比elbow方法更好的聚类评估指标

作者:Tirthajyoti Sarkar
编译:ronghuaiyang
我们展示了用来可视化和决定最佳聚类数量的评估方法,要比最常用的elbow方法要好的多。
介绍
聚类是利用数据科学的商业或科研企业机器学习pipeline的重要组成部分。顾名思义,它有助于在一个数据blob中确定紧密相关(通过某种距离度量)的数据点的集合,否则就很难理解这些数据点。
然而,大多数情况下,聚类过程属于无监督机器学习。而无监督的ML则是一件混乱的事情。
没有已知的答案或标签来指导优化过程或衡量我们的成功。我们正处于一个未知的领域。
因此,当我们面对一个基本问题时,像k-means clustering]样的流行方法似乎不能提供一个完全令人满意的答案。
刚开始的时候,我们如何知道聚类的实际数量呢?
这个问题非常重要,因为聚类的过程通常是进一步处理单个聚类数据的前置问题,因此计算资源的数量可能依赖于这种度量。
在业务分析问题的情况下,后果可能更糟。聚类通常是为了市场细分的目标而进行的分析。因此,很容易想到,根据聚类的数量,对营销人员进行分配。因此,对聚类数量的错误评估可能导致宝贵资源的次优分配。

elbow方法
对于k-means聚类方法,回答这个问题最常用的方法是所谓的elbow 方法。它需要在一个循环中多次运行算法,聚类的数量不断增加,然后绘制聚类得分作为聚类数量的函数。
elbow法的分数或度量是什么?为什么它被称为'elbow'方法?一个典型的场景如下:
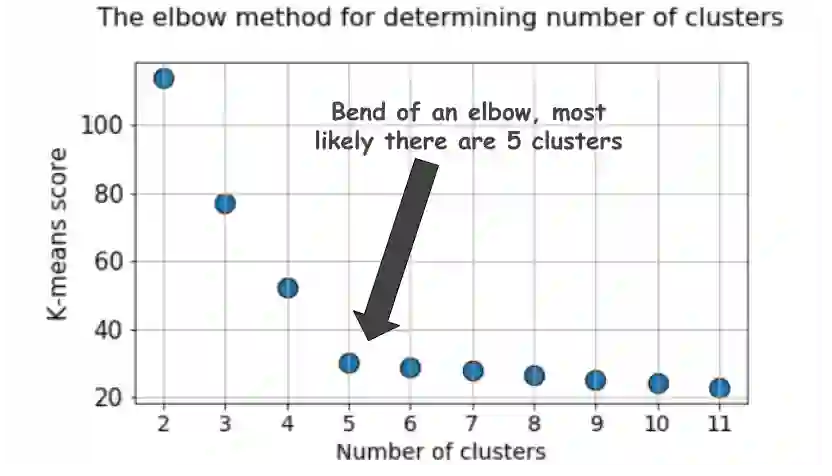
通常,得分是k-means目标函数上输入数据的度量,即某种形式的簇内距离相对于簇间距离。例如,在Scikit-learn的k-means estimator中,一个score 方法可用于此目的。
并不是那么明显,不是吗?
