前端质量|基于业务驱动的前端性能有效实践案例

一、背景
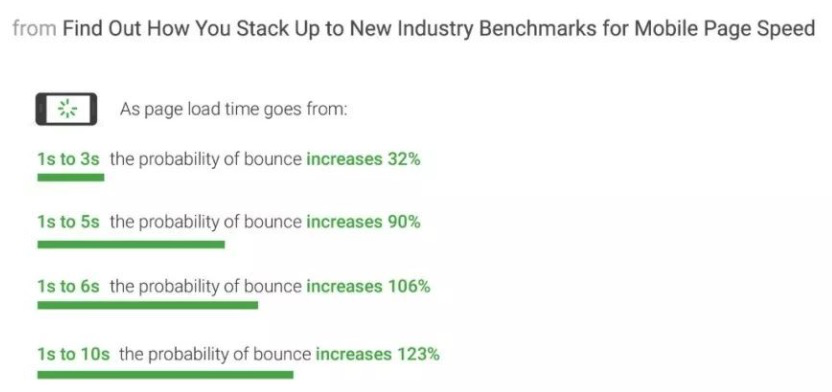
1.1.前端性能优化的业务意义
1.2.测试把控难点
-
现在流行的,运营自行搭建页面+自行多端投放 方式,使我们的不可控。
-
原先发现性能问题主要通过感受+性能跑测数据,或者运营以业务要挟、或者质疑受机器等因素影响、或者相互推诿主要瓶颈点,使优化无法落实。
-
部分性能优化困难,影响性能点比较复杂,实行优化的收益不可预知,也阻碍了优化的落实。
二、前端性能优化 测试视角的解法
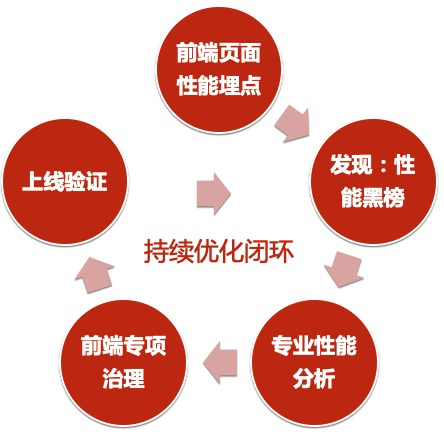
