用 TensorFlow Extended 实现可扩展、快速且高效的 BERT 部署
文 / 由特邀作者 SAP Concur Labs 的高级机器学习工程师 Hannes Hapke 发布。由 Robert Crowe 代表 TFX 团队编辑。

Transformer 模型(尤其是 BERT 模型)为 NLP 带来巨大的变革,并且在情感分析、实体提取和问答问题等任务的处理上也均有新的突破。BERT 模型让数据科学家站在了巨人的肩膀上。各公司已经通过大型语料库对模型进行预训练,数据科学家可以对这些经过训练的多用途 Transformer 模型应用迁移学习,针对其所在领域的特定问题达成突破性解决方案。
BERT 模型
https://arxiv.org/abs/1810.04805
在 SAP 的 Concur Labs (www.concurlabs.com),我们希望利用 BERT 来解决差旅与费用领域中出现的一些新问题。我们希望能够简化 BERT 推理。遗憾的是,我们曾尝试的解决方案都不太理想。
通过与 Google/TensorFlow 团队合作,采用其最新的开发成果,我们最终达成了目标:一致、简单且非常快速的 BERT 模型推理。利用他们所提议的实施方案,我们能够在几毫秒内完成从原始文本到分类的预测。让我们来看一下各种 TensorFlow 库和组件如何助力我们达成这一里程碑。
本文将为您简单介绍如何通过 TensorFlow 的生态系统实现可扩展、快速且高效的 BERT 部署。如果您有兴趣深入了解其实现过程,请查看本文的第二部分 (暂未发布),了解有关实现步骤的详细信息。如果想尝试进行演示部署,请查看 Concur Labs 的演示页面 (bert.concurlabs.com),其中有我们情感分类项目的相关展示。
关于 Serving 的一则注意事项
本文中讨论的方法支持开发人员利用 TensorFlow Extended (TFX) v0.21 或更高版本来训练 TensorFlow 模型。但是 TensorFlow Serving (v2.1) 的当前发行版中尚不包含对训练后模型所含的 tf.text 算子的支持,Nightly docker 发行版和 v2.2 发行版中将包含此类支持。
想要直接查看代码?
如果想转至完整示例,请查看 Colab 笔记本,其中有生成可部署 BERT 模型的完整 TensorFlow Extended (TFX) 流水线的相关展示,且模型计算图中还包含预处理步骤。
Colab 笔记本
https://colab.sandbox.google.com/github/tensorflow/workshops/blob/master/blog/TFX_Pipeline_for_Bert_Preprocessing.ipynb
BERT 部署的现状
最近,Transformer 模型的研究进展十分迅速。但很遗憾,将模型用于生产的过程十分复杂,结果也不尽如人意。理想情况下,我们会将原始文本发送到服务器,但 BERT 模型需要先对输入文本进行预处理,然后我们才能得到实际模型的预测。一些现有解决方案已通过在客户端对文本进行预处理解决这一问题,还有其他一些解决方案通过在服务器端执行中间步骤来处理输入数据。这两种做法都不太合适,因为需要额外的部署协调(如客户端/服务器切换期间),或者会降低推理的效率(如由于中间转换步骤需要复杂的预测批处理能力)。
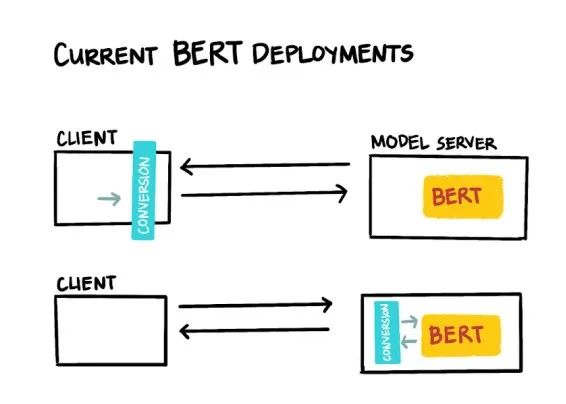
图 1:当前 BERT 部署
最理想的部署是怎么样的?
