算速度提升了 4 倍。
为解决在线学习所带来的灾难性遗忘问题,北大等研究机构提出了采用梯度调节模块(GRM),通过训练权重在特征重建时的作用效果及像素的空间位置先验,调节反向传播时各权重的梯度,以增强模型的记忆性的超像素分割模型 LNSNet。
该研究已被 CVPR 2021 接收,主要由朱磊和佘琪参与讨论和开发,北京大学分子影像实验室卢闫晔老师给予指导。
![]()
论文链接:https://arxiv.org/abs/2103.10681
项目开源代码:https://github.com/zh460045050/LNSNet
实验室链接:http://www.milab.wiki
图像分割是计算机视觉的基本任务之一,在自动驾驶、安防安保、智能诊疗等任务中都有着重要应用。超像素分割作为图像分割中的一个分支,旨在依赖于图像的颜色信息及空间关系信息,将图像高效的分割为远超于目标个数的
超像素块
,达到尽可能保留图像中
所有目标的边缘信息
的目的,从而更好的辅助后续视觉任务(如目标检测、目标跟踪、语义分割等)。
基于传统机器学习的超像素分割方法会将超像素分割看作
像素聚类问题
,并通过限制搜索空间的策略,提高超像素的生成效率(如 SLIC、SNIC、MSLIC、IMSLIC 等方法)。然而,这些方法大多依赖 RGB 或 LAB 颜色空间信息对像素进行聚类,而缺乏对高层信息的考量。
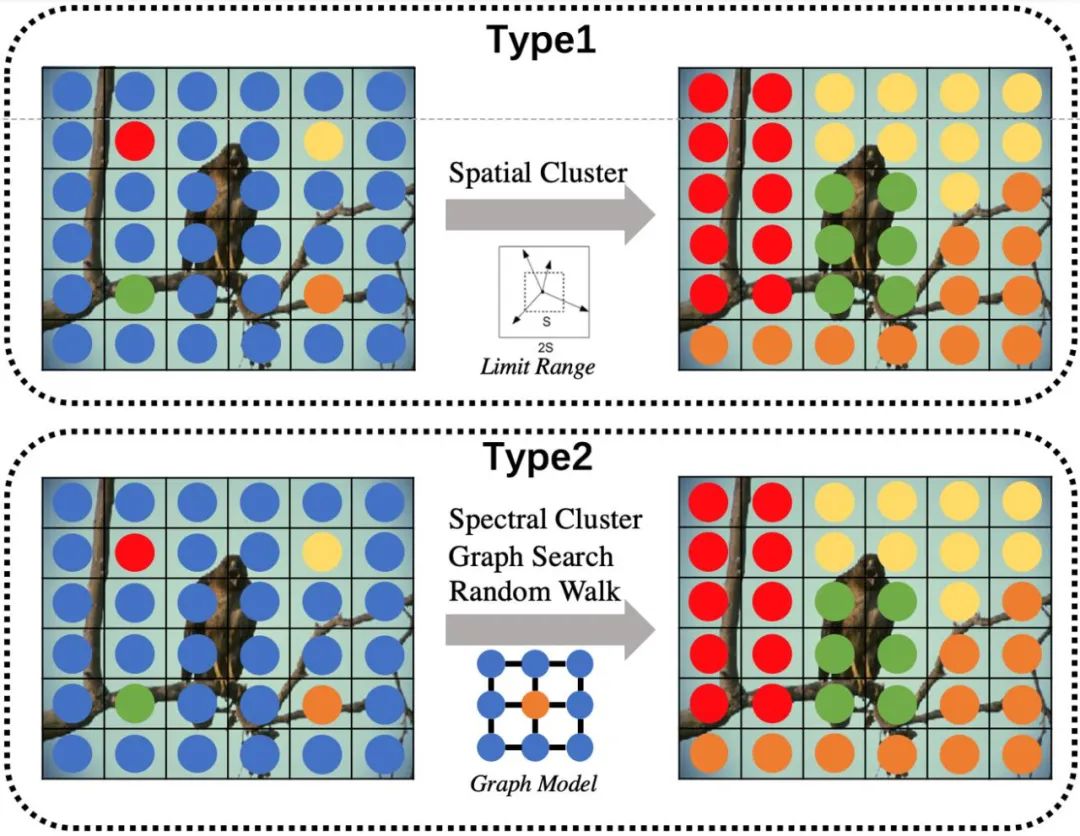
虽然一些超像素分割方法(LRW、DRW、ERS、LSC)通过构建图模型的方式,将原本 5 维的颜色及空间信息依据四邻域或八邻域节点的相似性关系丰富至 N 维,来获取更好的特征表达。进而使用随机游走或谱聚类等方式进行超像素分割,但这些方法运行效率较差。
![]()
采用卷积神经网络进行超像素分割(SEAL、SSN、S-FCN)大多抛弃了传统超像素方法的无监督的广义分割模式,转而采用大量的区域级的分割标注对卷积神经网络进行离线训练指导超像素的生成。这种基于标注的训练模式导致生成的超像素通常包含较多了高层语义信息,因此限制了超像素分割方法的泛化性及灵活性。