2.1.可持续优化闭环
2.2.效果明显
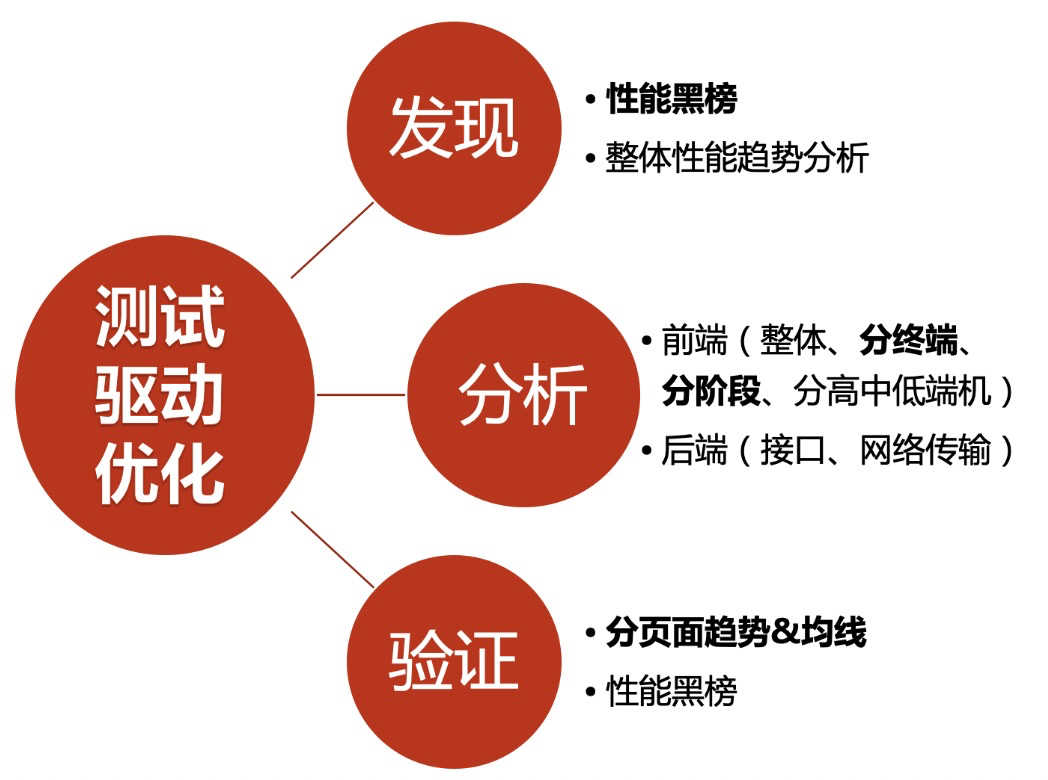
三、性能问题的发现
3.0.性能数据的采集
3.0.1.几个名词解释
3.0.2.全过程
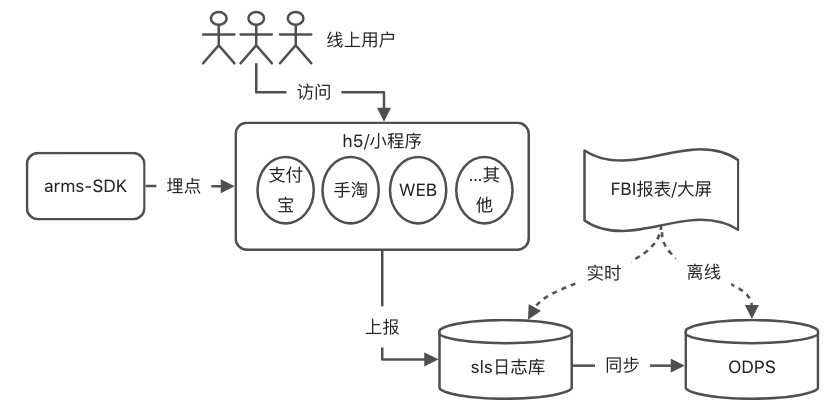
-
针对H5搭建页的埋点,使用通用方案,一次性埋点即可,前端后续无需额外埋。 -
sls日志报表查实时数据,用于实时分析,实时验证。 -
ODPS数据长期存储已计算完指标的数据,用于记录、比较、趋势分析。
3.1.性能指标的确定
3.1.1.统计范围--用户视角
