1300篇!CVPR 2019录取结果公布,7篇新鲜好文推荐
![]()
来源:新智元

来源:新智元
【导读】近日,CVPR 2019发布接收论文ID列表,共计1300篇论文被接收,接受率为25.2%。众多学术机构、高校及个人已然按耐不住激动的心,纷纷在社交平台上晒出成绩。
今年CVPR的接收论文ID公布了!你是否上榜了呢?
前几日,CVPR 2019 官方推特发布消息公布了本次大会接收论文ID:

接收论文列表链接如下:
http://cvpr2019.thecvf.com/files/cvpr_2019_final_accept_list.txt
https://docs.google.com/spreadsheets/d/1zhpogphsC8rGaexSHUANQeW3ezFV3XiJuO-wayQIIYI/htmlview?sle=true#gid=0
据统计,今年共计1300篇论文被CVPR 2019 接收,相比去年被接收论文数量增加了32.8%。今年的接收率为25.2%。
而此次论文提交数量是5165篇,相比CVPR 2018增加了56%。
Twitter网友Simon Kornblith自制了接收论文ID结果分布图:

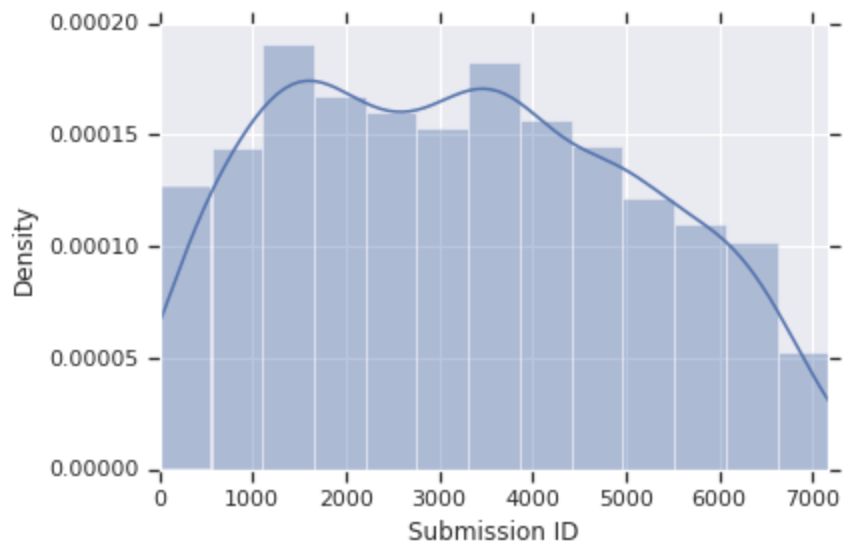
他认为,提交ID与接收论文数之间的关系为:中期>早期>后期。
此表一出,众人纷纷前去查阅ID,看看自己的论文是否登榜。
而后在Twitter、微博、朋友圈等社交平台上,众多网友开始晒出自己的成绩单:


可以看到众多学术机构、高校和个人,已然纷纷开始“炫”成绩。
相信在接下来的一段时间里,陆续会有更多人公布自己论文结果了。新智元也会对此结果进行跟进。
下面,我们重点推荐7篇CVPR 2019的新鲜热文,包括目标检测、图像分类、3D目标检测、3D重建、点云分割等主题,一睹为快!论文列表来自中科院自动化所博士生朱政的CV arXiv Daily。
[1] CVPR2019 检测新文
论文题目:Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression
作者:Hamid Rezatofighi, Nathan Tsoi, JunYoung Gwak, Amir Sadeghian, Ian Reid, Silvio Savarese
论文链接:https://arxiv.org/abs/1902.09630
摘 要
Intersection over Union (IoU)是目标检测基准中最常用的一个评估指标。然而,在优化用于回归边界框参数的常用距离损失和最大化这个度量值之间存在差距。对一个指标来说,最佳目标是指标本身。在轴对齐的2D边界框的情况下,可以证明IoU可以直接作为回归损失使用。然而,IoU具有平台,使得在不重叠边界框的情况下进行优化是不可行的。
在这篇论文中,作者通过引入一个generalized version同时作为新损失和新指标来解决IoU的缺陷。通过将这个generalized IoU (GIoU)作为一种损失采用到最新的目标检测框架中,在PASCAL VOC和MS COCO等流行目标检测基准得到了性能改进。
[2] CVPR2019 分类新文
论文题目:Learning a Deep ConvNet for Multi-label Classification with Partial Labels
作者:Thibaut Durand, Nazanin Mehrasa, Greg Mori
论文链接:https://arxiv.org/abs/1902.09720
摘 要
深度卷积网络(Deep ConvNets)在单标签图像分类(如ImageNet)中表现出色,但是有必要超出单标签分类任务,因为日常生活中的图像本质上是多标签的。多标签分类比单标签分类更困难,因为输入图像和输出标签空间都更复杂。此外,与单标签注释相比,大规模地收集干净的多标签注释更难。为了降低标注成本,我们建议训练带有部分标签的模型,即每个图像只知道部分标签。