就部署模型来说,越简单越好。我们希望部署Transformer 模型,并将预处理作为模型计算图的一部分。因为预处理集成到模型计算图中,我们便可只将单个模型部署到模型服务器中,除去任何其他部署依赖关系(客户端或中间处理),然后充分发挥模型服务器的优势(如批处理预测请求以最充分地利用我们的推理硬件)。
通过 TensorFlow 生态系统部署 BERT
TensorFlow 是一款效率极高的框架,它不仅是机器学习框架,还提供包含各类支持包和工具在内的广泛生态系统。对我们来说很有用的一款工具是 TensorFlow Serving。这款工具可提供简单、一致且可扩展的模型部署。
TensorFlow Serving
https://tensorflow.google.cn/tfx/guide/serving可扩展的模型部署
https://tensorflow.google.cn/tfx/serving/serving_kubernetes
我们密切关注的另一个生态系统项目是 TensorFlow Transform。借助这款工具,我们可以计算图方式来构建模型预处理步骤,这样我们就能将其与真实的深度学习模型一起导出。
TensorFlow Transform
https://tensorflow.google.cn/tfx/guide/tft
TensorFlow Transform 要求所有预处理步骤均表示为 TensorFlow 算子。这就是我们最近开发的 TensorFlow Text 极为有帮助的原因。RaggedTensors 的实现不仅开启新的实现,并且该库还提供实施自然语言预处理步骤所需的功能。
RaggedTensors
https://tensorflow.google.cn/guide/ragged_tensor
TensorFlowWorld 2019 中提供的 TensorFlow Text 的一项新功能就是对 BERT Tokenizer 的完全实施。正因如此,我们才能够通过几行 TensorFlow 代码来表示我们的预处理步骤。我们还利用另一款 TensorFlow 工具实现了我们对于一致的模型流水线和部署的目标:TensorFlow Extended (TFX)。TFX 支持我们通过复制方式表示完整的 ML 流水线,因此有助于我们部署一致的机器学习模型。
TensorFlowWorld 2019 (Playlist)
https://v.youku.com/v_show/id_XNDQyMDUyNzE4OABERT Tokenizer
https://github.com/tensorflow/text/blob/master/tensorflow_text/python/ops/bert_tokenizer.py#L121
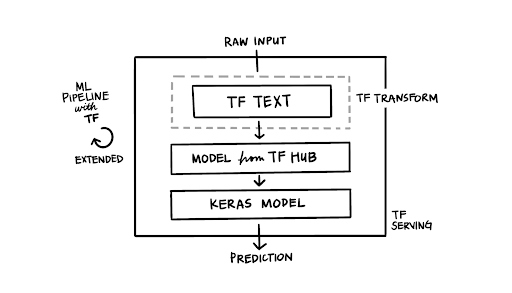
图 2:使用 tf.Text 的 TFX 流水线
通过 TensorFlow 算子编写预处理步骤
vocab_file_path = load_bert_layer().resolved_object.vocab_file.asset_path
bert_tokenizer = text.BertTokenizer(vocab_lookup_table=vocab_file_path,
token_out_type=tf.int64,
lower_case=do_lower_case)
...
input_word_ids = tokenize_text(text)
input_mask = tf.cast(input_word_ids > 0, tf.int64)
input_mask = tf.reshape(input_mask, [-1, MAX_SEQ_LEN])
zeros_dims = tf.stack(tf.shape(input_mask))
input_type_ids = tf.fill(zeros_dims, 0)
input_type_ids = tf.cast(input_type_ids, tf.int64)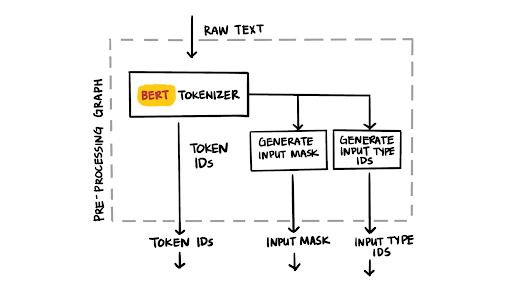
图 3:BERT 分词器
使用 TensorFlow Transform 及上述代码,可将预处理计算图与训练后的 TensorFlow 模型一起导出。借助 TensorFlow Serving 的最新更新,我们部署的 BERT 模型现在可以接受原始文本作为输入。瞧!没有任何其他依赖关系。
使用 TensorFlow Transform 为我们带来一些切切实实的好处。一方面,我们可以有序地划分数据预处理和模型架构工作之间的职责。另一方面,我们能够轻松地调试、测试并生成预处理输出的数据统计信息。Transform 组件将输出转换后的 TFRecords 形式的训练集,可供轻松检查。“调试”Transform 输出的过程中,我们发现几个小问题,这些问题不会造成模型训练失败,但可能会影响其性能(如 [SEP] token 中出现偏移)。从技术上来讲,此处不需要 TensorFlow Transform。由于每个示例预处理均独立于完整的语料库进行,我们可轻松地直接将其构建到模型计算图中。但我们发现以这种方式构建和调试流水线更加轻松。
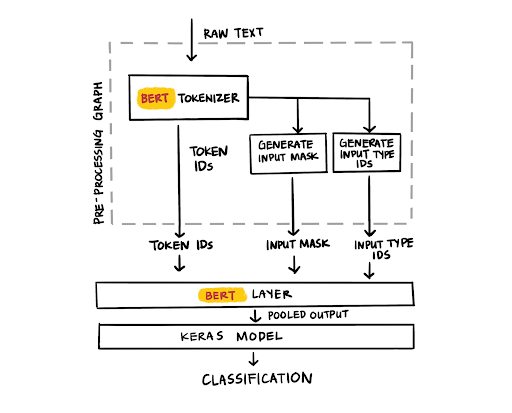
图 4:BERT 层
如果有兴趣深入了解实施过程,我们建议您阅读文章的第二部分 (暂未发布),其中有对实施过程的深入阐述。
何为理想部署?