3.1.2.三个指标
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3.2.性能黑榜
-
排在性能黑榜前列的,必然是性能问题最突出的,相对方便分析
-
再结合样本量(pv正相关)数据,样本量非常大的,性能优化的收益必然也是非常大的
-
模块化组件开发盛行的今天,优化某个模块或场景的问题,收益点不仅仅在当前页面,也在其他用了同样模块或场景的页面
-
榜单形式,更能引起老板、对应前端负责同学、对用户体验关注的同学的重视
3.3.整体性能趋势分析
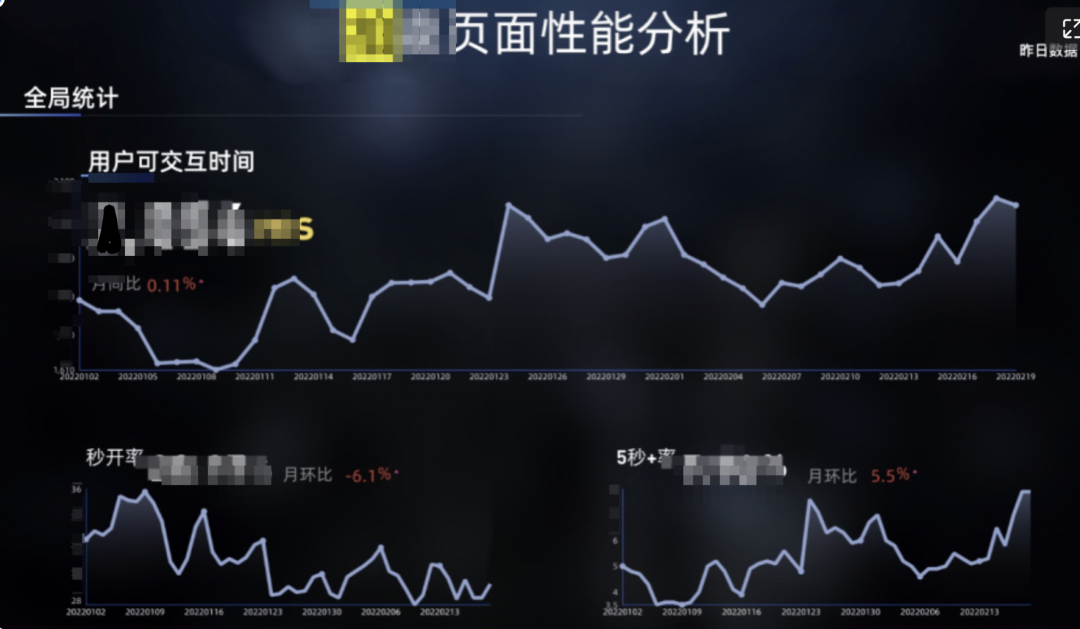
