Facebook田渊栋开源游戏平台ELF,简化版《星际争霸》完美测试人工智能

选自Facebook
作者:田渊栋
机器之心编译
参与:李泽南、李亚洲
在人工智能有能力进入现实世界之前,游戏是一种完美的测试环境。此前,谷歌 DeepMind 曾经宣布正在和暴雪共同研究能打《星际争霸》的人工智能,OpenAI 开源了人工智能测试环境 Universe。最近,Facebook 也宣布了自己的人工智能游戏测试平台 ELF。田渊栋等人在其介绍论文中表示,新的测试平台可以支持三种游戏形式:RTS、夺旗游戏和塔防,同时也开放物理引擎。该平台现已开源。
游戏是人工智能研究的完美实验环境。在游戏环境中,可用于训练人工智能模型的数据是近乎无限、低成本、可复制,相比现实世界的经验更容易获得。这些特点正帮助 Facebook 人工智能实验室(FAIR)探索一些短期目标,如复杂游戏环境中多个人工智能的能力;以及长期目标:让人工智能应对现实世界的挑战。游戏研究可以帮助我们构建能够进行计划、具有理性、自我导航、解决问题、合作与交流的人工智能。
尽管使用游戏进行训练能够带来多种好处,但研究者们在游戏环境中进行探索可能会遇到很多困难。由于目前机器学习算法的诸多限制,训练需要成百上千的游戏局数,这需要大量的计算资源,如配备大量 CPU、GPU 或定制硬件的高性能计算平台。此外,这些算法是复杂而难以进行微调的。而随着训练环境中增加更多的人工智能代理,这些变量将更加难以控制。
为了解决这些问题,让所有人都能参与人工智能的研究。FAIR 团队创造了 ELF:一个大范围、轻量级且易于使用的游戏研究平台。ELF 可以让研究者们在不同的游戏环境中测试他们的算法,其中包括桌游、Atari 游戏(通过 Arcade Learning Environment),以及定制的即时战略游戏(RTS)。它们可以运行在带有 GPU 的笔记本电脑上,而且支持在更为复杂的游戏环境中训练 AI,例如即时战略游戏——仅仅使用 6 块 CPU,一块 GPU,花上一天时间。
FAIR 的研究者们将 ELF 的界面设计得易于使用:ELF 在 C/C++界面中运行所有游戏,自动处理并发问题如多线程/多任务。另外,ELF 还有一个纯净的 Python 用户界面,提供了一批可供训练的游戏状态。ELF 也支持游戏以外的用途,它包括物理引擎等组件,可以模拟现实世界的环境。
目前,ELF 平台已经开源,开发者和研究者们可以在 GitHub 中找到它:https://github.com/facebookresearch/ELF
相关论文也已发表在 arXiv 中:https://arxiv.org/abs/1707.01067
架构
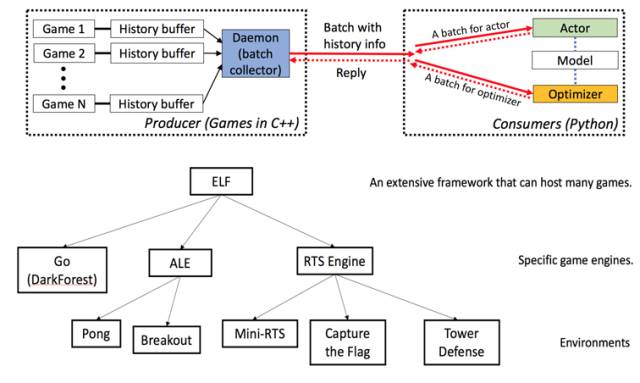
ELF 的架构相对简单,它包含一个能够主持多个在 C++端运行并发游戏示例的模拟器,同时在 Python 端与 AI 模型(深度学习、强化学习等)沟通。
与其他在一个界面包含单个游戏的 AI 平台不同,ELF 能把一批游戏包括进一个 Python 界面。这使得模型和强化学习算法能够在每次迭代中包含一批游戏状态,降低了训练模型所需的时间。
我们也在游戏推断和参与者模型(actor model) 之间建立配对灵活性。使用该框架,非常容易用一个参与者模型配对特定的游戏示例,或者一个示例配对许多参与者模型,或者许多示例配对一个参与者模型。这样的灵活性能够快速的构建算法原型,帮助研究员更快地理解哪个模型有更好的表现。
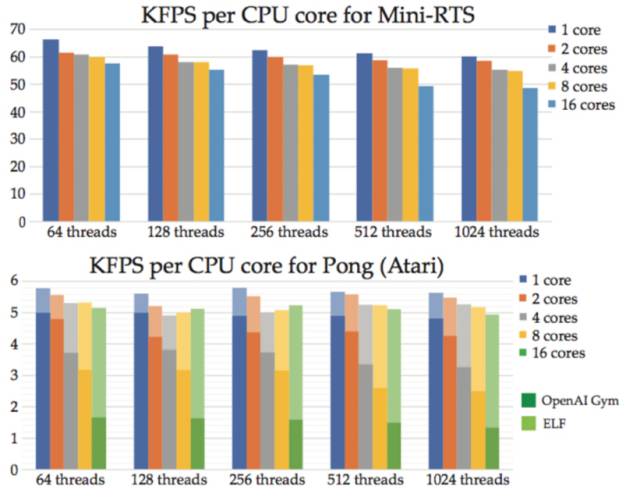
在 FAIR 早期的实验中,ELF 能进行更快的模拟,使用同样数量的 CPU 和 GPU 相比于 OpenAI Gym 玩 Atari 游戏可以提高 30% 的训练速度。当增加更多的核心之后,ELF 每核的帧率保持稳定。
Mini-RTS:实时策略游戏进行研究
ELF 平台包括一个名为 Mini-RTS 的实时策略引擎与环境。我们写 Mini-RTS 是为了帮助测试 ELF,它非常的快,在 Macbook Pro 上每核每秒运行 4 万帧。它能捕捉实时策略游戏的关键动态:两个玩家同时收集资源、建立设施、探索未知领地,并尝试控制地图上的领地。此外,该引擎能够加速人工智能研究:完美的保存、加载、回放,完全可接入其游戏内部状态,多个内建式角色 AI,调试可视化、人类-AI 界面,等等。作为基准,我们在 Mini-RTS 上训练的人工智能展现出了惊人的结果,它可以在 70% 的对局中击败内建式 AI。这些结果显示,训练人工智能完成任务,并在相对复杂的策略环境中优先排序行为是可能的。
有了 ELF 平台,我们期待它能帮助计算机处理指数级行为空间、长期延时奖励和不完美信息。

