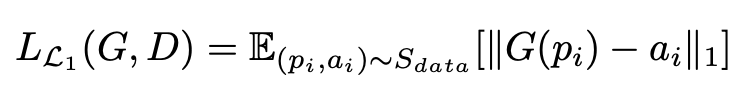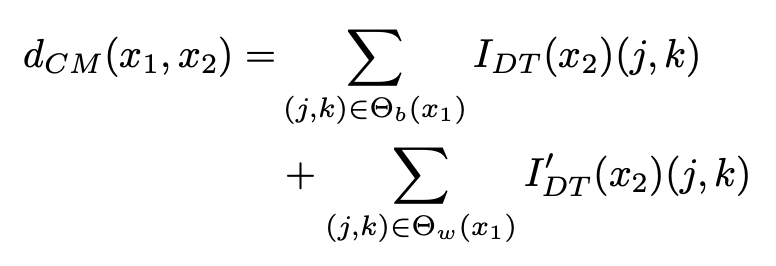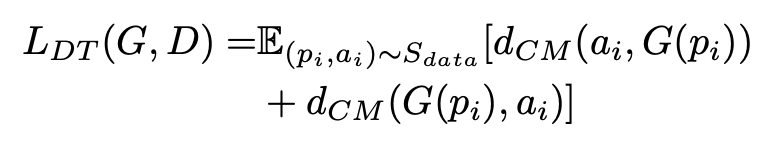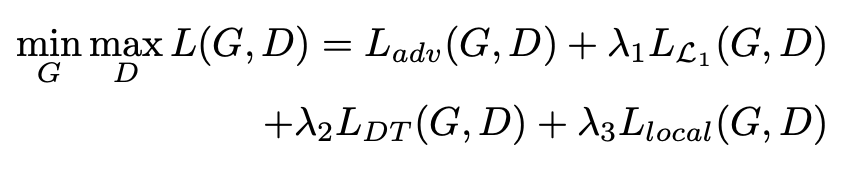作者丨武广
学校丨合肥工业大学硕士生
研究方向丨图像生成
固定的应用场景对于泛化的图像翻译模型来说存在着一定的局限性,往往需要根据实际的需求对网络和细节进行设计以达到特定的效果。图像转换模型中 CycleGAN、Pix2Pix、StarGAN、FUNIT 都是泛化较好的模型,然而对于特定需求还是需要更为细致的设计。
本篇的目的是为了解读在人脸到肖像画的图像翻译任务下,如何做到这种固定需求的高质量图像转换。本篇的主角是 APDrawingGAN,同时也是 CVPR 2019 Oral,实现了高质量的人脸到肖像图的转换。
![]()
![]()
论文引入
肖像画是一种艺术表现形式,可以简单的通过线条去捕捉人的独特外观,并且可以做到高相似度的描述。这类素描图往往需要艺术家在人或他们的照片面前绘制,且依赖于整体的观察、分析和经验去创作。一副好的肖像画可以形象的表征人的个性和神气,这往往需要一个受过好的培训的艺术家几个小时的时间去创作。
这种耗时的工作当然可以交给计算机去实现了,但是在实现之前还是要分析一下这项任务的难点。艺术肖像画(APDrawings)是高度抽象的,包含少量稀疏但连续的图形元素(线条)。
同时,APDrawings 涉及数千个不同大小和形状的笔画的密集集合,面部特征下一些小的伪像也能被清楚的看到,面部特征不能有错位、移位出现。不同人物的肖像结构是变化的,没有固定的精确位置,再者为了体现发型的流动性,往往 APDrawings 会有一些指示头发流动的线条。
综合这些难点,想实现一个高质量的人脸到肖像画的转换是难度很大的,上述的特点都要在考虑范围内。
为了解决上述挑战,本文提出了 APDrawingGAN,一种新颖的 Hierarchical GAN 架构,专门用于面部结构和 APDrawing 样式,用于将面部照片转换为高质量的 APDrawings。
为了有效地学习不同面部区域的不同绘图风格,GAN 架构涉及专门用于面部特征区域的几个局部网络,以及用于捕获整体特征的全局网络。为了进一步应对艺术家绘画中基于线条笔划的风格和不精确定位的元素,还提出了一种新的距离变换(DT)损失来学习 APDrawings 中的笔划线。