简化的开发
利用各种 TensorFlow 工具,我们能够以简明扼要的方式部署 BERT 模型。将预处理步骤整合到模型计算图中,可降低训练和推理数据之间脱节的风险。部署的模型无需任何其他客户端或服务器依赖关系,从而进一步降低模型发生错误的风险。我们可以通过 TensorFlow Serving 以一致的方式来部署 BERT 模型,同时可利用像批量推理一类的模型优化。
推理性能
我们最初的性能测试让人充满希望。对包含预处理步骤的演示 BERT 模型计算图进行推理,且模型的每次预测平均耗时约为 15.5 毫秒(基于单个 V100 GPU、最多 128 个 token、gRPC 请求、针对 GPU 的非优化 TensorFlow Serving 构建版本及 Uncased Base BERT 模型测量得出)。这和以前在客户端使用 BERT 词条化的部署以及使用 TensorFlow Serving 托管的分类模型的平均推断时间大致相同。当然,您的机器及型号不同,得到的结果也会不一样。
更多信息
如果有兴趣深入了解实现过程,我们建议您阅读文章的第二部分。如果想要深入了解代码,请查看 Colab 笔记本,其中包含使用预训练 BERT 模型实现情感分类模型的示例。如果想尝试进行演示部署,请查看 Concur Labs 的演示页面,其中有我们情感分类项目的相关展示。
Colab
https://colab.sandbox.google.com/github/tensorflow/workshops/blob/master/blog/TFX_Pipeline_for_Bert_Preprocessing.ipynbConcur Labs 的演示页面
https://bert.concurlabs.com/
如果对 TensorFlow Extended (TFX) 和 TensorFlow Transform 的内部工作原理感兴趣,请仔细研读 TFX 用户指南,并查看即将出版的 O’Reilly 刊发文章《使用 TensorFlow 构建机器学习流水线及自动化模型生命周期》(Building Machine Learning Pipelines, Automating Model Life Cycles With TensorFlow),已在网上预先发布。
TFX 用户指南
https://tensorflow.google.cn/tfx/guide使用 TensorFlow 构建机器学习流水线及自动化模型生命周期
http://www.buildingmlpipelines.com
要了解有关 TFX 的更多信息,请查看官网 (tensorflow.google.com),加入 TFX 讨论组,仔细研读公众号中的其他文章。
TFX 讨论组
https://groups.google.com/a/tensorflow.org/forum/#!forum/tfx
致谢
本项目的顺利开展离不开 Catherine Nelson、Richard Puckett、Jessica Park、Robert Reed 和 Concur Labs 团队的大力支持。同样也要感谢 Robby Neale、Robert Crowe、Irene Giannoumis、Terry Huang、Zohar Yahav、Konstantinos Katsiapis、Arno Eigenwillig 和 TensorFlow 团队的其他成员,感谢他们参与讨论项目的实施细节,并提供 TensorFlow 库的更新。还要特别感谢来自 Talenpair 的 Cole Howard,他总是能在自然语言处理相关的讨论中提出启发性的观点。
了解更多请点击 “阅读原文” 访问官网。
更多 TFX 相关阅读:






