超越MobileNetV3!谷歌大脑提出 MixNet 轻量级网络,已开源!
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:Happy
https://zhuanlan.zhihu.com/p/75242090
本文已由作者授权,未经允许,不得二次转载
MixNet: Mixed Depthwise Convolutional Kernels
arXiv:https://arxiv.org/abs/1907.09595
https://github.com/tensorflow/tpu/tree/master/models/official/mnasnet/mixnet
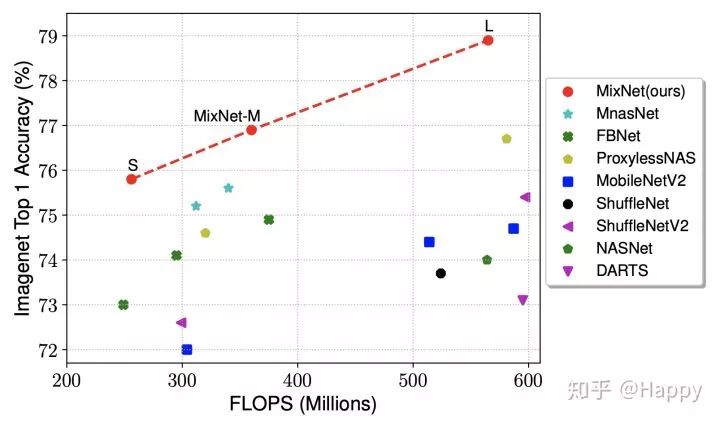
本文是谷歌大牛Quoc V. Le的在AutoML领域的又一力作。 下图给出了它同其他NAS所搜索网络在性能、FLOPs方面的对比,从中可以看出:MixNet取得完胜 。
深度分离卷积在当前轻量型ConvNets得到广泛应用,但其卷积核尺寸却很少得到关注,甚至被忽视。 作者系统的分析了卷积核尺寸的影响,同时发现,组合多尺寸卷积核可以取得更好的精度与效率。 基于此,作者提出一种新的混合深度卷积(Mixed Depthwise Convolution, MDConv),它很自然的将多个尺寸卷积核混叠到同一个卷积中。 通过简单的替换原始深度分离卷积,它可以帮助MobileNet在ImageNet分类与COCO目标检测任务中取得精度与效率的提升。
通过集成MDConv到AutoML框架中,作者进一步研发一种新的模型:MixNets。 它优于已有轻量型网络,包含MobileNetV2(+4.2%), ShuffleNetV2(+3.5%), MnasNet(+1.3%), ProxylessNas(+2.2%), FBNet(+2.0%)。 特别的,MixNet-L取得了78.9%的top-1分类精度(ImageNet),同时FLOPs小于600M。
Background
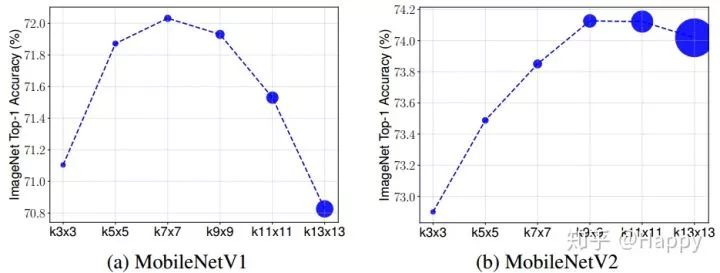
深度分离卷积是设计轻量型网络的重要组件之一,但是其卷积核的重要性却往往被忽视,而是简单的采用$3 \times 3$大小的核。近期研究表明:更大的核,如$5 \times 5, 7\times7$可以进一步提升模型的精度与效率。
作者对该问题进行了研究与分析:更大的核可以取得更高的精度?作者基于MobileNetV1与MobileNetV2进行卷积核尺寸对于性能的研究与分析。从下图可以看出:当卷积核达到$9\times9$时模型精度达到最大,继续扩大卷积核会导致精度的下降。