1. 提出了一种 Hierarchical GAN 架构,用于从面部照片中进行艺术人像合成,可以生成高质量和富有表现力的艺术肖像画。特别是,可以用细腻的白线学习复杂的发型;
2. 为了最好地模拟艺术家,模型将 GAN 的渲染输出分成多个层,每个层由分离的损失函数控制;
3. 从 10 个面部数据集中收集的 6,655 张正面照片预训练模型,并构建适合训练和测试的 APDrawing 数据集(包含 140 张专业艺术家的高分辨率面部照片和相应的肖像画)。
模型结构
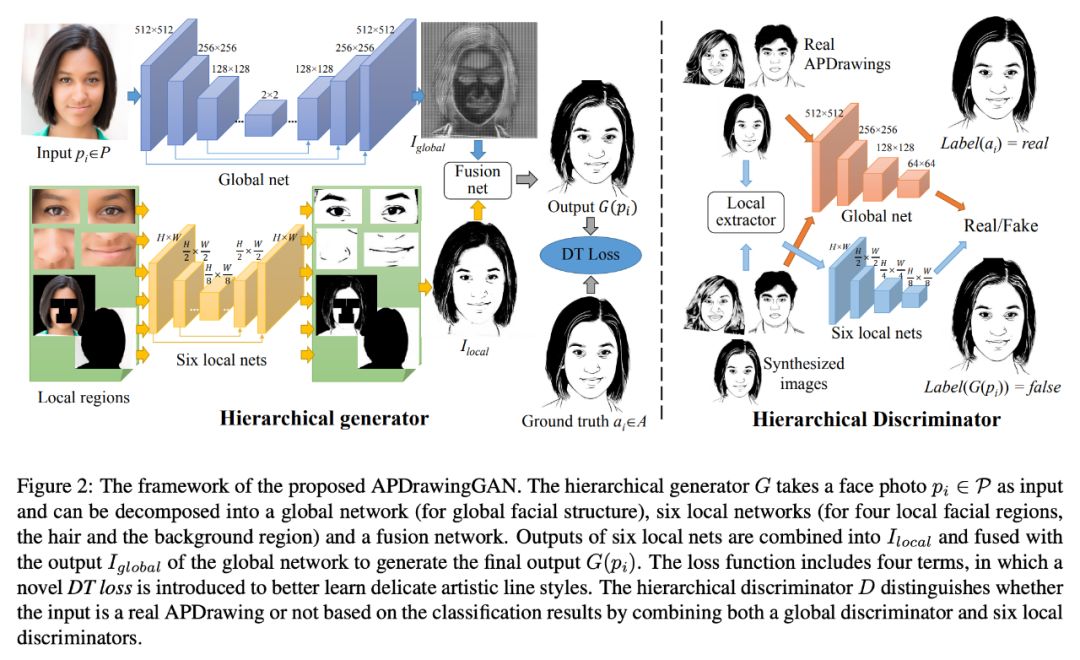
先从整体上看一下 APDrawingGAN 模型结构:
![]()
整体结构是比较直观理解的,整个网络是基于 GAN 建立的,左边为分层生成器,右边为分层判别器,输入的原始人脸图记为![]() 。
分层生成器的上部分为全局生成器它的输出为全局人脸肖像
。
分层生成器的上部分为全局生成器它的输出为全局人脸肖像![]() ,下部分为分别对应着左眼、右眼、鼻子、嘴巴、头发、背景的六个局部生成器,这六个生成器得到的肖像局部图结合在一起便得到了
,下部分为分别对应着左眼、右眼、鼻子、嘴巴、头发、背景的六个局部生成器,这六个生成器得到的肖像局部图结合在一起便得到了![]() ,
通过融合生成器便得到最终的输出结果
,
通过融合生成器便得到最终的输出结果![]() 。
对于判别器则整体上采用的是条件 GAN 的判别器设计,对于真实的肖像图给定的标签为 True,对于合成的肖像图给定的标签是 False,这个标签是人为构建的。同时也是采用全局判别器和六个局部判别器组成,最终确定真假以优化生成器。
。
对于判别器则整体上采用的是条件 GAN 的判别器设计,对于真实的肖像图给定的标签为 True,对于合成的肖像图给定的标签是 False,这个标签是人为构建的。同时也是采用全局判别器和六个局部判别器组成,最终确定真假以优化生成器。
这里说的全局生成器和局部生成器并不是我们在感受野中定义的全局和局部,这里的全局和局部就是全局得到的人脸肖像和局部得到的眼睛、鼻子、嘴巴和头发。对于全局生成器采用的是 U-Net 的设计思路,通过下采样结合特征复用的上采样最终得到全局的输出。
局部生成器的前提是要把人脸的各个部位提取出来,将人脸图取出左眼、右眼、鼻子、嘴巴出来,扣除掉这些部位后得到的就是头发部分,对人脸图取掩码得到背景图。将这六个部分分别进行小尺度下的 U-Net 的重构得到对应的局部肖像图,通过 partCombiner2_bg 网络将这六个部分组合组合成一副完整的人脸肖像图,partCombiner2_bg 主要通过在重叠区域使用最小池化来将所有局部生成器的输出混合到聚合图形。