此外,这种超像素分割模式也无法较好的应用于缺乏分割标注的视觉任务,如目标跟踪、弱监督图像分割等。近期已有工作(RIM)借鉴深度聚类的模式无监督地运用神经网络进行广义超像素分割,然而该方法需要依据每一张输入图像训练一个特定的卷积神经网络进行像素聚类,因此极大地增加了超像素分割的运算时间。
![]()
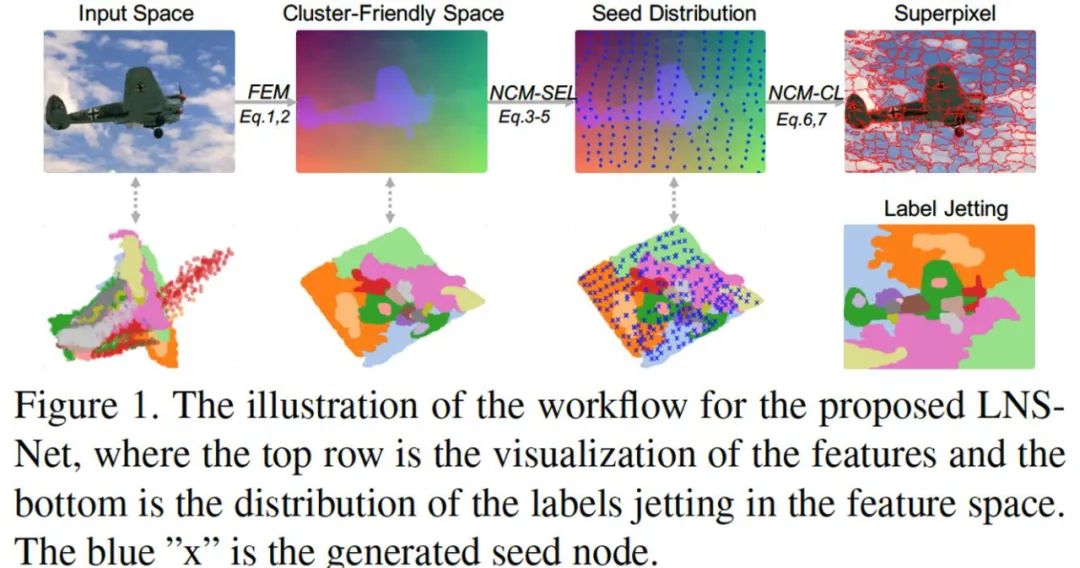
因此为保证超像素分割既可以更好的借助深度学习进行有效的特征提取,又可以同时兼顾传统超像素分割方法高效、灵活、迁移性强的特点,本研究从持续学习的视角看待超像素分割问题,并提出了一种新型的超像素分割模型可以更好的支持无监督的在线训练模式 (online training)。考虑到超像素分割作为广义分割问题需要更关注图像的细节信息,本模型摒弃了其他超像素分割网络中采用的较深而复杂的卷积神经网络结构,而选用了较为轻量级的特征提取模块(FEM),并提出了非迭代聚类模块(NCM)通过自动选取种子节点,避免了超像素分割方法中的聚类中心的迭代更新,
极大地降低了超像素分割的空间复杂度与时间复杂度(相比SSN参数量降低近20倍同时运算时间加快了近 4倍)
。
为解决在线学习所带来的灾难性遗忘问题,本模型采用了梯度调节模块(GRM),通过训练权重在特征重建时的作用效果及像素的空间位置先验,调节反向传播时各权重的梯度,以增强模型的记忆性及泛化性。
![]()
总的来看,在特定图像 Ii 上进行广义超像素分割的本质,可以看作在该图像域中的进行像素聚类任务 Ti。因此,对于包含 n 张图像的图像集 I={I1, I2, … In},在该图像集上的超像素分割任务可以看作任务集 T={T1, T2, … Tn}。在此条件下,我们可以将当前基于深度学习的超像素分割方法看作以下两种策略:
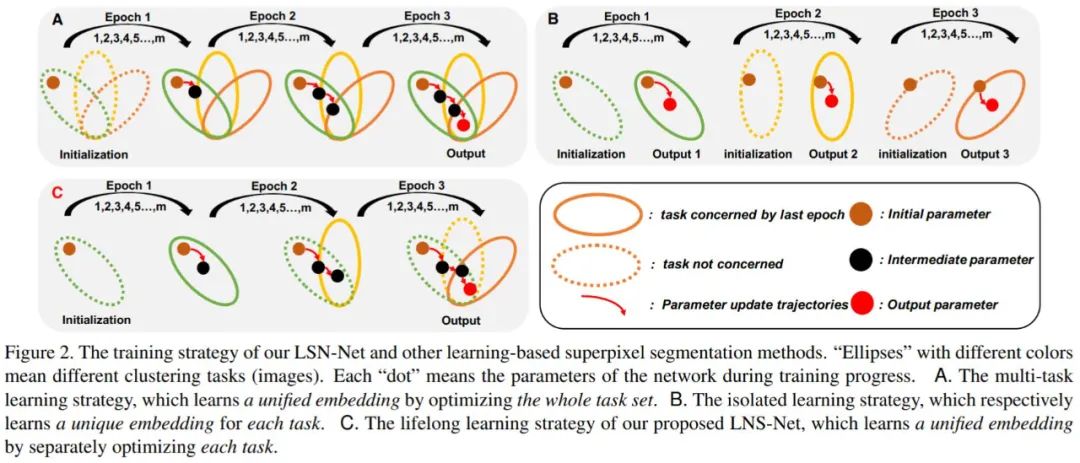
① 基于深度聚类模式的 RIM 超像素分割方法可以看作是一种单任务学习策略。如图 2B 所示,该策略针对任务集中每一个特定任务 Ti 找到一个最优的参数空间,因此整个任务集 T 来说,该任务需要训练得到 n 个各不相同的参数空间用以提取聚类特征。这种做法极大地增加了模型训练及存储的消耗,导致其运算效率极低。
② 其他超像素分割网络的训练模式(SEAL、SSN、S-FCN)则可以看作一种多任务学习策略。如图 2A 所示,该策略在分割标注的指导下得到一个对于整个任务集 T 通用参数空间。虽然这种策略仅需要得到一个参数空间,但该方式仍需要离线的进行模型训练,且训练过程都需要维护整个图像集 I。此外,这些方法对于分割标签的需求也导致其过于关注提取更高层语义特征,而非关注对于广义超像素分割来说更重要的低层颜色特征与空间特征的融合,限制了卷积神经网络的迁移性及灵活性。
与这两种方式不同,本文希望利用持续学习策略,保证超像素分割方法既可以既借助卷积神经进行更为有效的特征提取,又同时兼顾传统超像素分割方法高效、灵活、迁移性强的特点。
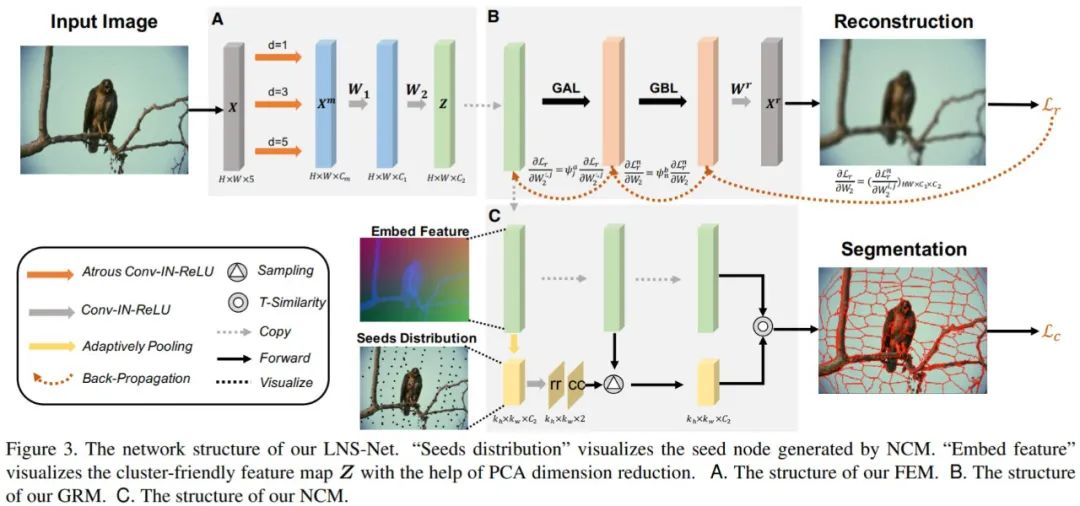
如图 2C 所示,本文所采用的持续学习策略通过逐一针对特定图像 Ii 进行训练,保证最终可以得到一个适用于整个任务集 T 的通用参数空间,这要求了卷积神经网络需要具备记忆历史任务的能力,也就是解决持续学习中的灾难性遗忘问题。本模型的具体训练流程如图 3 所示,在第 i 轮的训练过程中,我们仅考虑单一的任务 Ti 对模型进行拟合。其中,特征提取模块 FCM 用于生成聚类所需的聚类特征,无迭代聚类模块 NCM 进而利用聚类特征进行聚类得到超像素分割结果。梯度调节模块 GRM 则用以调节反向传播时 FCM 参数的梯度,保证模型可以更好的记忆历史任务 Ti-1,Ti-2,….. , T1。
![]()
