全面理解目标检测中的anchor

极市导读
anchor是一个晦涩难懂的东西,没有在哪篇论文中有明确的定义,也没有详细介绍它到底是什么,很多人在初次接触时非常头疼。在本文将详细介绍一下anchor。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
前言
在本文将详细介绍一下anchor,主要包括以下内容:
What:anchor是什么?
Where:如何以及在何处对图像生成anchor以用于目标检测训练?
When:何时可以生成anchor?
Why:为什么要学习偏移而不是实际值?
How:如何在训练过程中修正选定的anchor以实现训练目标检测模型?
前几年主流的SOTA目标检测都基于anchor来设计,这方面的研究有 YOLO、SSD、R-CNN、Fast-RCNN、Faster-RCNN、Mask-RCNN 和 RetinaNet等,anchor是一个晦涩难懂的东西,没有在哪篇论文中有明确的定义,也没有详细介绍它到底是什么,很多人在初次接触时非常头疼。
在本文将,主要包括以下内容:
-
What:anchor是什么?
-
Where:如何以及在何处对图像生成anchor以用于目标检测训练?
-
When:何时可以生成anchor?
-
Why:为什么要学习偏移而不是实际值?
-
How:如何在训练过程中修正选定的anchor以实现训练目标检测模型?
anchor是什么
术语anchor boxes是指预定义的框集合,其宽度和高度被选择以匹配数据集中目标的宽度和高度。提议的anchor boxes包含可以在数据集中找到的目标大小的可能组合。这自然应该包括数据中存在的不同纵横比和比例。通常选择 4-10 个anchor boxes作为图像中不同位置的提议。
在计算机视觉领域,深度学习神经网络在图像分类和目标检测方面表现出色。首先是滑动窗口检测器,可以在前向传递中定位单个目标。滑动窗口检测器已被单次和两级检测器取代,它们能够处理整个图像并输出多个检测。这些目标检测器严重依赖anchor boxes的概念来优化滑动窗口检测的速度和效率。这是因为滑动窗口检测器需要大量的前向传递来处理图像,而许多前向传递只处理背景像素。有关滑动窗口检测器的说明,请参见下面的图 1。
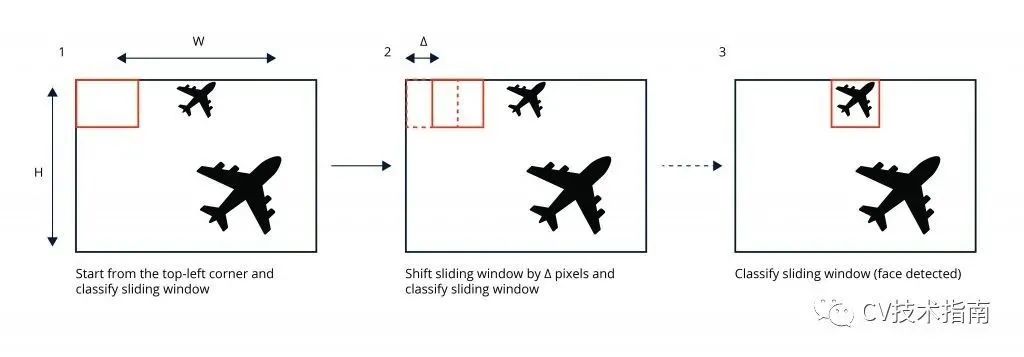
训练目标检测网络的典型任务包括提出anchor boxes或使用传统计算机视觉技术搜索潜在锚、将提议的锚与可能的ground truth 框配对、将其余的分配给背景类别并训练以纠正输入提案框。需要注意的是,anchor boxes的概念可以用于预测固定数量的框。
anchor在图像上如何以及在哪里提出?