四、性能问题的分析
4.1.如何衡量性能问题严重性
4.1.0.进入性能黑榜前几名
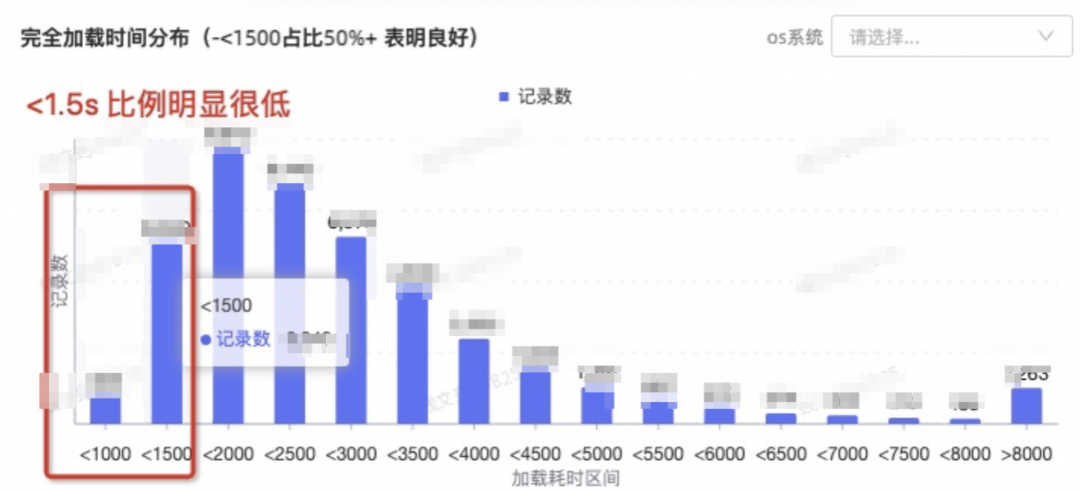
4.1.1.看完全加载时长分布
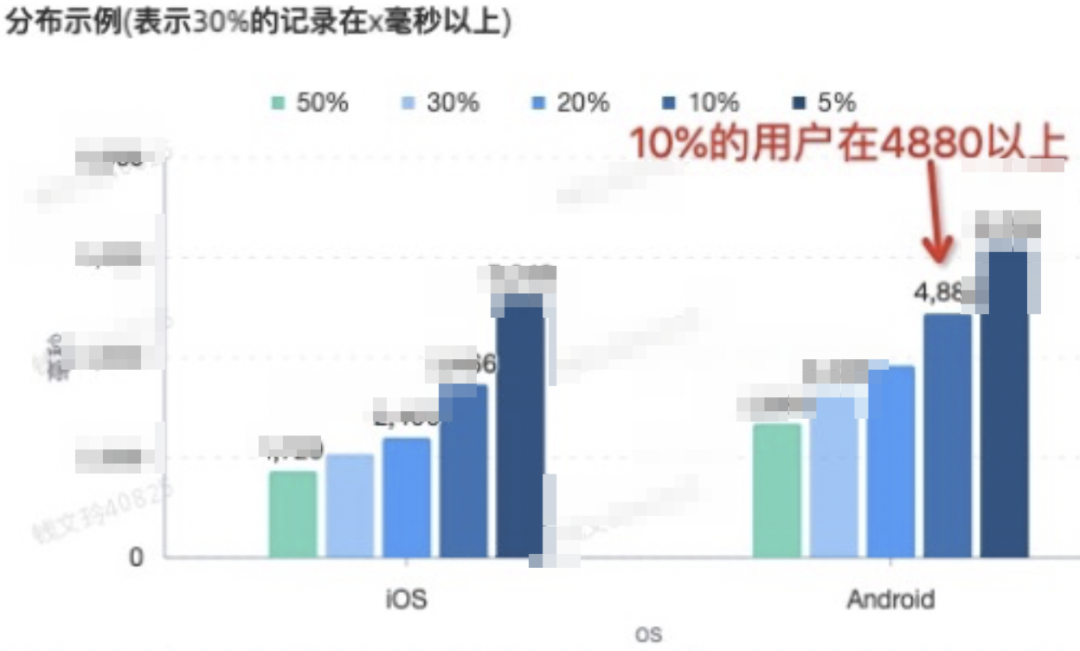
4.1.2.看时长分布比例
4.1.3.看和总体数据的对比

4.2.分析性能瓶颈-分析思路
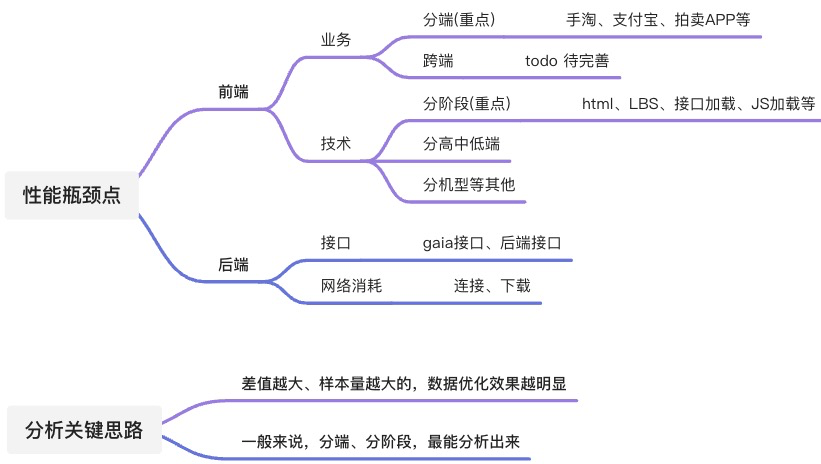
4.3.分析性能瓶颈-前端环节
4.3.1.分终端分析
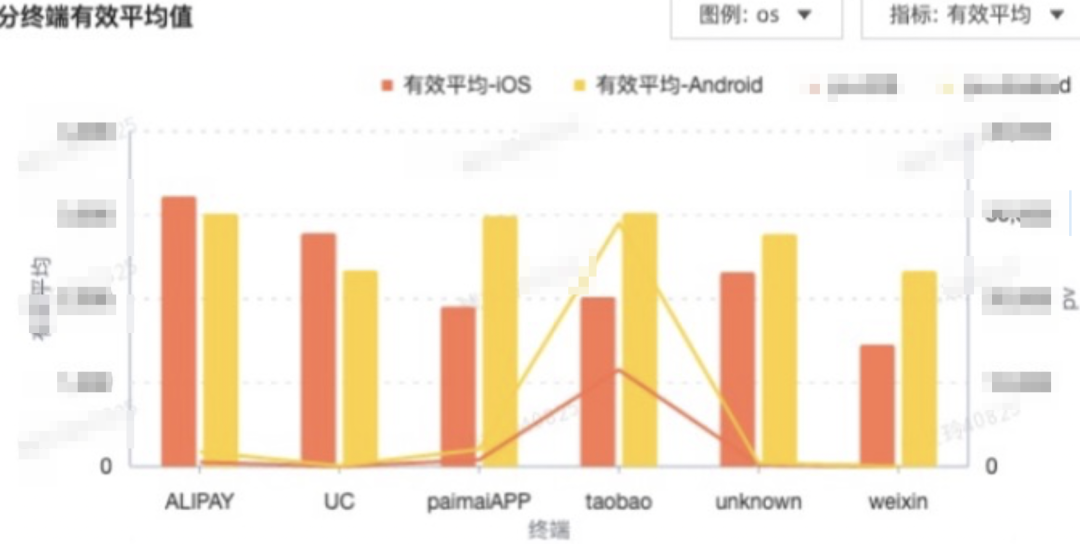
