【AAAI2020】CompFeat:用于视频实例分割的综合特征聚合

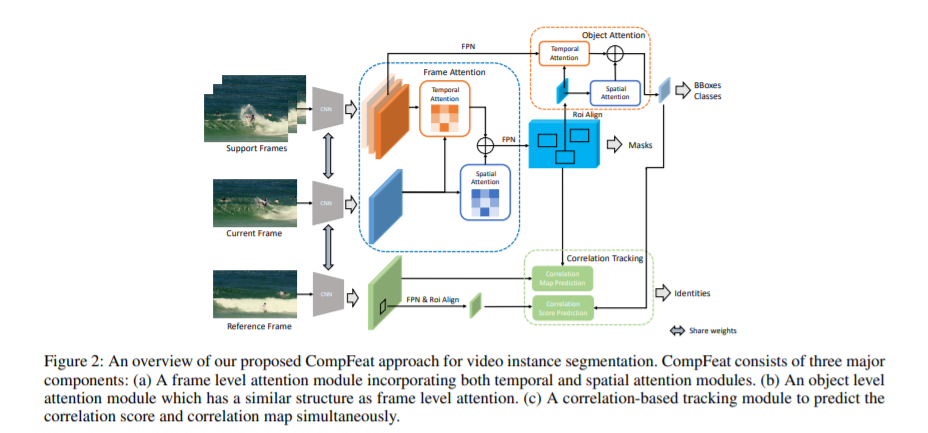
视频实例分割是一项复杂的任务,我们需要检测、分割和跟踪任何给定视频的每个对象。以往的方法只利用单帧特征来检测、分割和跟踪目标,而目标在视频场景中会因为运动模糊和剧烈的外观变化等问题而受到影响。为了消除仅使用单帧特征所带来的模糊性,我们提出了一种新的综合特征聚合方法(CompFeat),利用时间和空间上下文信息在帧级和对象级对特征进行细化。聚合过程是精心设计的一个新的注意机制,这大大增加了识别能力的学习特征。通过结合特征相似性和空间相似性的暹罗设计,进一步提高了模型的跟踪能力。在YouTube-VIS数据集上进行的实验验证了提出的CompFeat的有效性。我们的代码将在https://github.com/shi-labs/compfeat-forvideo - instance - segmentation提供。
https://www.zhuanzhi.ai/paper/75826e28ffd73a97436d5b2eac711f7f
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“CFEA” 就可以获取《【AAAI2020】CompFeat:用于视频实例分割的综合特征聚合》专知下载链接



登录查看更多
相关内容
专知会员服务
36+阅读 · 2020年3月12日
专知会员服务
30+阅读 · 2020年1月2日
Arxiv
8+阅读 · 2018年4月11日




相关VIP内容
专知会员服务
36+阅读 · 2020年3月12日
专知会员服务
30+阅读 · 2020年1月2日
相关资讯