从本质上讲,提出anchors是关于确定可以适合数据中大多数目标的适当框的集合,将假设的、均匀间隔的框放置在图像上,并创建一个规则将卷积特征图的输出映射到每个位置在图像中。
要了解anchor boxes是如何提出的,请考虑包含小目标的 256px x 256px 图像的目标检测数据集,其中大多数目标位于 40px X 40px 或 80px X 40px 之间。额外的数据整理可能表明,ground truth 框大多是宽高比为 1:1 的正方形或宽高比为 2:1 的矩形。
鉴于此,应至少考虑两个纵横比(1:1 和 2:1)来提议此示例数据集的anchor boxes。这些目标的比例将指目标的长度或宽度(以像素为单位)占其包含图像的总长度或宽度(以像素为单位)的比例。
例如,考虑一个图像的宽度 = 256px = 1 个单位,那么一个 40px 宽的目标占据 40px / 256px = 0.15625 个单位的宽度——该目标占据总图像宽度的 15.62%。
为了选择一组最能代表数据的尺度,我们可以考虑具有最极端值的目标侧度量,即数据集中所有目标的所有宽度和高度之间的最小最小值和最大最大值。如果示例数据集中的最大和最小尺度是 0.15625 和 0.3125,并且我们要为anchor boxes提议选择三个尺度,那么三个潜在尺度可能是 0.15625、0.234375 和 0.3125。
如果使用上面提到的两个纵横比(1:1 和 2:1)和这三个尺度(0.15625、0.234375 和 0.3125)为这个示例数据集提出anchor boxes,我们将总共有六个anchor boxes来提出多个在任何输入图像中的位置。
下图显示了图像上均匀间隔的 8×8 网格。可以在每个单元中心上提出一个边界框。在每个位置提出 6 个框,总共 384 个。在每个位置,我们可以为长宽比和比例的每个组合提出一个框,每个网格中心/位置总共有六个框。在每个位置都提出了不同纵横比和比例的框,以涵盖所有可能性。
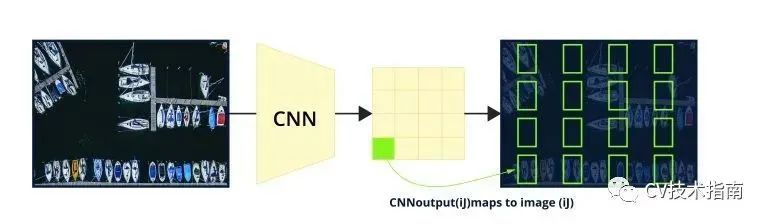
为了获得对图 2 中网格中每个位置的卷积神经网络预测,考虑一个 4 通道 8×8 特征图,其中每个通道输出每个位置一个框的 x、y、宽度和高度坐标。对于每个位置的六个框,考虑一个 4*6 通道的 8*8 特征图。使用anchor boxes的 SOTA 架构通常包含维度为 8 倍数的特征图。这是可能的,因为卷积神经网络本质上对输入进行下采样,同时通过 2D 卷积和池化操作保留重要的空间特征,并且完全卷积层输出密集的特征图如图 3 所示。
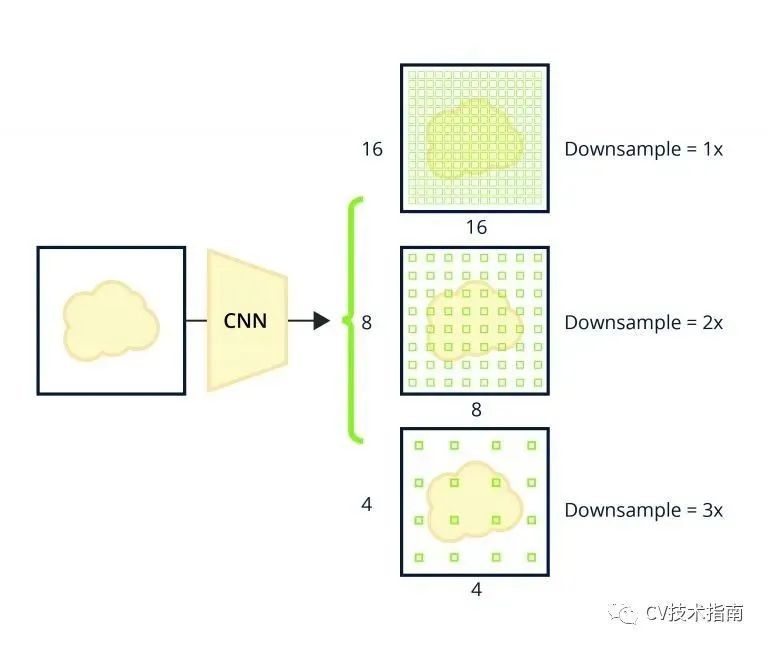
现在来谈谈检测小于网格单元大小的目标——当提议网格如此自然以至于有包含多个小目标的单个单元格时。这可以通过提出更精细的网格并相应地调整特征图输出形状来解决。更好的是,可以使用多个网格并将它们映射到卷积层次结构中的不同卷积层,就像 SSD 和 RetinaNet 预测器头使用的特征金字塔网络一样。
在下一节中,我们将讨论在生成ground truth批次或在推理时解释预测时如何需要在不同位置的图像上提出anchors的概念。
什么时候在图像上提出anchor?
检测器不预测框,而是为每个提议的边界框预测一组值,主要是每个正在学习的类别的anchor boxes坐标偏移和置信度分数。这意味着将始终在每个图像上提出相同的anchors,并且将使用前向传递的预测偏移量来纠正这些提议。网络没有将特征图坐标与图像内的位置匹配的概念,也没有将其输出对应于anchor boxes直到输出被解释的概念。
从理论上讲,由于每张图像将始终与同一组固定anchors提议相关联,并且训练过程中ground truth不会改变,因此实际上没有必要多次提议anchors或将它们与ground truth或背景类别匹配。提案和ground truth匹配通常都发生在批处理生成器中。有时,提案生成层会添加到实际网络中,以将锚数据添加到网络的输出张量中,但在批处理生成器中生成和平铺图像上的提案的逻辑应该是相同的。
知道了这一点,就很容易理解ancor需要初始化,并将此数据结构存储在内存中,以供实际使用时,如:在训练中与ground ruth匹配,在推断时将预测的偏移量应用于anchor。
为什么学习偏移量而不是实际值?
