用Keras和TensorFlow构建贝叶斯深度学习分类器
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

SIGAI特约作者
黄浴
奇点汽车美研中心总裁兼自动驾驶首席科学家
在这篇文章【1】中,将讲述如何使用Keras和Tensorflow训练贝叶斯深度学习(BDL)分类器,其中参考了另外两个博客【2,3】的内容。在深入了解具体的训练示例之前,介绍几个重要的高级概念:
• 什么是贝叶斯深度学习(BDL)?
• 什么是不确定性(uncertainty)?
• 为什么不确定性很重要?
然后,将介绍在深度学习模型中引入两种不确定性的技术,并将使用Keras在cifar10数据集上通过冻结(frozen)ResNet50编码器训练全连接层。通过这个例子,还将讨论探索贝叶斯深度学习分类器不确定性的预测方法,并提出今后如何改进模型的建议。
1. 什么是贝叶斯深度学习?
贝叶斯统计(Bayesian statistics)是统计学领域的一种理论,其中关于世界真实状态的证据用置信程度(degrees of belief)来表达。贝叶斯统计学与实践中的深度学习相结合意味着在深度学习模型预测中加入不确定性。早在1991年就有了神经网络中引入不确定性的想法。简而言之,贝叶斯深度学习在典型神经网络模型中发现的每个权重和偏差参数上增加了先验分布(prior distribution)。过去,贝叶斯深度学习模型并不经常使用,因为它们需要更多参数进行优化,这会使模型难以使用。然而,最近贝叶斯深度学习变得越来越流行,并且正在开发新技术在模型中引入不确定性,同时参数量与传统模型相同。
图1 可视化一个DBL模型
2. 什么是不确定性?
不确定性指知识有限的状态,这时候无法准确描述现有状态、未来结果或不止一种可能的结果。由于它涉及深度学习和分类,不确定性还包括模糊性; 它是关于人类定义和概念的不确定性,而不是自然界的客观事实。

图2 不确定性例子
3. 不确定性的类型
实际上存在不同类型的不确定性,我们需要了解不同应用所需的类型。这里将讨论两个最重要的类型 - 认知(epistemic)和任意(aleatoric)不确定性。
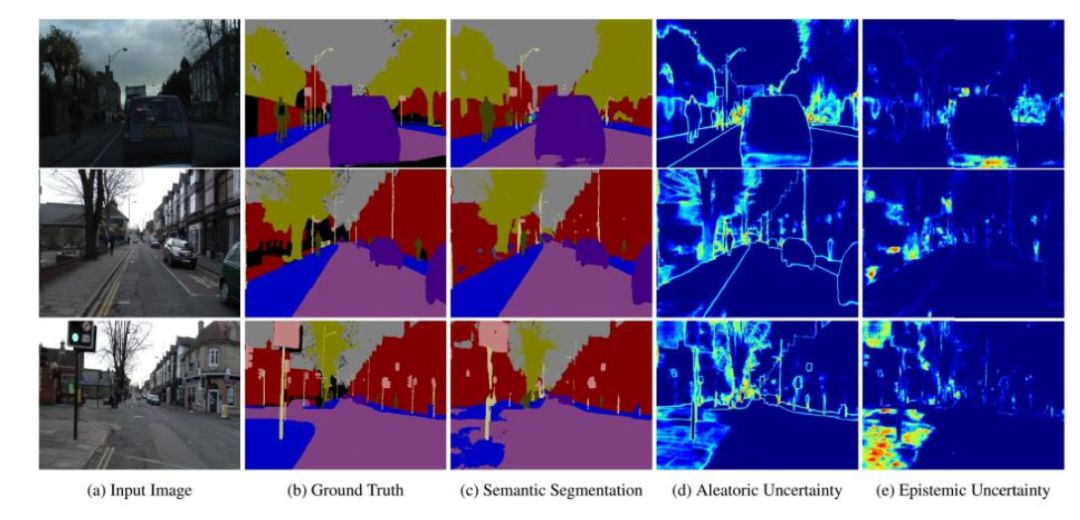
图3 在分割任务认知和任意确定性的不同
• 认知不确定性
认知的不确定性反映了对哪个模型生成收集数据的无知(ignorance)。给定足够的数据可以解释这种不确定性,并且通常称为模型(model)不确定性。认知不确定性对于模型非常重要:
• 安全危急(safety critical)应用,因为需要来理解与训练数据不同的例子;
• 训练数据稀疏的小数据集。
观察认知不确定性的一种简单方法是用25%的数据集训练一个模型,并用整个数据集训练第二个模型。仅在25%数据集上训练的模型比在整个数据集上训练的模型具有更高的平均认知不确定性,因为它看到的例子更少。

