实录 | DSTC 8“基于Schema的对话状态追踪”竞赛冠军方案解读

本文将回顾平安人寿近期在 PaperWeekly 直播间进行的主题为「DSTC 8“基于 Schema 的对话状态追踪”竞赛冠军方案解读」的技术分享,由平安人寿 AI 团队高级算法工程师马跃老师主讲。

比赛介绍

▲ 图1 : 平安人寿AI团队斩获DSTC 8 Track4赛事冠军
1.1 背景简介
1.2 任务介绍
b)意图集合,以 FindAttractions 意图为例,有:
-
意图名称:FindAttractions -
意图描述:一句自然语言描述当前意图,如:Browse attractions in a given city -
必须填充的槽位集合:完成这个意图必须填充的槽位 -
可选槽位集合:非必须填充槽位
c)槽位集合,对于每一个槽位,有以下信息:
槽位名称,如 number_of_person
槽位描述:一句自然语言描述当前槽位,如:Number of people to find tickets for
是否可枚举:不可枚举槽位的取值为对话上下文的片段;可枚举槽位的取值只能为 Possible_values 中的一个
Possible_values:如果为可枚举槽,则有一个预定义好的槽值集合,如 [1,2,3,..,9];如果为不可枚举槽,则无该字段。
已知的所有必须填充槽位的槽值
-
如果为不可枚举槽位,且槽值位于当前用户的表达内容中,还需要给出槽值在用户表达中的具体起止位置信息
1.3 比赛挑战

解决方案介绍
2.1 可枚举槽位 vs. 不可枚举槽位
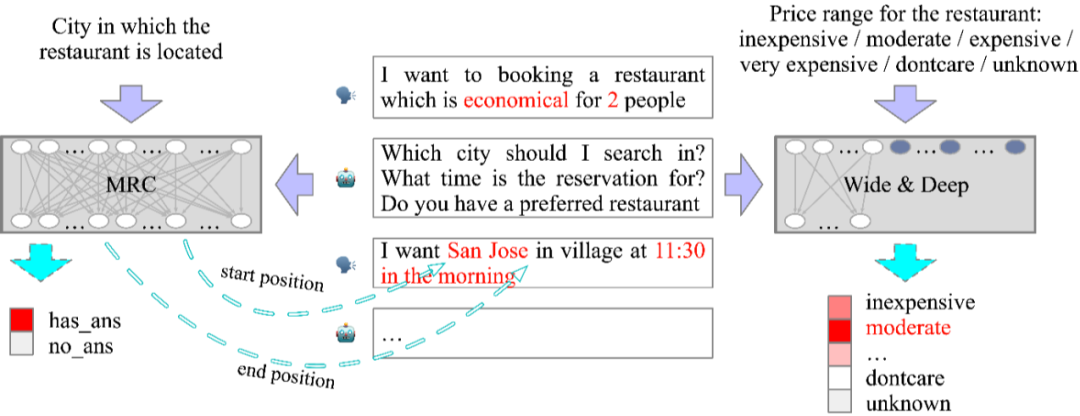
▲ 图2 : 整体结构
2.2 MRC-DST
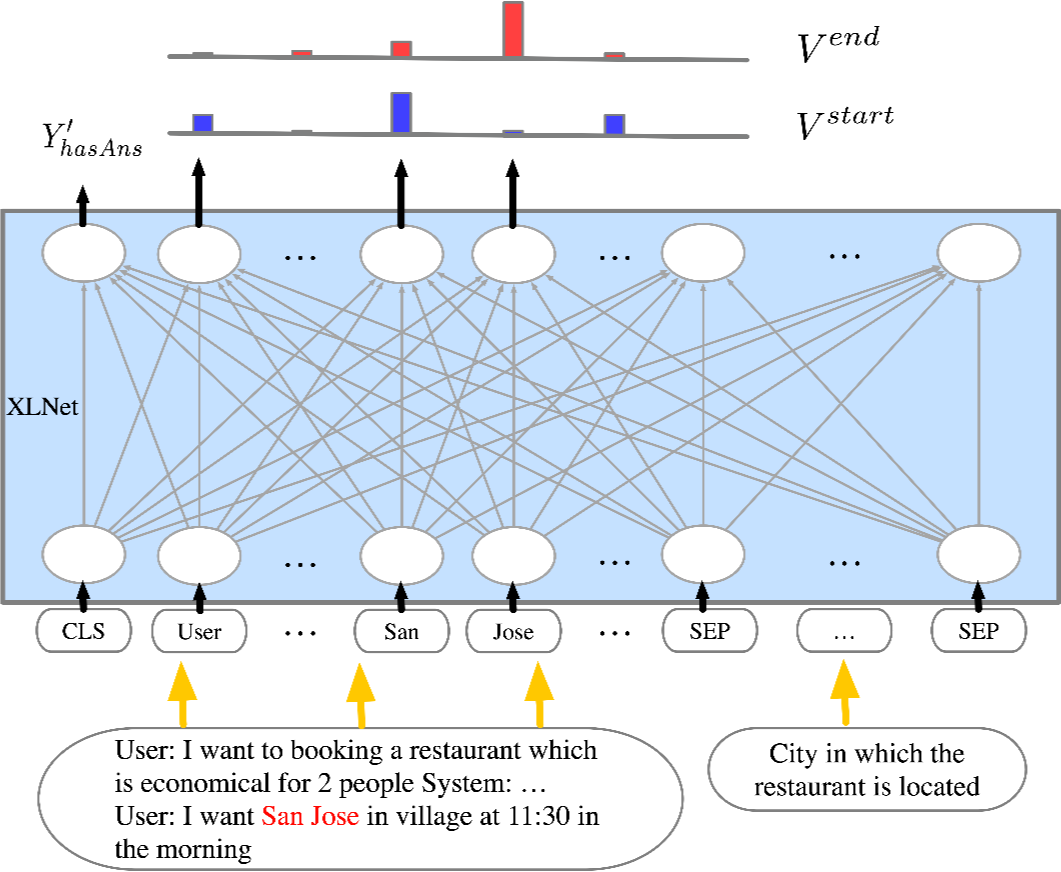
▲ 图3 : MRC-DST模型结构,包括两部分输入,对话历史上下文信息和问题(槽位描述)
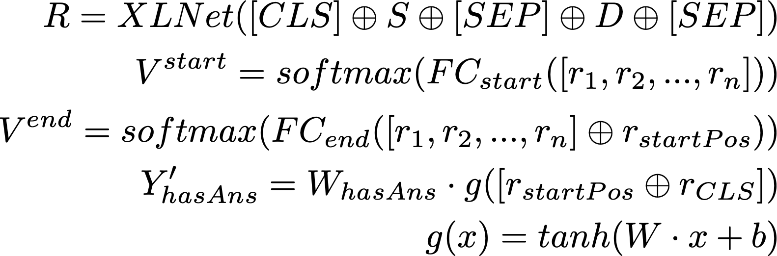
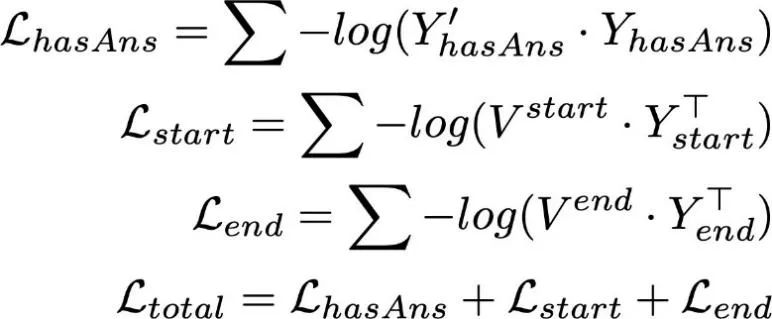
2.3 WD-DST
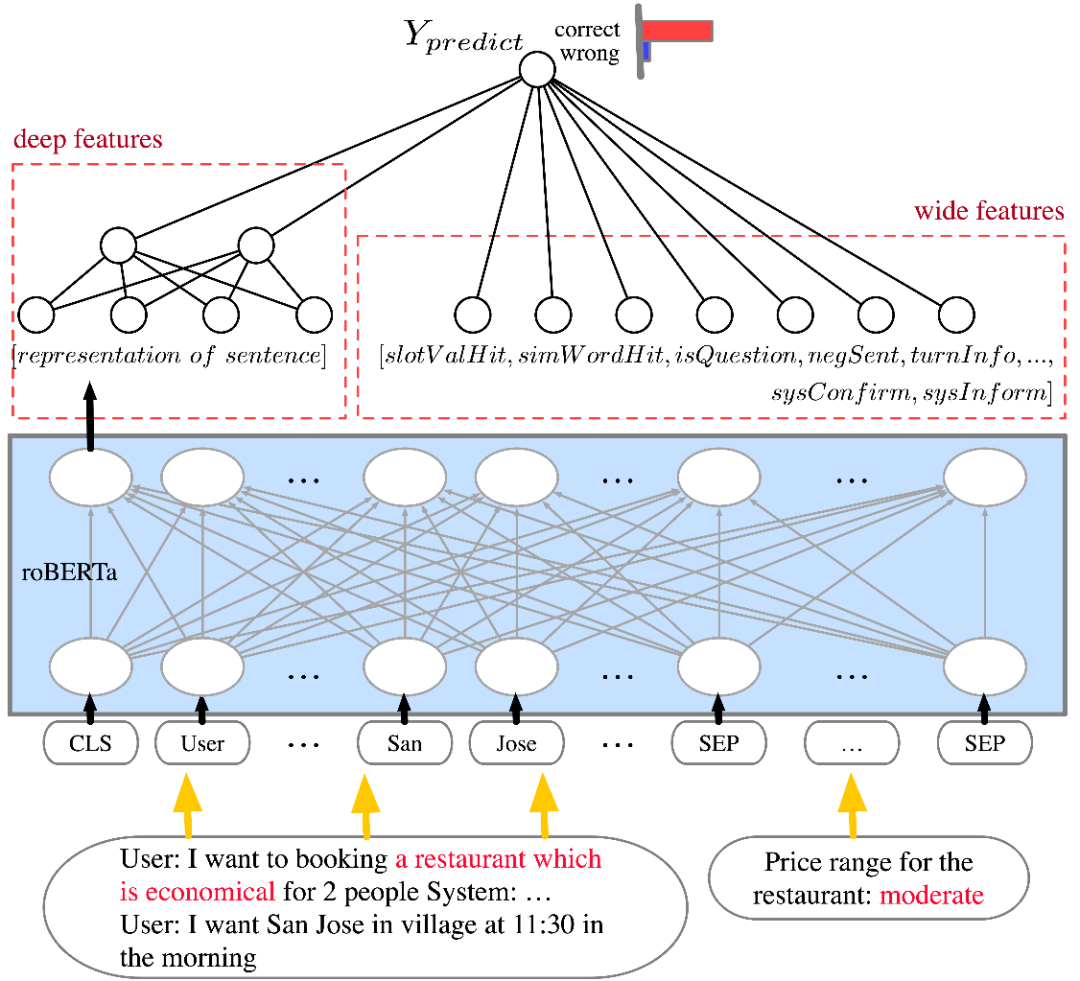
▲ 图4 : WD-DST模型结构,包括三部分输入,对话历史上下文信息、问题(槽位描述)与需要判断的槽值、离散特征
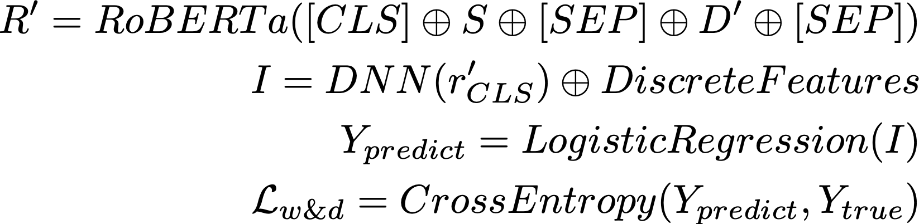
2.4 数据增强
2.5 模型拓展与思考
当决策性信息处于上下文末端时(一般为用户表达的最后一句话提及了槽值信息),MRC 和分类模型都容易预测错误。针对这个现象,我们直接将用户表达的最后一句话复制并拼接在末端的方法来解决,相当于直接把上下文有效内容前置。
数据预处理中,我们使用统一的标签来替换具有干扰性的信息,如电话号码。
-
同一个模型,不同次 Fine-tuning,他们的错误 case 不同。针对这个问题,使用最简单的 Ensemble 想法来解决,使用多个模型投票的策略来确定最终槽值。

应用价值

参考文献
[1] Gao et al. "Dialog state tracking: A neural reading comprehension approach." arXiv 2019.
[2] Wu et al. "Transferable Multi-Domain State Generator for Task-Oriented Dialogue Systems" ACL 2019.
[3] Chao and Lane, "BERT-DST: Scalable End-to-End Dialogue State Tracking with Bidirectional Encoder Representations from Transformer", INTERSPEECH 2019.
[4] Cheng et al. "Wide & deep learning for recommender systems", Proceedings of the 1st workshop on deep learning for recommender systems. 2016.
[5] Rastogi et al. "Towards scalable multi-domain conversational agents: The schema-guided dialogue dataset." arXiv 2019.
[6] Zhang et al. "Find or classify? dual strategy for slot-value predictions on multi-domain dialog state tracking." arXiv 2019.
[7] Ma et al. "An end-to-end dialogue state tracking system with machine reading comprehension and wide & deep classification." AAAI 2020 DSCT 8 Workshop.
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。