其实从扣出局部的部位到再次将每一个部位整合在一起,这中间还是比较繁琐的,同时这块也是 APDrawingGAN 的主要创新之处,在源码中作者通过固定各个部位的尺度大小,然后通过对每一幅图像的各个部位进行标注(主要是嘴巴和中心位置,保存在 txt 中的 5 行 2 列的坐标),在训练阶段进行截取局部位置时调用。
融合生成器就是将全局生成器得到的全局图和局部生成器得到的局部整合图进行 channel 维度的 concat 后送入到 combine 网络再次经过一些卷积处理最终得到最后的输出![]() 。
。
全局判别器和局部判别器就和条件 GAN 的判别器类似,定义真实部分的 label 为真,合成部分的 label 为假,然后通过条件判别器进行优化,整个网络的架构就是堆叠的下采样。
损失函数
整个模型的损失函数由四部分组成,大家熟知的生成对抗损失、像素层面损失、距离变换损失以及局部像素损失。对于生成对抗损失,主要分为两部分一个是全局性的生成对抗损失和局部性六个部位的生成对抗损失;像素层面损失主要是采用 L1 损失:
![]()
其中![]() 就是真实肖像画的数据;局部像素损失就是对各个部位的合成和真实进行 L1 损失优化,比如对鼻子的局部损失:
就是真实肖像画的数据;局部像素损失就是对各个部位的合成和真实进行 L1 损失优化,比如对鼻子的局部损失:
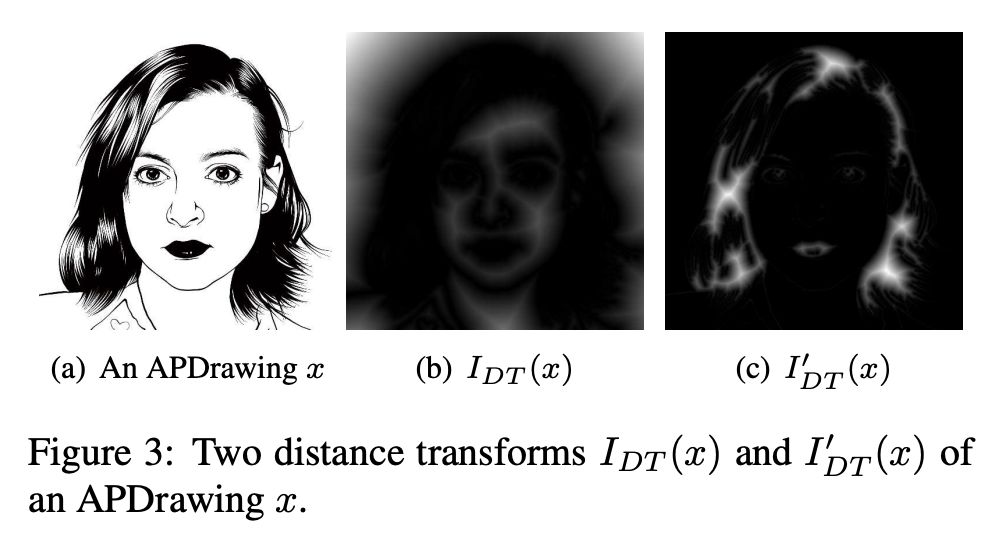
距离变换指的是对于一张图像中的每一个像素点的值用距离来代替,其实得到的就是一副类似于二值图的图像,![]() 用于表示肖像图的黑线分布,
用于表示肖像图的黑线分布,![]() 用于表示肖像图白线的分布,由肖像图计算黑线与白线可以用卷积层去检测到,从而确定确定对应的
用于表示肖像图白线的分布,由肖像图计算黑线与白线可以用卷积层去检测到,从而确定确定对应的![]() 和
和![]() 。我们可以用下图进一步理解距离变换的定义。
。我们可以用下图进一步理解距离变换的定义。
![]()
距离变换损失就是衡量真实肖像图与生成肖像图的![]() 和
和![]() 的差值:
的差值:
![]()
其中像素 (j,k) 在真实和生成肖像图下![]() 和
和![]() 的距离,得到的最终的损失表示为:
的距离,得到的最终的损失表示为:
![]()
这种对肖像图中的黑线和白线的距离控制是为了尽可能还原肖像图中的发型流动性和光泽度,让肖像图更加地逼真。
![]()
实验