图4 “不是热狗“App
在著名的Not Hotdog应用程序中发现了一个有趣的认知不确定性的例子。似乎网络从未接受过“非热狗”图像训练,包括图4中的番茄酱。如果模型输入是腿上有番茄酱的图片,那么就会被认为是热狗。贝叶斯深度学习模型将预测这种类型的高认识不确定性。
• 任意不确定性
对于数据无法解释的信息,任意不确定性解释了这种不确定性。例如,图像中的任意不确定性可归因于遮挡(因为相机无法穿过物体)或缺乏视觉特征或图像的过度曝光区域等。只要通过提高观察所有可解释变量(explanatory variables)的精度就能解释这些不确定性。对于以下情况,任意不确定性建模非常重要:
• 大数据情况,其中认知不确定性大多被解释;
• 实时应用,无需采用昂贵的蒙特卡罗采样(Monte Carlo sampling),因为可以将任意模型(aleatoric models)形成输入数据的确定性函数。
实际上可以将任意不确定性分为两个类别:
• 数据相关或异方差不确定性(Homoscedastic uncertainty)取决于输入数据并预测为模型输出;
• 任务相关或同方差不确定性(Homoscedastic uncertainty)不依赖于输入数据。它不是模型输出,而是一个对输入数据保持不变的常数并在不同任务之间变化。因此,它可以被描述为任务相关不确定性。
立体图像中任意不确定性的具体例子是遮挡(摄像机无法看到的部分),缺乏视觉特征(即空白墙),或过曝光/曝光不足区域(眩光和阴影)。

图5 任意不确定性例子
4.为什么不确定性很重要?
在机器学习中,试图创建现实世界的近似表示。流行的深度学习模型产生一个点估计(point estimate)但不是不确定性测度。了解一个模型是否缺乏信心或错误过度自信可以有助于推理该模型和数据集。上面解释的两种不确定性是由于不同的原因导入的。
注意:在分类问题中,softmax输出提供每个类的概率,但这与不确定性不同。softmax概率是指相对于其他类输入对给定类的概率。因为概率是相对于其他类的,所以它无助于解释模型的整体置信度。
• 为什么任意不确定性很重要?
观测空间的某些部分具有比其他部分更高的噪声水平时,任意不确定性很重要。例如,任意不确定性在涉及自驾车第一次死亡事故中起了作用。特斯拉说,在这次事件中, 车上Autopilot未能识别出明亮天空下的白色卡车。可以预测任意不确定性的图像分割分类器将认识到图像该特定区域难以解释并且预测高不确定性。在特斯拉事件中,虽然汽车的雷达可以“看到”卡车,但雷达数据与图像分类器数据不一致,并且汽车的路径规划最终忽略了雷达数据(雷达数据有噪声)。如果图像分类器在其预测中包含高度不确定性,则路径规划将忽略图像分类器预测并使用雷达数据(这显得过于简化,但实际就是会发生的情况,参见下面的卡尔曼滤波器)。

图6在炫光情况下驾驶是困难的
• 为什么认知不确定性很重要?
认知不确定性很重要,因为它确定了模型从未被训练去理解的情况,因为它根本不在训练数据里。机器学习工程师希望我们的模型能够很好地适应与训练数据不同的情况;然而,在深度学习的安全危急应用中,这种希望是不够的。高认知不确定性是一个红的旗(red flag),意味着模型更有可能做出不准确的预测,当这种情况发生在安全危急应用中,该模型不应该被信任。
认知不确定性也有助于探索数据集。例如,认知不确定性对20世纪80年代这种特殊的神经网络事故(mishap)有所帮助。当时,研究人员训练了一个神经网络识别隐藏在树木中的坦克,相对那些没有坦克的树木。经过训练,网络在训练集和测试集上表现非常出色。唯一的问题是坦克的所有图像都是在阴天拍摄的,而所有没有坦克的图像都是在晴天拍摄的。分类器实际上已经学会识别晴天和阴天。

图7 坦克识别
深度学习模型中的不确定性预测在机器人技术中也很重要。比如自驾车使用卡尔曼滤波器跟踪物体。卡尔曼滤波器结合了一系列包含统计噪声的测量数据,并产生比任何单次测量更准确的估计。传统的深度学习模型无法为卡尔曼滤波器做出贡献,因为它们只预测结果而不包括不确定性项。理论上,贝叶斯深度学习模型可以促进卡尔曼滤波器跟踪。
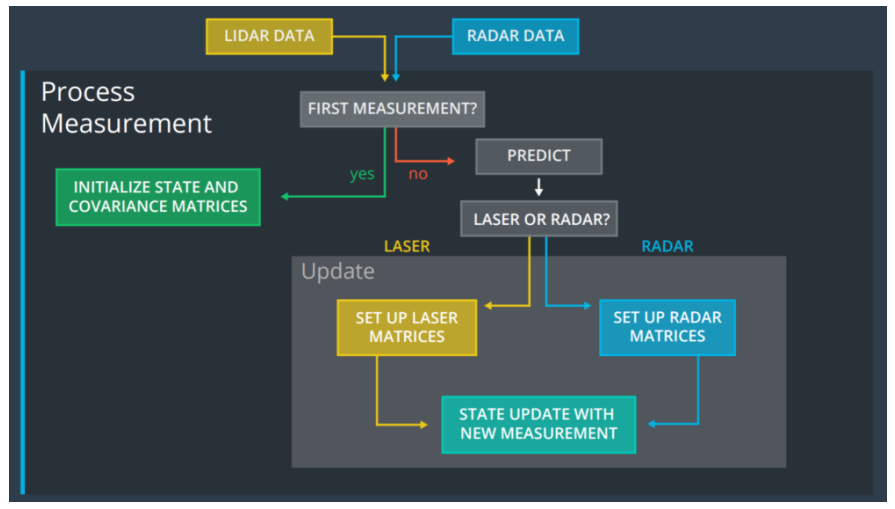
图8 Udacity中卡尔曼滤波器的应用
5. 计算深度学习模型分类的不确定性
任意和认知不确定性是不同的,因此,它们的计算方式不同。
• 计算任意不确定性
任意不确定性是输入数据的函数。因此,深度学习模型可以用修改的损失函数来学习预测任意不确定性。对于分类任务,贝叶斯深度学习模型有两个输出,即softmax值和输入方差,而不是仅预测softmax值。教模型预测任意方差是无监督学习的一个例子,因为该模型没有可供学习的方差标签。
可以通过改变损失函数来模拟异方差任意不确定性。由于这种不确定性是输入数据的函数,就可以学习从输入到模型输出的确定性映射来预测。对于回归任务,通常使用欧几里德/ L2损失进行训练:损失= || y-ŷ|| 2。要学习异方差不确定性模型,可以用以下方法代替损失函数:
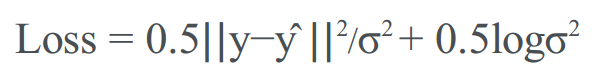
同方差不确定性的损失函数类似。
下面是一个标准分类交叉熵(cross entropy)损失函数和一个计算贝叶斯分类交叉熵损失的函数。
import numpy as np
from keras importbackend as K
from tensorflow.contribimport distributions
# standardcategorical cross entropy
# N data points, Cclasses
# true - truevalues. Shape: (N, C)
# pred - predictedvalues. Shape: (N, C)
# returns - loss(N)
defcategorical_cross_entropy(true, pred):
return np.sum(true *np.log(pred), axis=1)
# Bayesiancategorical cross entropy.
# N data points, Cclasses, T monte carlo simulations
# true - truevalues. Shape: (N, C)
# pred_var -predicted logit values and variance. Shape: (N, C + 1)
# returns - loss(N,)
defbayesian_categorical_crossentropy(T, num_classes):
defbayesian_categorical_crossentropy_internal(true, pred_var):
# shape: (N,)
std = K.sqrt(pred_var[:, num_classes:])
# shape: (N,)
variance = pred_var[:, num_classes]
variance_depressor = K.exp(variance) -K.ones_like(variance)
# shape: (N, C)
pred = pred_var[:, 0:num_classes]
# shape: (N,)
undistorted_loss =K.categorical_crossentropy(pred, true, from_logits=True)
# shape: (T,)
iterable = K.variable(np.ones(T))
dist =distributions.Normal(loc=K.zeros_like(std), scale=std)
monte_carlo_results =K.map_fn(gaussian_categorical_crossentropy(true, pred, dist, undistorted_loss,num_classes), iterable, name='monte_carlo_results')