我们首先对不同的标签策略进行实证比较,证明在多标签数据集上使用部分标签的潜力。然后,为了学习部分标签,我们提出一种新的分类损失,它利用了每个样本中已知标签的比例。我们的方法允许使用与使用所有注释时相同的训练设置。我们进一步探讨了几种预测缺失标签的策略。实验在3个大型多标签数据集上进行:MS COCO, NUS-WIDE和Open Image。
[3] CVPR2019 3D detection新文
论文题目:Stereo R-CNN based 3D Object Detection for Autonomous Driving
作者:Peiliang Li, Xiaozhi Chen, Shaojie Shen
论文链接:https://arxiv.org/abs/1902.09738
摘 要
本文提出一种充分利用立体图像中稀疏信息和密集信息、语义信息和几何信息的自动驾驶3D目标检测方法。我们的方法称为Stereo R-CNN,它将Faster R-CNN拓展到立体输入,以同时检测和关联左右图像中的对象。我们的方法不需要深度输入和3D位置监控,但优于所有现有的基于图像的全监控方法。在具有挑战性的KITTI数据集上的实验表明,我们的方法在3D检测和3D定位任务上的性能都比此前最先进的方法高出约30% AP。代码将公开发布。
[4] CVPR2019 3D Reconstruction新文
论文题目:Single-Image Piece-wise Planar 3D Reconstruction via Associative Embedding
作者:Zehao Yu, Jia Zheng, Dongze Lian, Zihan Zhou, Shenghua Gao
论文链接:https://arxiv.org/abs/1902.09777
代码链接:https://github.com/svip-lab/PlanarReconstruction
摘 要
单图像分段平面3D重建的目的是同时分割平面实例和从图像恢复3D平面参数。最近的方法都是利用卷积神经网络(CNN),并取得了很好的效果。然而,这些方法仅限于检测具有一定学习顺序的固定数量的平面。
为了解决这个问题,我们提出了一种新的基于关联嵌入的两阶段方法,启发自最近在实例分割方面的成功。在第一阶段,我们训练CNN将每个像素映射到一个嵌入空间,其中来自相同平面实例的像素具有类似的嵌入。然后,利用一种有效的平均位移聚类算法对平面区域内的嵌入向量进行分组,得到平面实例。在第二阶段,我们通过考虑像素级和实例级的一致性来估计每个平面实例的参数。利用该方法,我们能够检测任意数量的平面。在公共数据集上的大量实验验证了该方法的有效性。此外,我们的方法在测试时运行速度达到30fps,因此可以促进许多实时应用,如可视化SLAM和人机交互。
[5] CVPR2019 点云分割新文
论文题目:Associatively Segmenting Instances and Semantics in Point Clouds
作者:Xinlong Wang, Shu Liu, Xiaoyong Shen, Chunhua Shen, Jiaya Jia
论文链接:https://arxiv.org/abs/1902.09852
代码链接:https://github.com/WXinlong/ASIS
摘 要
3D点云准确而直观地描述了真实场景。到目前为止,如何在这样一个信息丰富的3D场景中分割各种元素,还很少得到讨论。
在本文中,我们首先介绍了一个简单而灵活的框架,用于同时分割点云中的实例和语义。然后,我们提出了两种方法,使两项任务互相利用,实现双赢。具体来说,我们通过学习语义感知的point-level实例嵌入,使实例分割受益于语义分割。同时,将属于同一实例的点的语义特征融合在一起,从而对每个点更准确地进行语义预测。我们的方法在3D实例分割方面大大优于目前最先进的方法,在3D语义分割方面也有很大的改进。
