闲扯B-Tree和B+Tree的异同
在聊今天的正题以前,老王还是要跟大家说一个事情:微信公众号有个限制,超过一段时间的消息不能回复。老王平时花在工作上的时间比较多,等有时间回复大家消息的时候,微信已经不允许了。所以,大家如果没有收到老王的回复,请到公众号右下角菜单「有点意思」->「有问有答」中提问哈。老王对大家的提问一定是有问有答的!
好了,话归正传,我们今天要聊一个比较硬的话题:一个传说中的惊天动地的牛逼的大家都听说过的却又很少实际深入接触到的但又基本每天都在使用的数据结构。(大家注意看上一句话的定语)
我记得我最先接触B树是在大学学数据结构的时候,那会儿有一章是专门讲B树的。但是那一章老师说是选学,所以不讲…… 我自己下来把那一章看了,看的有点云里雾里。后来学数据库原理,又提到了B+树,才去又好好的学习了一遍。
但是也是因为平时很少直接使用这个数据结构(比起数组、链表、Hash等等来讲),反反复复的看,反反复复的忘。在今天写这篇文章之前,老王又拿起了「算法导论」重新review了一遍。
#同#
B树和B+树其实都是平衡搜索树。这里要脑补一下平衡搜索树的概念:这个词划分一下就是平衡+搜索+树。也就是说,他首先是一棵树,其次能搜索,再次他是平衡的。大家耳熟能详的一个概念:二叉平衡搜索树。(详细的大家可以在百度上搜一下定义,或者拿起那本厚实的「算法导论」看看)。
#异#
但是B树和B+树却有不同的地方。就是这些不同的地方,决定了他们的用处可能不一样。
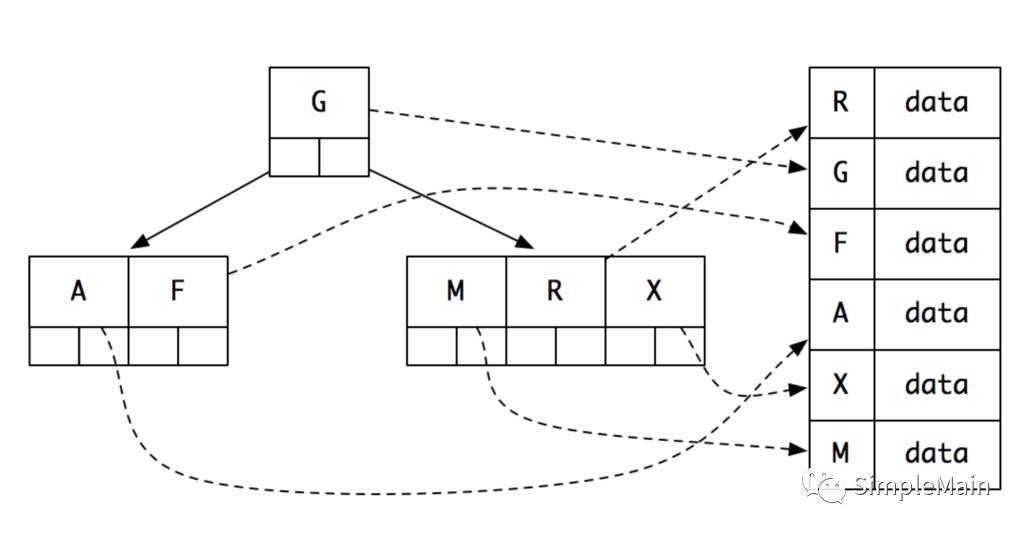
我画了一个不太漂亮的B树的图。我们可以看到B树里面,每个结点有这样的特点:不论是叶结点还是非叶结点,都含有Key和一个指向数据的指针。这样,一旦找到某个结点以后,就可以根据指针找到对应的磁盘地址。
但是,这也带来了另外的问题,就是每一个数据的指针会带来额外的内存占用,从而减少放入内存的结点数。
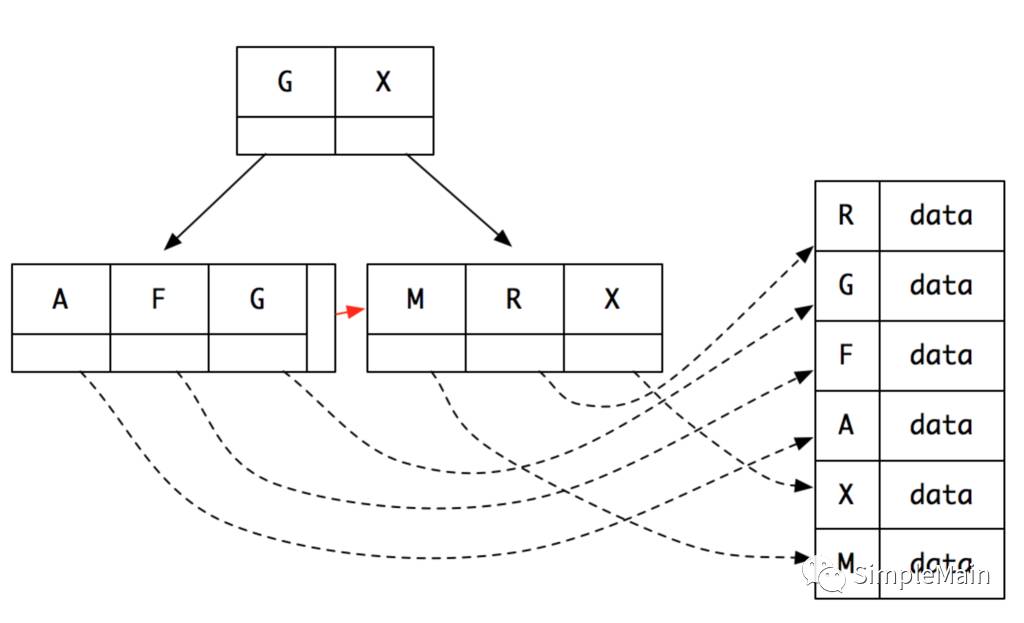
我们再回头看看B+树,他有两个明显的特征:
1、所有的叶子结点才有指向数据的指针。非叶结点就是纯的索引数据。这样的好处在于,我们可以将尽可能的非叶结点载入内存,没有浪费。
2、大家注意看那个红色的箭头,每个叶结点都有指向下一个叶结点的链接。这样的好处在于,我们可以从任意一个叶结点开始遍历,获取接下来所有的数据。
所以,综合来看,B+Tree比B-Tree少了点儿东西,又多了点儿东西。这样就使得很多数据库在选择索引数据结构的时候,选择了B+Tree(也不是所有的)。
比如,我们写一条Sql:select * from alphabets order by key_word;
大家想想,如果用B树和B+树,怎么样来实现这样的功能?B树好像比较为难。B+树则可以直接用叶结点的索引链遍历。
这样看起来,B+树似乎比B树强很多。但是,任何算法和数据结构都有适用他的地方。如果没有order by这样类似的需求,而B树实现的成本比B+树要低,那么采用B树也是一种不错的选择。所谓的没有最好,只有更适合。选择适合的最重要~