variance_loss = K.mean(monte_carlo_results,axis=0) * undistorted_loss
return variance_loss + undistorted_loss +variance_depressor
returnbayesian_categorical_crossentropy_internal
# for a singlemonte carlo simulation,
# calculate categorical_crossentropy of
# predicted logit values plus gaussian
# noise vs true values.
# true - truevalues. Shape: (N, C)
# pred - predictedlogit values. Shape: (N, C)
# dist - normaldistribution to sample from. Shape: (N, C)
# undistorted_loss- the crossentropy loss without variance distortion. Shape: (N,)
# num_classes - thenumber of classes. C
# returns - totaldifferences for all classes (N,)
defgaussian_categorical_crossentropy(true, pred, dist, undistorted_loss,num_classes):
def map_fn(i):
std_samples =K.transpose(dist.sample(num_classes))
distorted_loss =K.categorical_crossentropy(pred + std_samples, true, from_logits=True)
diff = undistorted_loss - distorted_loss
return -K.elu(diff)
return map_f
这里创建的损失函数基于本文中的损失函数。在本文中,损失函数创建了一个均值为零的正态分布和预测的方差。从分布中采样来扭曲预测的logit数值,并使用扭曲的预测(distorted predictions)来计算softmax分类交叉熵。损失函数运行T个蒙特卡洛样本,然后将T个样本的平均值作为损失。
【注】:logit定义如下
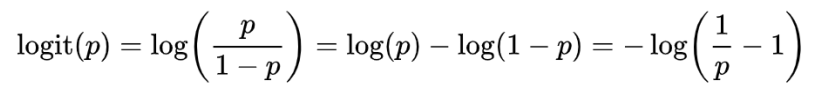
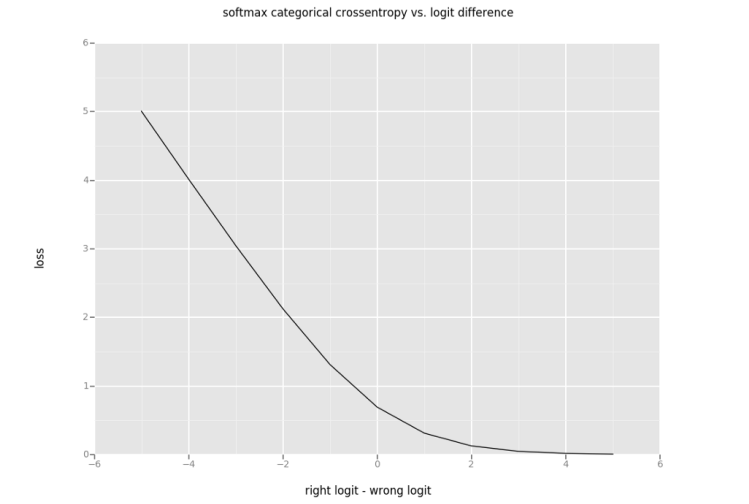
图9 二进制分类的Softmax分类交叉熵与logit差异
在图9中,y轴是softmax分类交叉熵。x轴是“right”logit值与“wrong”logit值之间的差异。“right”表示此预测的正确类。“wrong”表示此预测的错误类。用 ”logit差异”来表示图9的x轴。当图9中的 ”logit差异”为正时,softmax预测将是正确的。当”logit差异”为负时,预测将是不正确的。
图9有助于理解正态分布扭曲(distortion)的结果。当使用正态分布使logit值(在二元分类中)扭曲时,这个扭曲有效地创建原来预测的“logit差异”做分布均值、预测方差做分布方差的正态分布。将softmax交叉熵应用于扭曲的logit值与沿着图9中的线采样“logit差异”值相同。
采用扭曲logit的分类交叉熵理想情况下应该会产生一些有趣的属性。
1. 当预测的logit值远大于任何其他logit值(图9右边)时,增加方差应该只会增加损失。这是正确的,因为在图9右边导数是负的。即增加“logit差异“,相比于同等的“logit差异”减少,只导致softmax分类交叉熵略微减小。在这种情况下,最小损失应接近0。
2. 当”wrong”logit远大于”right”logit(图9的左边)并且方差大约为0时,丢失应该大约是wrong_logit-right_logit。你可以看到这是在图9的右边。当”logit差异”是-4时,softmax交叉熵是4。图9的这一部分的斜率大约是-1,应该真的”logit差异”是在继续下降。