Silhouette coefficient — 一个更好的度量
Silhouette Coefficient是用每个样本的平均簇内距离a)和平均最近簇间距离(b)计算出来的。样本的轮廓系数为(b - a) / max(a, b)。为了澄清,b是该样本与该样本不属于的最近的群之间的距离。我们可以计算所有样本的平均Silhouette Coefficient,并以此作为判断集群数量的指标。
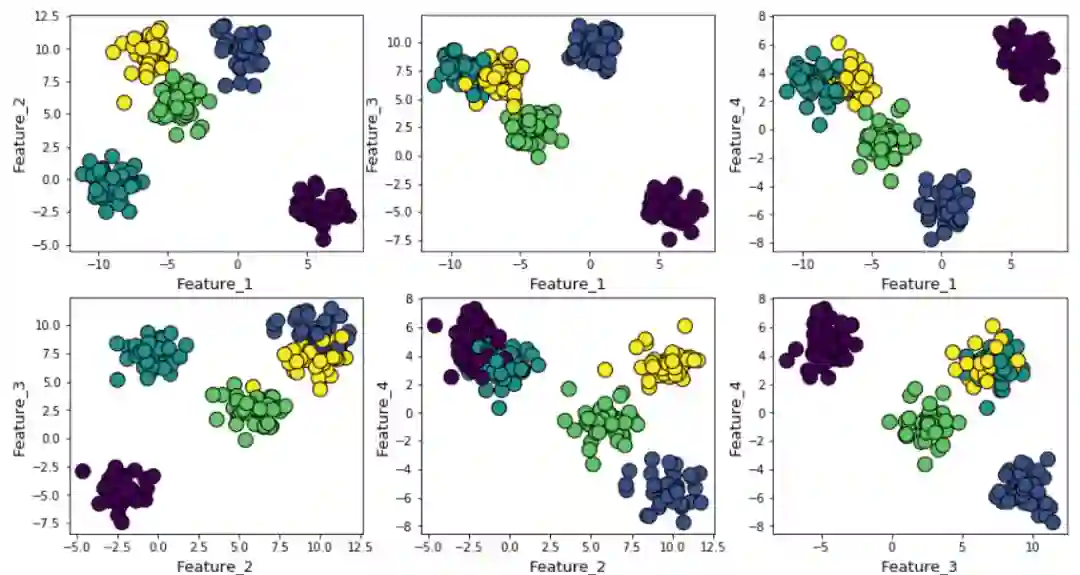
为了说明,我们使用Scikit-learn的make_blob 函数在4个特征维度和5个聚类中心上生成随机数据点。因此,这个问题的基本事实是,数据是在5个聚类中心附近生成的。然而,k-means算法无法知道这一点。
簇可以按如下方式绘制(成对特征):
接下来,我们运行k-means算法,选择k=2到k=12,计算每次运行的默认k-means得分和平均Silhouette Coefficient,并将它们并排绘制出来。
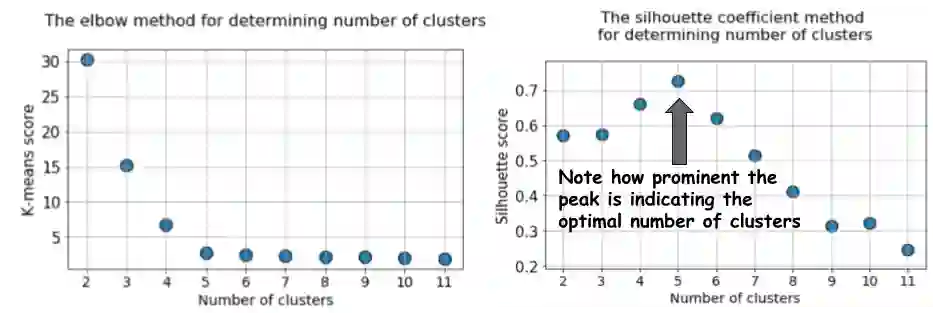
两者之间的区别再明显不过了。平均silhouette系数在k=5时增大,然后k值越大,平均silhouette系数急剧减小,即在k=5处有一个明显的峰值,这就是原始数据集生成的簇数。
silhouette系数与elbow法的平缓弯曲相比,表现出峰值特性。这更容易可视化和归因。
如果我们在数据生成过程中增加高斯噪声,簇看起来会更加重叠。
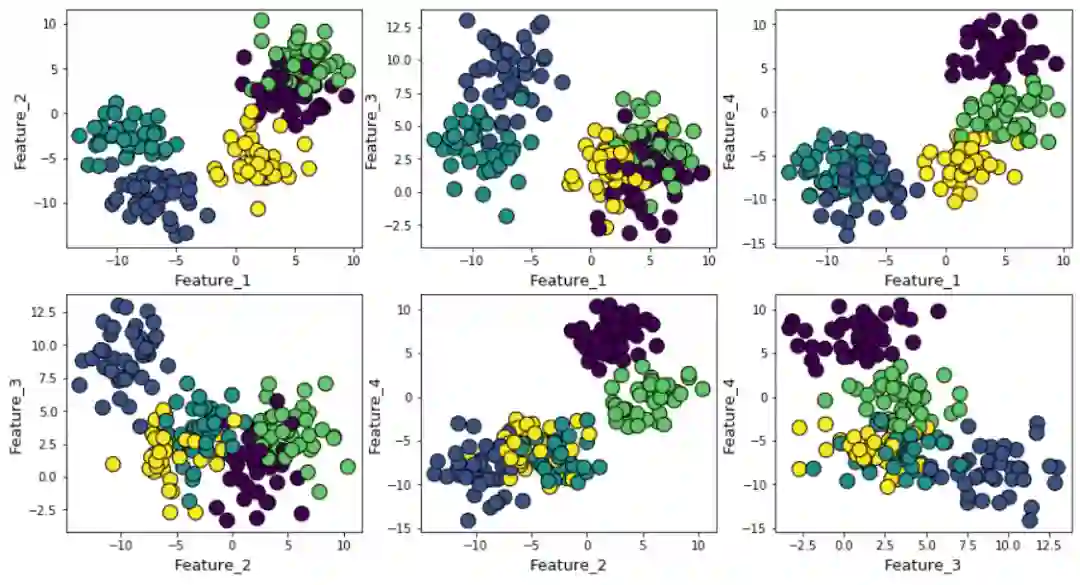