本文提出的模型结构如图 3 所示,其中考虑到超像素分割作为广义分割问题更为关注图像的细节信息与空间信息的融合。因此本模型在特征提取模块 FEM(图 3A)部分摒弃了其他超像素分割网络中采用的较深而复杂的卷积神经网络结构,转而使用较为轻量级的特征提取模块,以减少在特征提取过程中图像细节信息的损失。具体来看,我们首先将输入图像颜色信息 RGB/LAB 及空间信息 XY 进行 Concat 得到 5 维的输入张量 X。随后我们使用三个不同空洞率 (d=1,3,5) 的空洞卷积进行多尺度的特征提取,并采用两个 3x3 卷积模块进行多尺度特征融合,进而得到用以进行聚类的输出特征图 Z:
![]()
接着,进一步增加过程的运算效率,我们提出了无迭代聚类模块 NCM(图 3C)通过生成种子节点相对于网格中心的横纵坐标偏移量,保证种子节点在具有较强空间紧凑程度的前提下,预测相应超像块的种子节点,并依据其与各像素聚类特征间的 T 相似性进行像素聚类。该模块首先将图像按照超像素个数进行网格划分,进而对属于同一网格的位置进行空间池化操作,得到空间尺寸等于超像素个数的低分辨特征图作为网格的特征 Zk。随后,我们将 Zk 输入 out channel 为 2 的 1x1 卷积得到种子节点相对于网格中心的横纵偏移量△r,△c,并将此叠加至网格中心坐标 Sc 最终的超像素种子节点:
![]()
随后,我们利用 T - 分布核函数计算种子节点特征与其余像素特征的相似性,并以此为依据得到最终的像素聚类结果 L,也就是输出超像素块。
![]()
![]()
最后,梯度调节模块 GRM(图 3B)首先利用像素聚类特征进行对输入图像及其各像素的空间信息进行重建。其中梯度自适应层(GAL)依据重建结果计算 FEM 中各通道对于当前任务的拟合程度 g(W^r),具体来看,我们分别依据重建权重 W^r 判断各 Z 中特征通道分别在颜色信息和空间位置复原中的重要性,并利用二者乘积表示该通道的拟合程度:
![]()