3. 为了使模型能够学习任意不确定性,当”wrong”的logit值大于”right”logit值(图9左半部分)时,最小化损失函数的应该是大于0的方差。具有较高任意不确定性(即模型难以对该图像进行准确预测)的图像,该特征鼓励模型在训练期间通过增加预测方差来找到局部损失最小值。
通过增加方差,当“wrong”logit值大于“right”logit值时,可以用建议的损失函数来减少损失,但增加方差导致的损失减小非常小(<0.1)。在训练期间,模型很难在这个轻微的局部最小值上找到,而模型中任意方差(aleatoric variance)的预测没有意义。相信这是因为图9的左半部分斜率是-1。沿着斜率为-1的直线对正态分布进行采样将造成另一个正态分布,并且平均值与之前大致相同,但我们想要的是,随着方差增加T个样本的平均减小。
为了使模型更容易训练,想要的是,随着方差增加带来更显着的损失变化。上述损失函数用均值0和预测方差的正态分布扭曲了T蒙特卡洛样本的logit数值,然后计算了每个样本的分类交叉熵。为了在方差增加时获得更显著的损失变化,对损失减少的蒙特卡罗样本,比起那些损失增加的样本,损失函数加权更多。解决方案是使用ELU(exponential linear unit)激活函数,这是一个以0为中心的非线性函数,如图10所示。
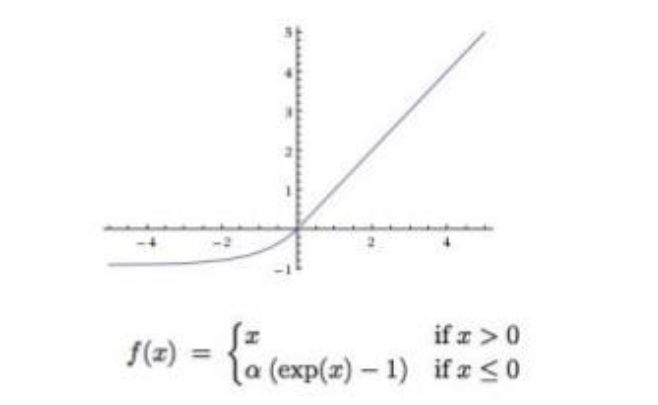
图10 ELU函数
将ELU函数用于分类交叉熵的改变,即扭曲损失和原始未扭曲损失相比,undistorted_loss - distorted_loss。对于图9的左半部分,ELU使正常分布的平均值偏离零。对于接近0的非常小数,ELU也是线性的,因此图9的右半部分的平均值保持不变。
如图11所示,right < wrong对应于图9左半部分的一个点,wrong < right对应于图9右半部分的一个点。可以看到“wrong”logit的结果分布,看起来类似于正态分布,“right”logit大多是接近零的小值。对损失的变化应用-elu,right < wrong的均值变得更大。在此例子中,它从-0.16变成0.25。wrong < right的均值保持不变。图11中下图的均值称为“损失的扭曲平均变化”。在图9的右半部分,随着方差增加,“损失的扭曲平均变化”应该保持在0附近,并且应该总是增加。
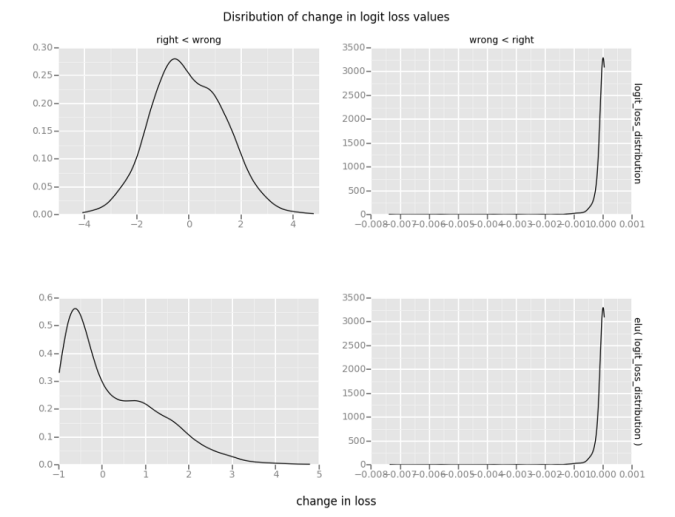
图11 损失的平均变化和损失的扭曲平均变化
然后,通过原始未扭曲的分类交叉熵来缩放“损失的扭曲平均变化”。这样做是因为对于大于3的所有logit差异,”wrong”logit情况下扭曲平均变化大致相同(因为导数为0)。为了确保损失大于零,添加未扭曲的分类交叉熵。“损失的扭曲平均变化”总是随着方差的增加而减小,但是对于小于无穷大的方差,损失函数应该最小化。为了确保最小化损失的方差小于无穷大,添加了方差指数。如图12所示,方差指数是方差大于2以后的主要特性。
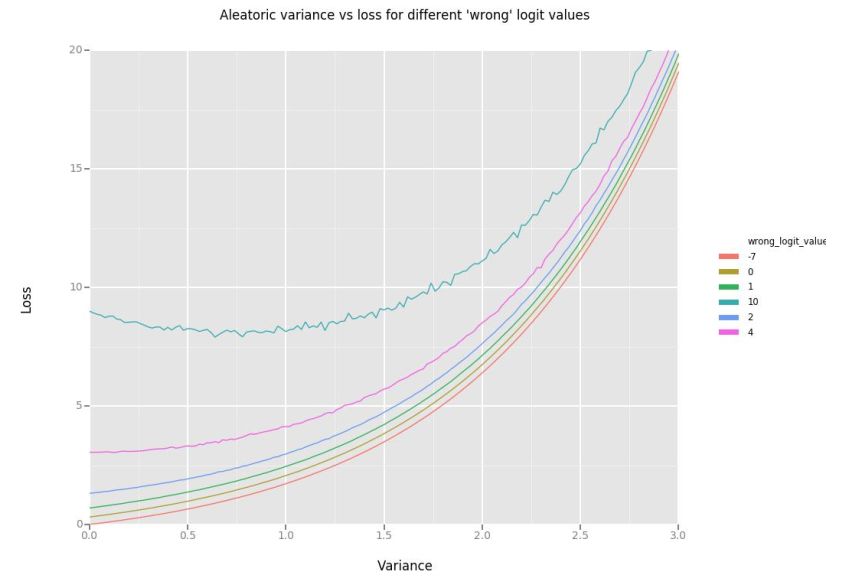
图12 不同“错误”logit值的任意方差-损失
表1如下是计算二元分类例子损失函数的结果,其中“right”logit值保持为1.0,而 “wrong”logit值每行发生变化。当”wrong”logit小于1.0(因此小于”right”logit值),最小方差为0.0。随着“wrong”logit值增加,最小化损失的方差也会增加。
注意:运行10,000次蒙特卡罗模拟才创建平滑线条。在训练模型时,只进行100次蒙特卡罗模拟,这足以得到合理的均值。
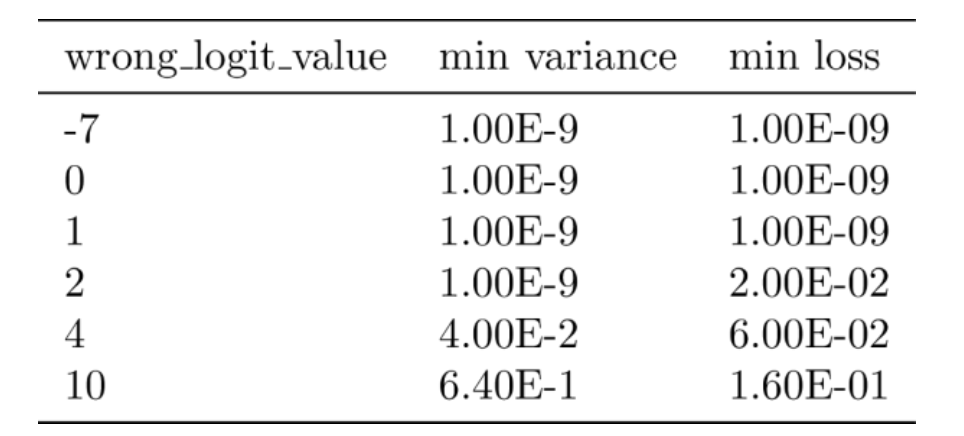
表1 不同“错误”logit值的最小任意差异和最小损失
• 计算认知不确定性
对认知不确定性建模的一种方法是在测试时使用蒙特卡洛退出采样(dropout sampling),一种变分推理。注:退出是一种避免在简单网络中过拟合的技术,即模型无法从其训练数据到测试数据的泛化。在实践中,蒙特卡洛退出采样意味着模型包括退出并且模型测试时打开退出多次运行得到结果分布。然后,可以计算预测熵(预测分布的平均信息量)。
要了解使用退出计算认知不确定性,请考虑将猫狗图像垂直分成两半,如图13所示。如果看到左半边,你会预测狗。如果看到右半边,你会预测猫。完美的50-50分裂。这个图像具有很高的认知不确定性,因为它具有与猫类、狗类相关联的特征。