[6] CVPR2019 点云分割新文
论文题目:RepNet: Weakly Supervised Training of an Adversarial Reprojection Network for 3D Human Pose Estimation
作者:Bastian Wandt, Bodo Rosenhahn
论文链接:https://arxiv.org/abs/1902.09868
摘 要
本文研究了基于单幅图像的3D人体姿态估计问题。长期以来,人类骨骼是通过满足reprojection error进行参数化和拟合观察,但现在研究人员可以直接利用神经网络从观测结果中推断出3D姿态。
然而,这些方法大多忽略了必须满足重投影约束(reprojection constraint)的事实,并且对过拟合很敏感。我们通过忽略2D到3D的对应来解决过拟合问题。这有效地避免了对训练数据的简单记忆,并允许弱监督训练。
本文提出的重投影网络(RepNet)一部分使用对抗性训练方法来学习从2D姿态分布到3D姿态分布的映射。网络的另一部分对摄像机进行估计。这允许定义一个网络层,该网络层将估计的3D姿态重新投影回2D,从而产生一个重投影损失函数。我们的实验表明,RepNet可以很好地对未知数据进行泛化,当应用于未知数据时,它的性能优于此前最先进的方法。此外,我们的实现在台式PC上就能实时运行。
[7] CVPR2019 3D Face新文
论文题目:Disentangled Representation Learning for 3D Face Shape
作者:Zi-Hang Jiang, Qianyi Wu, Keyu Chen, Juyong Zhang
论文链接:https://arxiv.org/abs/1902.09887
摘 要
本文提出了一种解析3D人脸形状表示的新策略。具体来说,将给定的3D人脸形状分解为特征部分(identity part)和表情部分(expression part),并以非线性方式对其进行编码和解码。
为了解决这个问题,我们提出一个3D人脸网格的属性分解框架。人脸形状用基于顶点的变形表示,而不是用欧几里德坐标表示。实验结果表明,该方法在特征部分和表情部分的分解上都优于现有方法。与现有方法相比,该方法可以获得更自然的表情转换结果。
最后,亲爱的读者们,你们的论文是否也被CVPR 2019接收了呢?留言区快快晒出你们的成绩吧!
新智元帮你上墙!
CVPR 2019 接收论文ID列表地址:
http://cvpr2019.thecvf.com/files/cvpr_2019_final_accept_list.txt
https://docs.google.com/spreadsheets/d/1zhpogphsC8rGaexSHUANQeW3ezFV3XiJuO-wayQIIYI/htmlview?sle=true#gid=0
☞ OpenPV平台发布在线的ParallelEye视觉任务挑战赛
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【学界】Ian Goodfellow等人提出对抗重编程,让神经网络执行其他任务
☞【学界】六种GAN评估指标的综合评估实验,迈向定量评估GAN的重要一步
☞【资源】T2T:利用StackGAN和ProGAN从文本生成人脸
☞【学界】 CVPR 2018最佳论文作者亲笔解读:研究视觉任务关联性的Taskonomy
☞【业界】英特尔OpenVINO™工具包为创新智能视觉提供更多可能
☞【学界】ECCV 2018: 对抗深度学习: 鱼 (模型准确性) 与熊掌 (模型鲁棒性) 能否兼得