这同时也意味着单尺度核尺寸的局限性,模型需要大尺寸核捕获高分辨率模式,同时需要小尺寸核捕获低分辨率模式以及获得更高的精度和效率。
Method
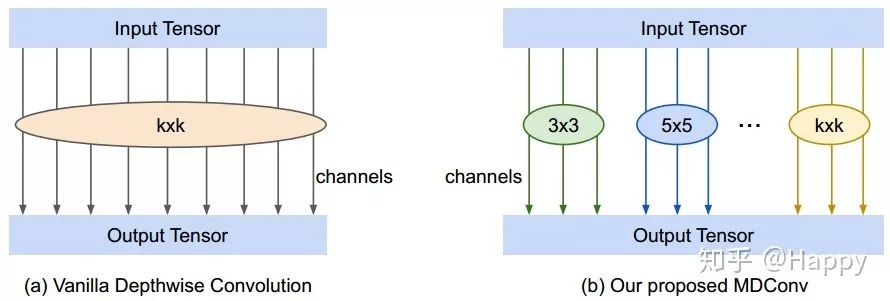
基于上述分析,作者提出一种混合深度分离卷积(MDConv),它将不同尺寸卷积核混叠到同一个卷积OP单元中,故而它可以轻易的捕获不同分辨率的特征模式。下图给出了标准深度分离卷积与本文所提MDConv示意图。
作者通过实验证实:简单的将其替换到MobileNetV1与MobileNetV2中即可取得精度与效率的提升(ImageNet分类任务与COCO目标检测任务)。
作者所提供的tensorflow实现代码如下。
def mdconv(x, filters, **args):
G = len(filters)
y = []
for xi, fi in zip(tf.split(x, G, axis=-1), filters):
y.append(tf.nn.depthwise_conv2d(xi, fi, **args))
return tf.concat(y, axis=-1)Experiments
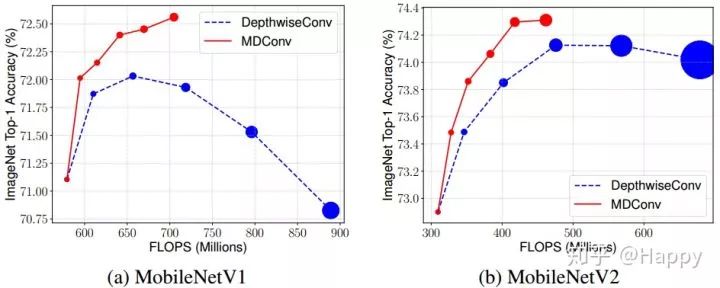
作者对比MDConv替换到MobileNetV1与MobileNetV2前后的精度对比,效果图如下。从中可以看出:相比标准深度分离卷积,MDConv更轻量、更快同时具有更高的精度
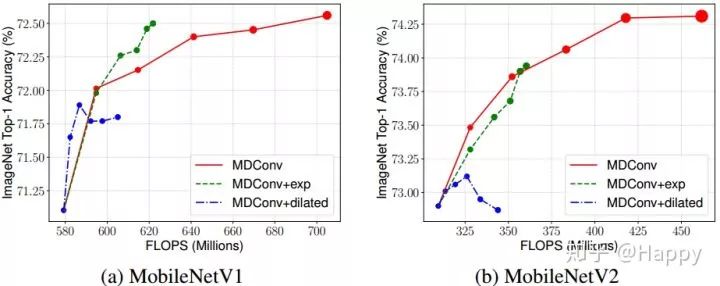
同时,作者还对比了不同组划分方式、空洞卷积核的影响性。实验对比效果图如下。从中可以看出:指数形式组划分在MobileNetV1中比均等组划分稍好,但在MobileNetV2中无明显优势。一个可能的原因:指数形式组划分导致大核通道数过少难以捕获高分辨率特征模式。空洞卷积可以提升小核网络的精度,但对于大核网络却导致了精度下降。作者认为:对于大核而言,空洞卷积会跳过大量的局部信息,进而噪声精度损失。
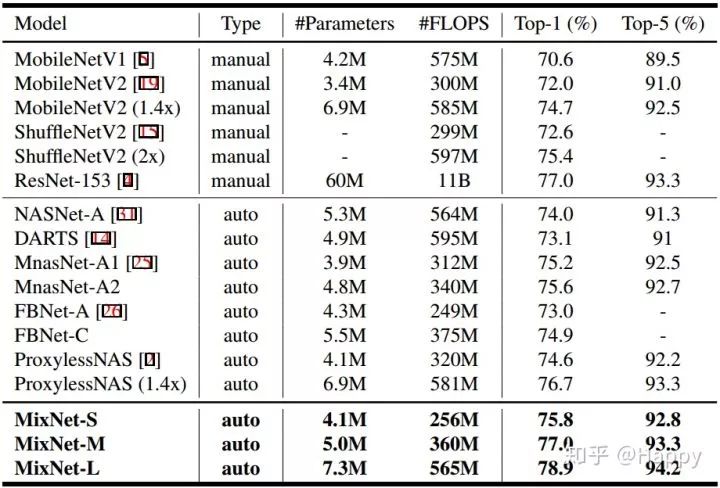
最后,作者将MDConv集成到AutoML框架中进行轻量型网络搜索,按照FLOPs划分,作者共涉及了三个网络:MixNet-S, MixNet-M, MixNet-L。他们与其他轻量型网络的性能对比如下所示。从中可以看出:MixNet取得了完胜。
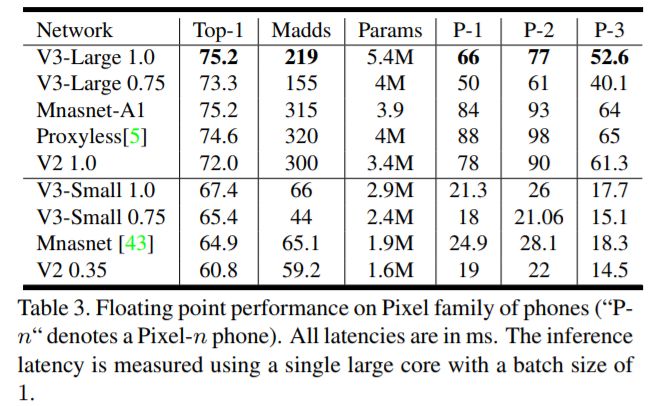
为什么说"超越MobileNetV3"呢? 对比下图MobileNetV3的数据,很明显就知道了