从理论上讲,如果卷积滤波器将其感受野照射在同一类型的目标上两次,则无论滤波器在图像中的哪个位置照射其感受野,它都应该输出大致相同的值两次。
这意味着,如果图像包含两辆车并且输出特征图包含绝对坐标,那么网络将预测两辆车的坐标大致相同。
学习anchors偏移量允许特征图输出与这两辆车的偏移量输出相似,但偏移量应用于可映射到输入图像中不同位置的anchors。这是在绑定框回归期间学习anchor boxes偏移背后的主要原因。
ground truth——匹配anchors并生成批次
ground truth批次必须包含要学习的目标偏移量,并且应包含建议的anchors。后者在训练期间不使用,但避免了在推理时将anchors与偏移预测与附加数据结构和随附代码相关联。目标偏移量应该是将建议精确移动到匹配的ground truth框或零(如果它是背景框的ground truth)所需的精确量,因为背景框不需要校正。
回顾一下,基于锚的批处理生成器构建了一个学习目标,其中在训练期间将考虑图像的每个提议的锚,无论它是否已分配到前景或背景类别。按照我们的示例,一批将从 64 个位置的 6 个anchors开始,总共 384 个anchors框。每个提议的anchors都可能通过以下或这些基本步骤的变体与ground truth框匹配:
对于每个anchors,找到哪个ground truth框具有最高的联合交集(IOU)分数
-
IOU 大于 50% 的anchors匹配到相应的ground truth框
-
IOU 大于 40% 的anchors被认为是不明确的并被忽略
-
IOU 小于 40% 的anchors被分配到背景类别
重新梳理一遍这个过程。从所有提议的anchors(在示例中为 384 个)的集合开始,与ground truth框匹配的框将包含其类别和更新的偏移量以纠正或移动该anchors。对背景和模糊/忽略框的偏移保持在它们的初始零偏移值。同样,这些偏移量是我们想要用神经网络来近似的值。这些是在边界框回归任务中学习的实际值。决定权重优化将考虑哪些背景偏移并丢弃不匹配的框通常发生在损失函数中。
如何在训练期间修正anchor boxes
损失计算不会对anchor boxes应用偏移量。在这一点上,批处理生成器已经编码了将anchors准确地“移动”到ground truth所在的位置所需的偏移量,并且如上所述,这是与ground truth框匹配或不匹配的每个建议框的位置学习目标。不匹配的anchor boxes不应造成损失,通常会被忽略。
回想一下,网络在每个特征图位置预测所有提议的偏移量。这意味着ground truth数据包含与ground truth框匹配的anchors的真实偏移量,而背景框的ground truth偏移量保持为零。这是因为anchors内的像素空间完全被认为是背景,提议的anchors就不需要坐标调整。
此外,这些零值将被忽略,因为背景anchors偏移确实会导致回归损失。这是因为目标检测是关于学习寻找前景目标,并且边界框回归损失(预测偏移量和正确偏移量之间)通常仅针对前景目标最小化。换句话说,由于分配给背景类别的anchors根本不应该被移动或校正,因此没有要预测的偏移量,也没有可以代表边界框回归损失中的背景框的重要值。
通常使用ground truth中存在的总背景框的子集来最小化分类损失来处理类不平衡。在示例中,每个位置有 6 个框,总共 384 个提案, 其中大部分将是背景框,这会造成严重的类不平衡。这种类别不平衡问题的流行解决方案被称为hard negative mining——根据预定比例(通常为 1:3;前景:背景)选择哪些背景框将对损失产生影响。在分类损失中处理类别不平衡的另一种流行方法涉及降低易于分类示例的损失贡献。RetinaNet 的 Focal Loss 就是这种情况。
为了获得最终的一组目标检测,网络的预测偏移量被应用于它们相应的anchor boxes。可能有成百上千个提议的框,但最终,当前的 SOTA 检测器忽略所有预测为背景的框,保留通过某些标准的前景检测,并应用非最大抑制来纠正同一目标的重叠预测。
正如本文开头提到的,理解SOTA目标检测的飞跃通常会变得令人生畏和晦涩,但是一旦了解了anchor boxes的作用,目标检测就会具有全新的意义。
原文链接:
https://www.wovenware.com/blog/2020/06/anchor-boxes-in-object-detection-when-where-and-how-to-propose-them-for-deep-learning-apps/#.YYCcrZ5BxhE*
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~