图13 猫-狗分开的图像
以下是两种计算认知不确定性的方法。完全相同的做法,但第一个更简单,只使用numpy,第二个使用额外的Keras层(并获得GPU加速)预测。
# model - thetrained classifier(C classes)
# wherethe last layer applies softmax
# X_data - a list ofinput data(size N)
# T - the number ofmonte carlo simulations to run
defmontecarlo_prediction(model, X_data, T):
# shape: (T, N, C)
predictions =np.array([model.predict(X_data) for _ in range(T)])
# shape: (N, C)
prediction_probabilities =np.mean(predictions, axis=0)
# shape: (N)
prediction_variances =predictive_entropy(prediction_probabilities)
return (prediction_probabilities,prediction_variances)
# prob - predictionprobability for each class(C). Shape: (N, C)
# returns - Shape:(N)
defpredictive_entropy(prob):
return -1 * np.sum(np.log(prob) *prob, axis=1)
from keras.modelsimport Model
from keras.layersimport Input, RepeatVector
fromkeras.engine.topology import Layer
fromkeras.layers.wrappers import TimeDistributed
# Take a mean of theresults of a TimeDistributed layer.
# ApplyingTimeDistributedMean()(TimeDistributed(T)(x)) to an
# input of shape(None, ...) returns output of same size.
classTimeDistributedMean(Layer):
def build(self, input_shape):
super(TimeDistributedMean,self).build(input_shape)
# input shape (None, T, ...)
# output shape (None, ...)
def compute_output_shape(self,input_shape):
return (input_shape[0],) +input_shape[2:]
def call(self, x):
return K.mean(x, axis=1)
# Apply thepredictive entropy function for input with C classes.
# Input of shape(None, C, ...) returns output with shape (None, ...)
# Input should bepredictive means for the C classes.
# In the case of asingle classification, output will be (None,).
classPredictiveEntropy(Layer):
def build(self, input_shape):
super(PredictiveEntropy,self).build(input_shape)
# input shape (None, C, ...)
# output shape (None, ...)
def compute_output_shape(self,input_shape):
return (input_shape[0],)
# x - prediction probability for eachclass(C)
def call(self, x):
return -1 * K.sum(K.log(x) *x, axis=1)
defcreate_epistemic_uncertainty_model(checkpoint, epistemic_monte_carlo_simulations):
model = load_saved_model(checkpoint)
inpt =Input(shape=(model.input_shape[1:]))
x =RepeatVector(epistemic_monte_carlo_simulations)(inpt)
# Keras TimeDistributed can onlyhandle a single output from a model :(
# and we technically only need thesoftmax outputs.
hacked_model =Model(inputs=model.inputs, outputs=model.outputs[1])
x = TimeDistributed(hacked_model,name='epistemic_monte_carlo')(x)
# predictive probabilities for eachclass
softmax_mean = TimeDistributedMean(name='epistemic_softmax_mean')(x)
variance =PredictiveEntropy(name='epistemic_variance')(softmax_mean)
epistemic_model = Model(inputs=inpt,outputs=[variance, softmax_mean])
return epistemic_model
# 1. Load the model
# 2. compile themodel
# 3. Set learningphase to train
# 4. predict
def predict():
model =create_epistemic_uncertainty_model('model.ckpt', 100)
model.compile(...)
# set learning phase to 1 so that Dropout ison. In keras master you can set this
# on the TimeDistributed layer
K.set_learning_phase(1)
epistemic_predictions =model.predict(data)
注意:认知不确定性不用于训练模型,它仅在评估实验/现实世界例子的测试时(但在训练阶段)估计。这与任意不确定性不同,后者预测为训练过程的一部分。而且,根据经验,认知不确定性比任意不确定性更容易产生合理的预测。
6. 训练贝叶斯深度学习分类器
除了上面的代码之外,训练贝叶斯深度学习分类器来预测不确定性,不需要训练一般分类器以外的额外代码。
def resnet50(input_shape):
input_tensor =Input(shape=input_shape)
base_model =ResNet50(include_top=False, input_tensor=input_tensor)
# freeze encoderlayers to prevent over fitting
for layer inbase_model.layers:
layer.trainable= False
output_tensor =Flatten()(base_model.output)
returnModel(inputs=input_tensor, outputs=output_tensor)
这个实验用Resnet50的冻结卷积层和来自ImageNet的权重来编码图像。最初试图在没有冻结卷积层的情况下训练模型,但发现模型很快过拟合。
def create_bayesian_model(encoder, input_shape, output_classes):
encoder_model =resnet50(input_shape)
input_tensor =Input(shape=encoder_model.output_shape[1:])
x =BatchNormalization(name='post_encoder')(input_tensor)
x =Dropout(0.5)(x)
x = Dense(500,activation='relu')(x)
x =BatchNormalization()(x)
x =Dropout(0.5)(x)
x = Dense(100,activation='relu')(x)
x =BatchNormalization()(x)
x =Dropout(0.5)(x)
logits =Dense(output_classes)(x)
variance_pre =Dense(1)(x)
variance =Activation('softplus', name='variance')(variance_pre)
logits_variance =concatenate([logits, variance], name='logits_variance')
softmax_output =Activation('softmax', name='softmax_output')(logits)
model =Model(inputs=input_tensor, outputs=[logits_variance,softmax_output])
return mode
模型的可训练部分是ResNet50输出层之上的两组BN、Dropout、Dense和ReLU层。用单独的Dense层计算logits和方差。请注意,方差层(the variance layer)用softplus激活函数以确保模型始终预测大于零的方差值。然后,将logit和方差层重新组合用于任意损失(aleatoric loss)函数,并且仅使用logit层计算softmax。
model.compile(
optimizer=Adam(lr=1e-3,decay=0.001),
loss={
'logits_variance':bayesian_categorical_crossentropy(100, 10),
'softmax_output':'categorical_crossentropy'
},
metrics={'softmax_output':metrics.categorical_accuracy},
loss_weights={'logits_variance':.2, 'softmax_output': 1.})
使用两个损失训练模型,一个是任意不确定性损失函数,另一个是标准分类交叉熵函数。允许创建logits的最后一个Dense层仅学习如何产生更好的logit值,而创建方差的Dense层仅学习预测方差。这两个先前的Dense层将对这两种损失进行训练。任意不确定性损失函数的加权值小于分类交叉熵损失,因为分类交叉熵损失是任意不确定性损失中的一项。
使用100蒙特卡罗模拟来计算贝叶斯损失函数。每个训练时期(epoch)花了大约70秒。发现当蒙特卡罗模拟量从100增加到1,000,每个训练时期增加了大约4分钟。
随机取伽玛值等于0.5或2.0来减少或增加每个图像的亮度,这样可添加增强数据(augmented data)到训练集中,如图14所示。实践中,发现cifar10数据集并没有很多任意不确定性理论上很高的图像。这可能是设计的。调整伽玛值的图像添加到训练集,可以给模型提供更多高任意不确定性的图像。