随后,在训练过程中 GAL 通过维护记忆矩阵 m 用以记忆各通道在前序任务中的拟合程度。
随后在反向传播过程中,我们对各通道所对应的 FEM 中权重矩阵依据前序任务的重要程度构建调节率φ^a,用以调节对各通道所对应权重的梯度:
![]()
该调节率可以保证对于历史任务拟合程度较好的权重具有较小的梯度,从而避免对于在前序任务中拟合程度高而在当前任务中拟合程度低的权重在反向传播过程中受到污染,进而防止 FEM 过拟合当前任务造成对前序任务的造成灾难性遗忘。此外,GRM 还采用了梯度双向层(GBL)借助边缘先验信息使得平滑位置超像素块可以更多的关注空间信息,而纹理丰富位置超像素块可以更多考虑颜色信息,达到减少冗余超像素块、增强边缘拟合性的目的。
模型训练的损失函数包含两个部分,其中第一个部分为重建损失 Lr。该部分通过 MSE 损失保证聚类特征可以重建回初始图像及各像素对应的空间位置信息,从而使得聚类特征可以更好的对空间信息及颜色信息进行融合。第二部分为聚类损失 Lc,该部分在 DEC 聚类损失的基础上增加了空间距离约束。该约束可以在保证各超像素块中像素类内相似性大的同时,使得每一像素更趋向于被分配到与其空间距离前 k 近的种子节点所在超像素中,从而保证分割结果中超像素块的紧凑程度。
![]()
总的来看我们的方法相比于 SOTA 的超像素分割方法,具有更高的效率及可迁移性。
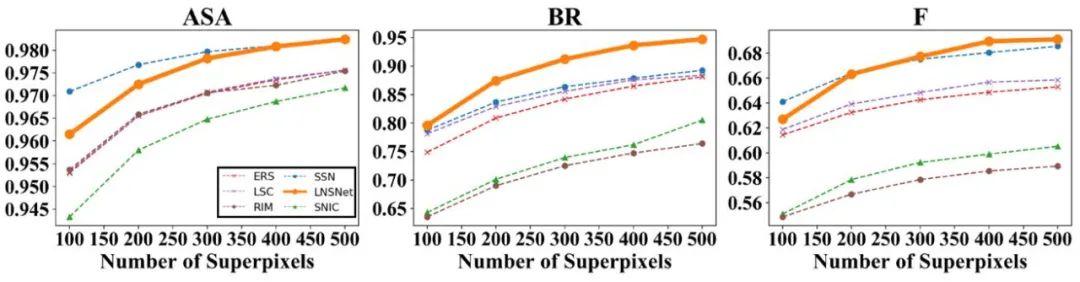
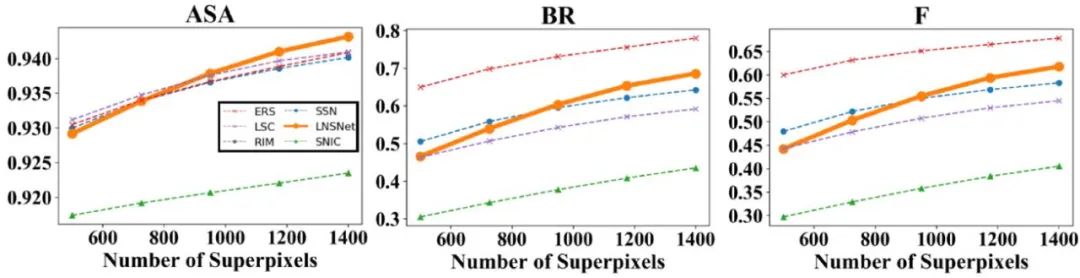
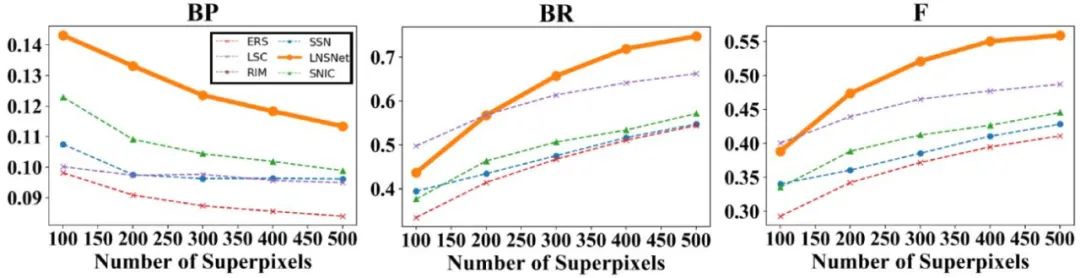
首先,我们在 BSDS 数据集上进行了实验,可以看到我们提出的超像素分割策略在 ASA、BR、F 等常用超像素评价指标中都远高于其余无监督的超像素分割方法(包括传统方法 SLIC、LSC、ERS,RIM)。此外,相比于依赖分割标签的有监督超像素分割方法 SSN,由于我们的方法在训练过程中无法感知到高层语义信息,导致分割结果会产生相对较多的冗余超像素块,这点造成了我们的方法的分割精确性较低,因此在 ASA 及 F 指标中略低于 SSN。然而这一特点也使得我们的模型具有更好的分割召回率,对于一些复杂场景中的模糊边缘的拟合性更好,因此我们的方法可以取得更高的 BR 指标
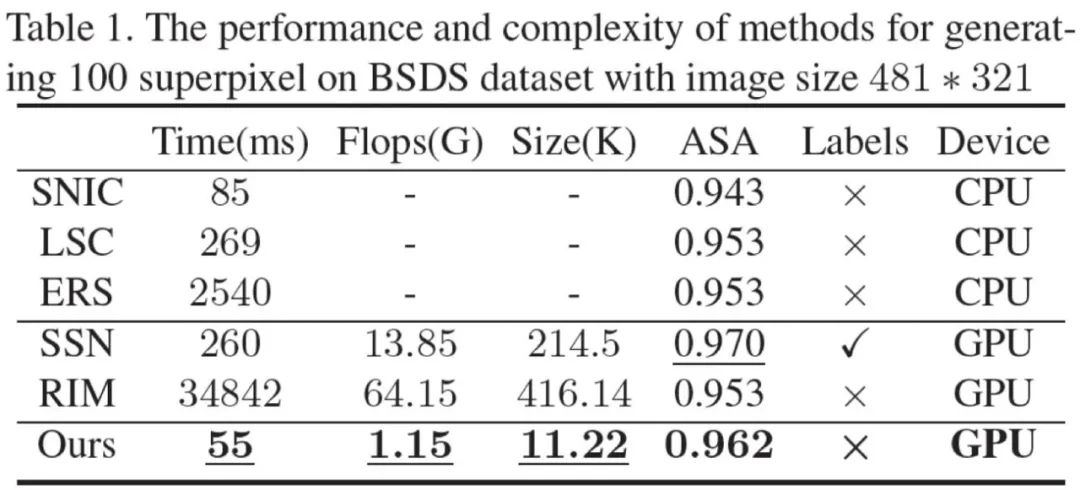
此外,由于使用了更为轻量级的特征提取器,并采用无迭代的聚类模式,我们模型在时间、空间复杂度上远低于其余基于卷积神经网络的超像素分割方法。此外,我们也将 BSDS 数据集中训练好的超像素分割模型应用在医学影像中进行实验,以测试各超像素分割模型的迁移性。可以看到,无论是对于眼底荧光造影中眼底血管分割数据集(DRIVE)还是 OCT 影像中视网膜层分割数据集(DME),我们的模型都比其他基于卷积神经网络分割模型具有更好的迁移性。
![]()
![]()
![]()
![]()
建新·见智 —— 2021亚马逊云科技 AI 在线大会
4月22日 14:00 - 18:00
为什么有那么多的机器学习负载选择亚马逊云科技?大规模机器学习、企业数字化转型如何实现?
《建新 · 见智——2021 亚马逊云科技 AI 在线大会》由亚马逊云科技全球人工智能技术副总裁及杰出科学家 Alex Smola、亚马逊云科技大中华区产品部总经理顾凡领衔,40多位重磅嘉宾将在主题演讲及6大分会场上为你深度剖析亚马逊云科技创新文化,揭秘 AI/ML 如何帮助企业加速创新。
分会场一:亚马逊机器学习实践揭秘
分会场二:人工智能赋能企业数字化转型
分会场三:大规模机器学习实现之道
分会场四:AI 服务助力互联网快速创新
分会场五:开源开放与前沿趋
分会场六:合作共赢的智能生态
6大分会场,你对哪个主题更感兴趣?
识别二维码或点击阅读原文,免费报名看直播。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com