论文:ELF: An Extensive, Lightweight and Flexible Research Platform for Real-time Strategy Games

摘要:在本论文中,我们提出了 ELF,一个大范围、轻量级且易于使用的强化学习研究平台。在 ELF 中,我们可以通过高度定制化的即时战略游戏(RTS)引擎,实现三种游戏环境(Mini-RTS、夺旗游戏和塔防游戏)。Mini-RTS 是简化版的《星际争霸》,捕捉游戏动态,并可以在 MacBook Pro 笔记本上以每核心 40K 帧率(FPS)的速度运行。结合现代强化学习的方法,该系统可以在一天内使用 6 块 CPU 和 1 块 GPU 对内置 AI 进行端到端的训练。
此外,我们的平台在环境代理通信拓扑、强化学习方法选择、游戏参数调整等方面上是灵活的,而且可以承载现有的 C/C++游戏环境如 Arcade Learning Environment。通过 ELF,我们彻底探索了训练环境,并展示了 Leaky ReLU 和 Batch Normalization 与长期训练和渐进式课程体系的结合超过了基于规则的内建 AI,在超过 70% 的 Mini-RTS 游戏中获得了胜利。它在其他两种游戏中也能达到相似的水平。在游戏的 Replay 中,我们可以看到人工智能代理展示了有趣的策略。ELF 和它的强化学习平台将会开源。

原文地址:https://code.facebook.com/posts/132985767285406/introducing-elf-an-extensive-lightweight-and-flexible-platform-for-game-research/
本文为机器之心编译,转载请联系本公众号获得授权。


点击下方“阅读原文”下载同声译
↓↓↓