在本例中,elbow方法的默认k-means得分会产生相对不明确的结果。在下面的elbow图中,很难选择真正发生弯曲的合适点。是4、5、6还是7?
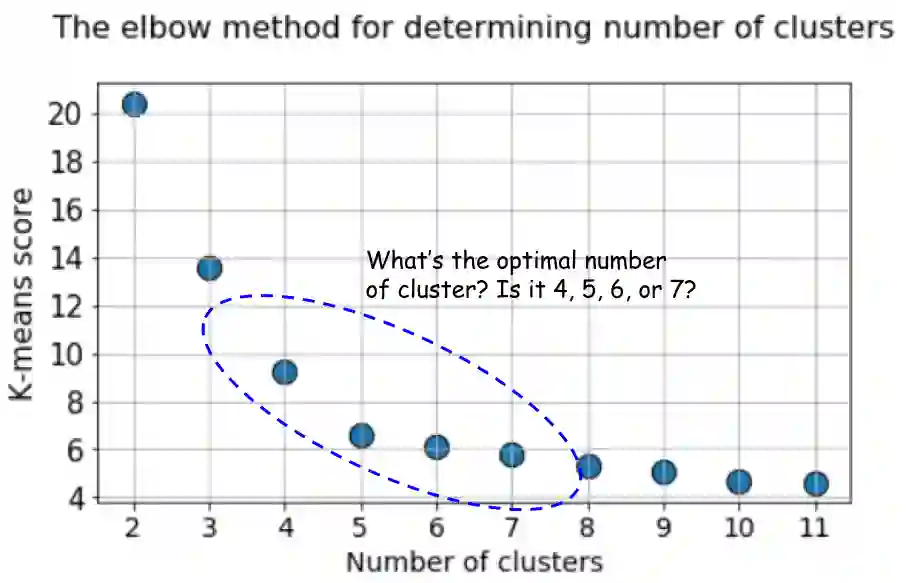
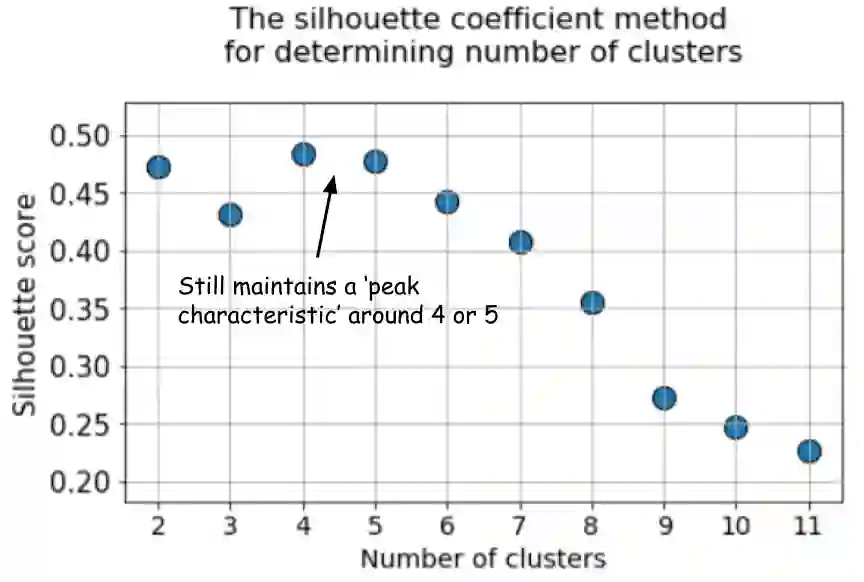
但silhouette系数图仍然能在4或5个聚类中心处出现峰值特征,使我们的判断更容易。
事实上,如果你回头看看重叠的簇,你会发现大多数情况下有4个可见的簇 —— 尽管数据是用5个聚类中心生成的,但由于高方差,只有4个簇在结构上显示出来。Silhouette系数可以很容易地捕捉到这种行为,并显示聚类的最佳数量在4到5之间。
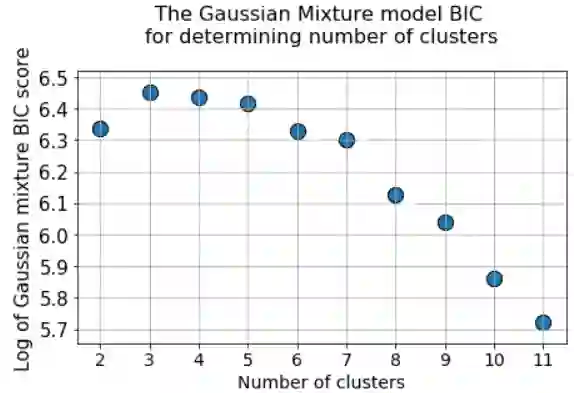
BIC评分采用高斯混合模型
还有其他优秀的指标来确定的聚类的数量,比如Bayesian Information Criterion (BIC) ,但这些只有当我们希望用在k - means以外的聚类方法的时候才可以 —— Gaussian Mixture Model (GMM)。
基本上,GMM将一个数据簇看作是具有独立均值和方差的多个高斯数据集的叠加。然后应用Expectation-Maximization (EM)算法来近似地确定这些平均值和方差。

把BIC作为正则化
你可能是从统计分析或你之前与线性回归的交互中认识到BIC这个术语。采用BIC和AIC (Akaike Information criteria)作为线性回归变量选择的正则化技术。
BIC/AIC用于线性回归模型的正则化。
这个想法在BIC中也有类似的应用。理论上,极其复杂的数据簇也可以建模为大量高斯数据集的叠加。为了这个目的,使用多少高斯函数没有限制。
但这与线性回归中增加模型复杂度类似,在线性回归中,可以使用大量特征来拟合任意复杂的数据,但却失去了泛化能力,因为过于复杂的模型拟合的是噪音,而不是真实的模式。
BIC方法惩罚了大的高斯函数数量,并试图使模型足够简单以解释给定的数据模式。
总结
这是这篇文章的notebook:https://github.com/tirthajyoti/computerlearing-with-python/blob/master/clustering-dimensions-reduction/clustering_metrics.ipynb,你可以试试。
对于经常使用的elbow方法,我们讨论了几个备选方案,用于使用k-means算法在无监督学习设置中挑选出正确数量的聚类。我们表明,Silhouette系数和BIC评分(来自k-means的GMM扩展)是比elbow方法更好的可视化识别最优簇数的方法。

英文原文:https://towardsdatascience.com/clustering-metrics-better-than-the-elbow-method-6926e1f723a6
推荐阅读
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。