由于由艺术家手绘的肖像图的成本过高,实验组是收集了 140 对面部照片和相应的肖像画的数据集(由专业人员手绘的肖像图),为了实现少量图像对下的训练,从 10 个面部数据集中收集了 6,655 张正面照片,对每张图片使用双色调 NPR 算法 [1] 生成肖像图纸,这个阶段得到的结果通常会产生没有明确下颚线的结果(由于这些位置的图像中的对比度低),再使用 OpenFace [2] 中的面部模型来检测颌骨上的标记,然后将下颌线添加到NPR结果中。
对于这种处理得到的数据,主要用于预训练,预训练阶段为前 10 个 epoch,由于 NPR 生成的绘图(与艺术家的绘图不同)与照片准确对齐,因此在预训练中不去优化距离变换损失。预训练结束后,将数据集换为由专业人员手绘的肖像图进一步训练得到最后的结果,这个过程解释可看下图。
![]()
文章在定性上做了消融性对比,包括有无局部生成器、距离变换损失、预训练和完整结果。
![]()
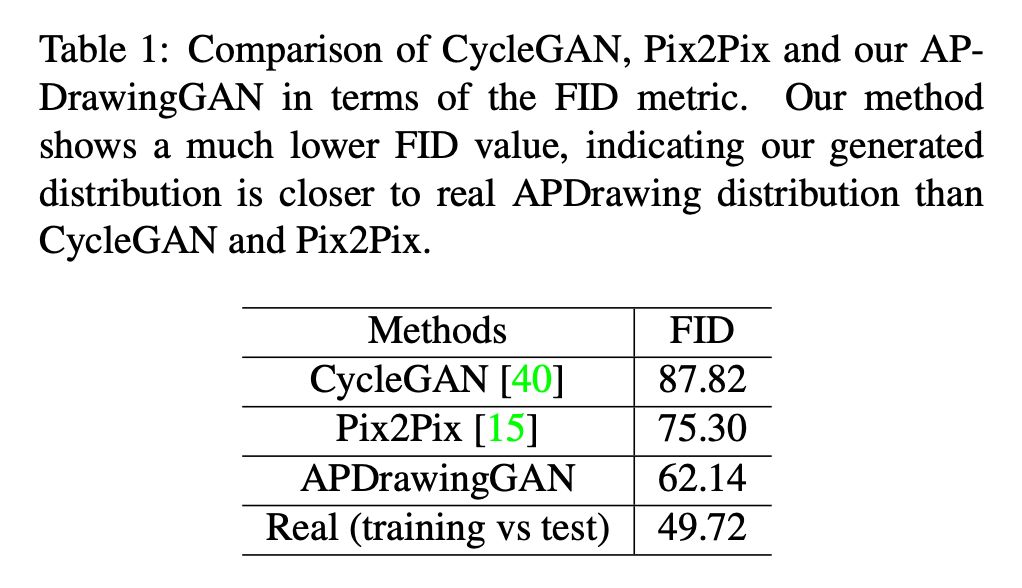
和已有的方法,APDrawingGAN 也与时下的模型进行了定性和定量上的对比。
![]()
![]()
总结
文章提出了 APDrawingGAN,一种用于将面部照片转换为 APDrawing 的分层 GAN 模型。实验致力于特定的人脸和 APDrawing 风格的转换,特别是旨在完成这种特定的转换工作。通过全局生成器和局部生成器对人脸进行肖像图重构,利用距离变换损失加强肖像图的逼真度,从实验结果上可以实现成功的艺术肖像风格转移,并且取得了一定的优势。
这也启发了我们在通用型的图像翻译工作下,具体的模型设计还需要根据具体的目的需求去设计,在特定的任务下实现合理而且高质量的结果。
参考文献
[1] Paul L. Rosin and Yu-Kun Lai. Towards artistic minimal rendering. In International Symposium on Non-Photorealistic Animation and Rendering, NPAR ’10, pages 119–127, 2010. 5, 6
[2] Brandon Amos, Bartosz Ludwiczuk, and Mahadev Satyanarayanan. OpenFace: A general-purpose face recognition library with mobile applications. Technical report, CMUCS-16-118, CMU School of Computer Science, 2016. 6