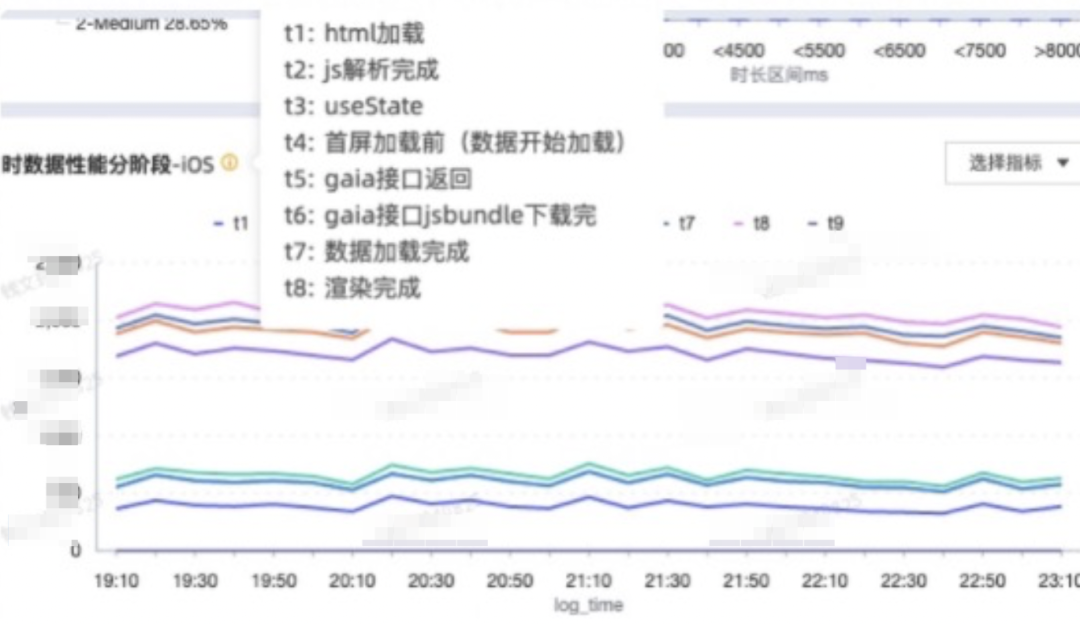
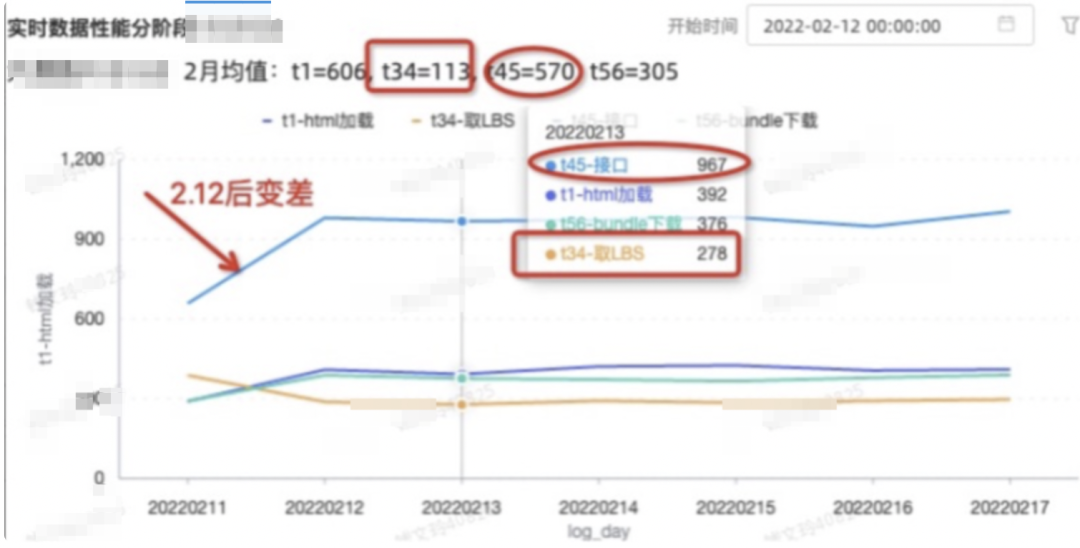
4.3.2.分阶段分析
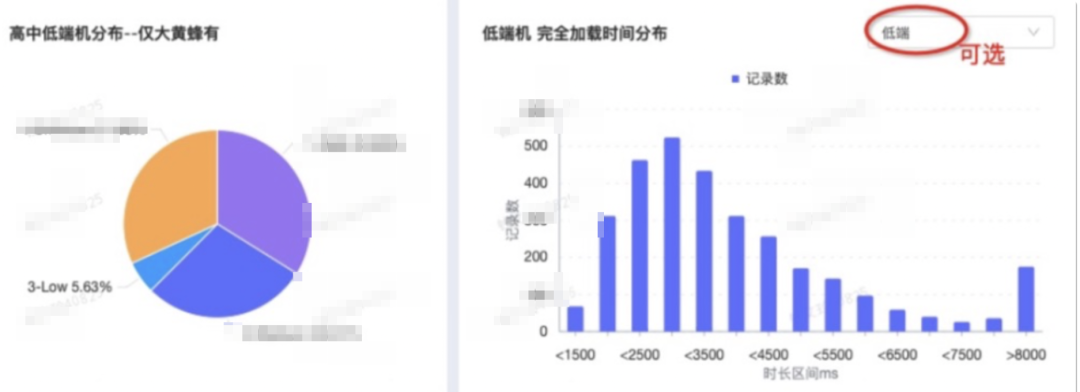
4.3.3.分高中低端机分析
4.3.4.其他分析
4.4.分析性能瓶颈-后端环节
4.4.1.后端接口分析
-
服务端链路逻辑,需要另做具体分析 -
分页面的处理逻辑,需要结合业务逻辑来看
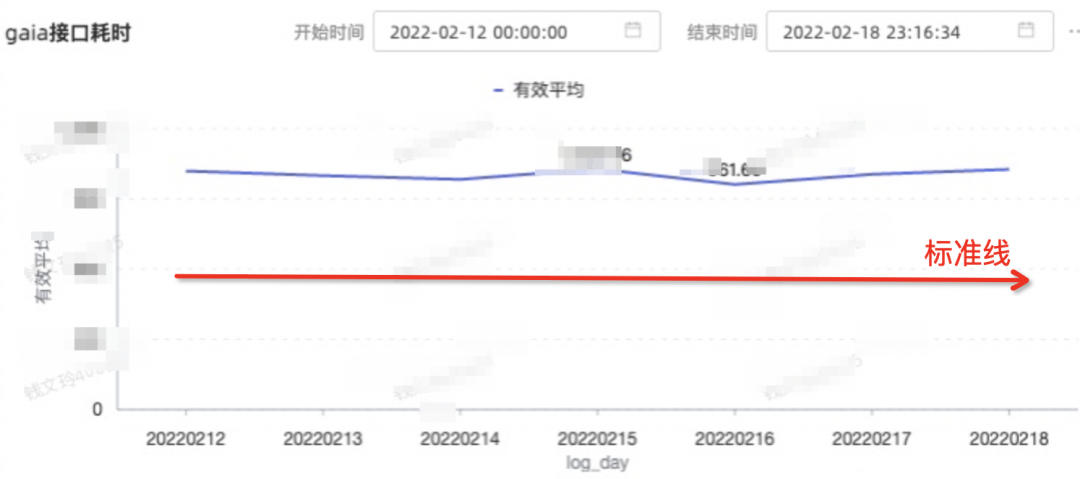