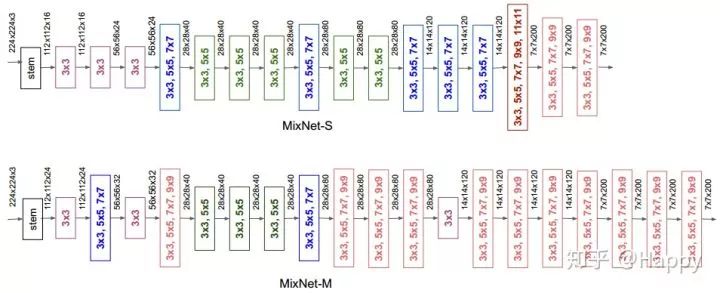
MixNet-S, MixNet-M两个网络的架构图如下所示。更多关于MixNet的信息请参考原文,这里不再详述。
Conclusion
作者重新回顾了深度分离卷积中的核尺寸影响,证实了:传统深度分离卷积网络(如MobileNetV1,MobileNetV2)受限于卷几何尺寸。基于此,作者提出一种混叠深度卷积(MDConv),它可以混叠多个尺寸卷积核到同一卷积中,进而取得精度的提升。同时,作者将其应用AutoML框架中,搜索到一类新的架构MixNet。相比比已有轻量型网络,它具有更高的精度和效率(ImageNet分类与COCO目标检测任务)。
后记
谷歌大牛做的工作确实很好,效果也很好。但是,美中不足的是,他们使用的均为Tensorflow框架,对于我等没用过该框架的砖工极度不友好,同时因为各种库的依赖问题,无法直接测试其网络。
鉴于此,本人在作者开源代码基础上,手动重写Pytorch模型,同时将其预训练模型导入到Pytorch模型中。转换完成后,对作者所提供的测试样例进行测试,结果如下,从上到下分别是MixNet-S、MixNet-M、MixNet-L的top-5结果输出。



(注:因数据预处理方式与作者的存在差异,因为这里输出的概率值也与作者的存在出入。理论上,采用相同的数据预处理方式可以得到相同的概率结果输出。Pytorch模型代码与模型待整理后将开源,具体时间请等待)
最后,补上测试用例,可爱的大熊猫。

===
2019-07-27 补充
本来计划周末两天将转换后Pytorch模型及预训练参数整理后开源。
昨天晚上突然发现一位名为“Ross Wightman”小哥已经将其整理到其开源项目[pytorch-image-models](rwightman/pytorch-image-models)中。
该项目代码维护的还是比较优秀的,鉴于此,本人将不再开源,如需相关代码请移步[pytorch-image-models](rwightman/pytorch-image-models)。本人已亲自进行核对,我们所转换模型的测试完全一致。希望该开源项目可以持续扩增,期待ing.
https://github.com/rwightman/pytorch-image-models
重磅!CVer学术交流群成立啦
扫码添加CVer助手,可申请加入CVer-目标检测交流群、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测和模型剪枝&压缩等群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡)

▲长按加群

▲长按关注我们
麻烦给我一个在看!

