人脸风格迁移出现新玩法!捷克理工大学联合 Snap 公司创建了一个用于视频中人脸风格实时迁移的框架,既不需要大型数据集和冗长训练周期,更能够在移动端运行。
今年,人脸视频特效在全球又大火特火了一把。年初的「蚂蚁牙黑」(人脸唱歌),还有不久前让老照片动起来的特效,效果都十分惊艳。
风格迁移一直是图像领域的热门方向。那么在视频上做实时人脸画风迁移效果怎么样呢?
![]()
![]()
![]()
当然,视频画风迁移并不是什么新鲜技术了。但这项研究最大的特点在于:
移动端、实时
,由布拉格捷克理工大学和 Snap 公司的研究者联合完成。目前已经放出了完整论文,相关代码将于下月发布。
![]()
具体而言,研究者提出了一种基于实例的实时视频人脸风格迁移框架 FaceBlit,该框架通过语义上有意义的方式保留了风格的纹理细节,也就是说,用于描绘特定风格特征的笔画出现在目标图像的适当位置。
与以往风格迁移方法相比,该框架不仅保留了目标对象(target subject)的身份,而且不需要大型数据集和冗长训练周期即可实现实时运行。
为此,研究者修改了 Fišer 等人(2017 年)的人脸风格化 pipeline,这样快速生成一组指引通道(guiding channel),不仅可以保留了目标对象的身份,还兼容 Sýkora 等人(2019 年)的基于 patch 合成算法的速度更快变体。
得益于这些方法上的改进,研究者创建了首个即使在
移动端
,也可以将
单个肖像的艺术风格实时迁移至目标视频中人脸的系统框架
。
该研究方法的输入是人脸的风格范例图像𝑆以及目标人脸视频序列 T。研究假设脸部表情的改变以及移动都是基于受试者注视摄像头,并且不被其他物体遮挡。该研究的输出是一个风格化的序列𝑂,它保留了𝑆的重要艺术特征,同时保留了目标主体的身份。尽管已经可以使用 Fišer 等人 [2017] 的方法产生这种输出,但这里的一个主要缺点是,他们的方法仅适用于离线处理。
为了实现实时性能,研究者需要改变计算指引通道的方式,并用 Sýkora 等人 [2019] 提出的更快的变体取代 Fišer 等人 [2016] 的基于缓慢 patch 的合成算法。
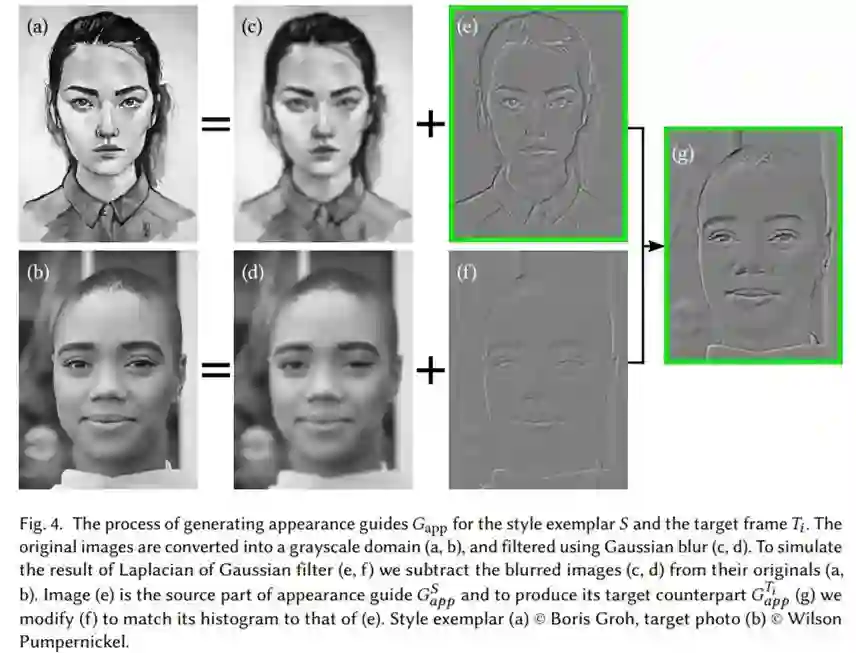
在 Fišer 等人提出的方法中,四个指引通道用于驱动合成。分割指引𝐺_seg,通过将面部细分为一组区域(头发、眉毛、鼻子、嘴唇、口腔、眼睛和皮肤)来描绘重要的面部特征;位置指引(positional guide)𝐺_pos,对源面部和目标面部之间的空间对应关系进行编码。这两个通道确保语义上有意义的迁移。
![]()
为了保持目标对象的身份特征,Fišer 等人采用了一种外观指引(appearance guide)𝐺_app 方法,通过使用 Shih 等人的摄影风格迁移方法使源图像和目标图像的外观均衡,从而减少了源图像和目标图像之间的域间隙。最后,时间指引𝐺_temp 来执行时间一致性,而𝐺_temp 由风格化帧的运动 - 补偿版本表示。
![]()
由于上述指引通道的计算需要几十秒的时间,因此在实时场景下使用它们是不容易处理的。相反,该研究将四通道简化为两个基本的通道𝐺_pos 和 𝐺_app(图 2 所示),改变底层生成算法,
将准备时间减少到几十毫秒
。最后,该研究演示了如何将这两个新的指引通道融入到 Sýkora 等人 [2019] 的快速合成算法中。
![]()
研究者表示,与其他风格迁移方法相比,生成效果如此好的关键在于三个方面:
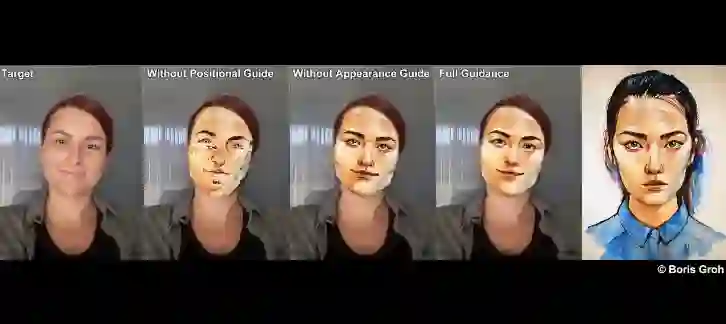
位置指引、外观指引和直方图匹配
。下图为有无位置和外观指引的生成效果图对比,可以看到在
无位置指引或外观指引的情况下
,生成的动态效果图都不同程度地存在着瑕疵:
![]()
此外,在生成目标外观指引 G^T_app 时,直方图匹配也非常重要。从技术上来看,如果不匹配外观指引的直方图,则误差 E 会很快超过阈值 t,这会导致 chunk 明显变小,结果看起来可能会变得模糊。如下图 8a 所示,无直方图匹配时,目标对象的身份无法很好地保留,生成效果比较模糊;而如图 8b 所示,在进行直方图均衡化之后,生成效果有了明显改善,更清晰了。
![]()
![]()
最后,研究者使用一种混合方法,使得目标肖像画栩栩如生,「复刻」视频中人脸的各种表情神态。
![]()
![]()
中文NLP:2021海华AI挑战赛火热报名中!
由海华研究院与清华大学交叉信息研究院联合主办的“2021海华AI挑战赛·中文阅读理解”正在进行,上届决赛答辩仪式,姚期智院士为大家深情致辞,所有获奖选手也都收到了姚先生亲笔签名的证书。
本届大赛依然保留中学组及技术组两条赛道,共设30万元奖金池,诗词AI,智慧中文,点击阅读原文或立即扫码报名!
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com