4.4.2.网络传输消耗分析
4.5.分析结论关键思路
五、性能问题的验证
-
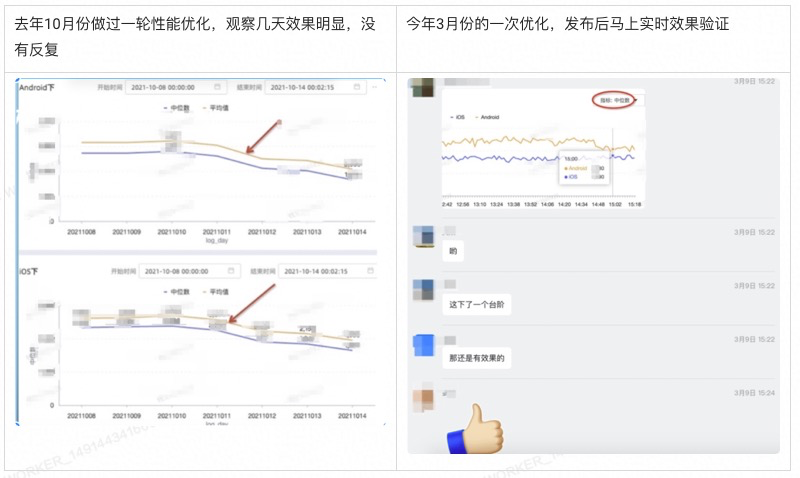
验证性能优化效果,做到可量化 -
及时洞察到页面性能向差的趋势,更具有主动性
5.1.性能恶化及时反馈
5.2.性能优化效果验证
R语言编程基础(U3010001)
R是用于统计分析、绘图的语言和操作环境,属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
R语言语法通俗易懂,很容易学会和掌握语言的语法。而且学会之后,我们可以编制自己的函数来扩展现有的语言。这也就是为什么它的更新速度比一般统计软件,如SPSS、SAS等快得多。大多数最新的统计方法和技术都可以在R中直接得到。
点击阅读原文查看详情。
登录查看更多
相关内容
专知会员服务
24+阅读 · 2022年3月24日
Arxiv
0+阅读 · 2022年7月28日
Arxiv
0+阅读 · 2022年7月28日
Arxiv
0+阅读 · 2022年7月27日
Arxiv
0+阅读 · 2022年7月27日
Arxiv
0+阅读 · 2022年7月27日
Arxiv
16+阅读 · 2019年5月24日

相关VIP内容
专知会员服务
24+阅读 · 2022年3月24日
相关资讯