图14 图像亮度变化
不幸的是,预测认知不确定性需要相当长的时间。对于全连接层,Mac CPU需要大约2-3秒来预测训练集的所有50,000个类,但对于认知不确定性预测,这个过程超过五分钟。这并不惊讶,因为认知不确定性需要在每张图像上运行蒙特卡罗模拟。运行100次蒙特卡罗模拟,可以合理地估计,预测过程花费大约100倍时间来预测认知不确定性而不是任意不确定性。
这个项目【4】可轻松切换底层编码器网络(encoder network),并为以后其他的数据集来训练模型。
7. 实验结果

图15 cifar10数据集的例子
在测试数据集上,模型分类准确率为86.4%。实际上能够产生高于93%的分数,但只能牺牲任意不确定性的准确性。可以使用一些不同的超参数来提高分数,但贝叶斯深度学习关心的是预测和不确定性估计,所以下面主要评估模型不确定性预测的有效性。
任意不确定性值往往比认知不确定性小得多,如表2所示。这两个值无法直接在同一图像上进行比较。然而,在同一数据集可以和模型为其他图像预测的不确定性值进行比较。
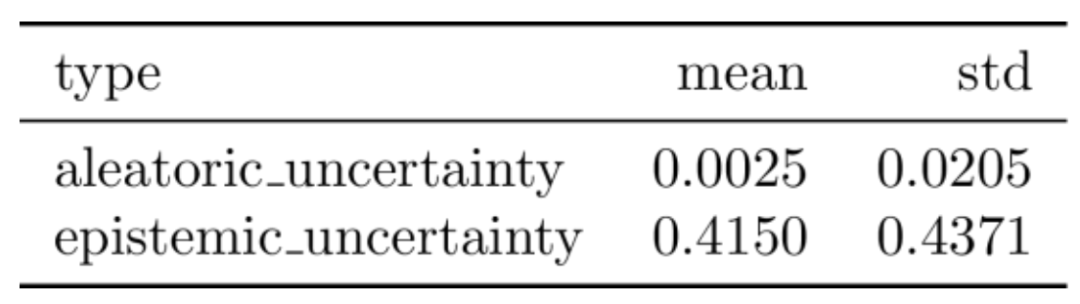
表2 测试集的不确定性均值和方差
为了进一步探索不确定性,根据”right”logit的相对值将测试数据分成三组。在表3中,”first”包括所有正确的预测(带有”right”标签的logit值是最大值)。”second”,包括”right”标签是第二大logit值的所有情况。“rest”包括所有其他情况。86.4%的样本属于“第一”组,8.7%属于“第二”组,4.9%属于“休息”组。表3显示了这三组测试集的任意不确定性和认知不确定性的均值和标准方差。正如所希望的那样,认知不确定性和任意不确定性与“right”logit的相对排序相关。这表明模型更可能确认不正确的标签,因为此时它不确定。此外,当模型的预测正确时,模型预测大于零不确定性(zero uncertainty)。期望这个模型能够展现出这种特性,因为即使模型预测正确,模型也不确定。

表3 “正确”logit相对值排序的不确定性

图16 最高任意不确定性的图像

图17 最高认知不确定性的图像
图16和图17分别是具有最高任意不确定性和认知不确定性的图像。训练图像分类器产生不确定性的一个缺点是没有直观性,整个图像的不确定性变成单个值。通常在图像分割模型中不确定性理解要容易得多,因为更容易比较图像中每个像素的结果(如图3所示)。
如果模型很好地理解任意不确定性,则它应该预测出那些较低对比度、高亮度/暗度或高遮挡的图像有较大的任意不确定度值。为此,将一系列伽玛值应用于测试图像以增加/减少像素强度,以及数据增强的预测结果,如图18所示。

图18 数据增强和原始数据的不确定性比较(左边:增强,右边:原始)
在数据增强后的图像,模型准确度为5.5%。这意味着伽马图像完全欺骗了模型。该模型没有经过训练,无法在这些伽马扭曲上得分。图18显示了左侧八个数据增强的图像以及预测不确定性和右侧八个原始图像和不确定性。前四幅图像是数据增强中任意不确定性预测最高,后四幅图像是数据增强中任意不确定性预测最低。
8. 下一步
这里模型仅探讨了贝叶斯深度学习冰山一角(the tip of the iceberg),并且是可以通过几种方式来改进模型的预测。例如,可以继续使用损失权重并解冻Resnet50卷积层,看看是否可以在不丢失不确定性特征情况下获得更好的准确度分数。还可以尝试在一个新数据集上训练模型,它具有更多高度任意不确定性的图像。一个候选是德国交通标志识别基准数据集(German Traffic Sign Recognition Benchmark dataset)。该数据集专门用于“应对由于光照变化、部分遮挡、旋转、天气条件引起的视觉外观的大变化” 的分类器。
除了改进模型,还可以进一步探索训练的模型。一种方法是查看模型如何处理对抗性示例(adversarial examples)。为此,可以使用像Ian Goodfellow创建的CleverHans库。该库使用对抗NN来帮助探索模型漏洞。
另一个可探索的库是Edward,一个用于概率建模、推理和批评的Python库。Edward支持使用概率分布创建网络层,并可以轻松进行变分推理(variational inference)。
本文作者简介:
黄浴,奇点汽车美研中心总裁和自动驾驶首席科学家,上海大学兼职教授。曾在百度美研自动驾驶组、英特尔公司总部、三星美研数字媒体研究中心、华为美研媒体网络实验室,和法国汤姆逊多媒体公司普林斯顿研究所等工作。发表国际期刊和会议论文30余篇,申请30余个专利,其中13个获批准。
参考文献
1.网页:https://towardsdatascience.com/building-a-bayesian-deep-learning-classifier-ece1845bc09
2.网页:https://alexgkendall.com/computer_vision/bayesian_deep_learning_for_safe_ai/
3.网页:http://mlg.eng.cam.ac.uk/yarin/blog_3d801aa532c1ce.html
4.项目:https://github.com/kyle-dorman/bayesian-neural-network-blogpost
5.代码:https://github.com/yaringal/DropoutUncertaintyCaffeModels
6.A Kendall and Y Gal, “What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? ”,2017.
7.A Kendall, Y Gal,R Cipolla, “Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics”. 2017.
重磅!CVer学术交流群成立啦
扫码添加CVer助手,可申请加入CVer-目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测和模型剪枝&压缩等群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡)

▲长按加群

▲长按关注我们
麻烦给我一个在看!

