编辑:好困 小咸鱼
【新智元导读】今年,《鱿鱼游戏》大火。随着Netflix等流媒体的兴起,非英语作品也越来越多。然而,字幕和配音行业的人才却非常紧缺,尤其是小语种直译方面。为此,不管是Netflix,还是小型的本地化供应商,都在探索能不能用AI配音技术代替人工字幕。
一个时代,终究还是落幕了。
11月22日,上海第三中院对「人人影视字幕组」侵权案进行公开审理,并当庭作出一审判决。
以侵犯著作权罪判处被告人梁永平有期徒刑三年六个月,并处罚金人民币一百五十万元。
违法所得予以追缴,扣押在案的供犯罪所用的本人财物等予以没收。
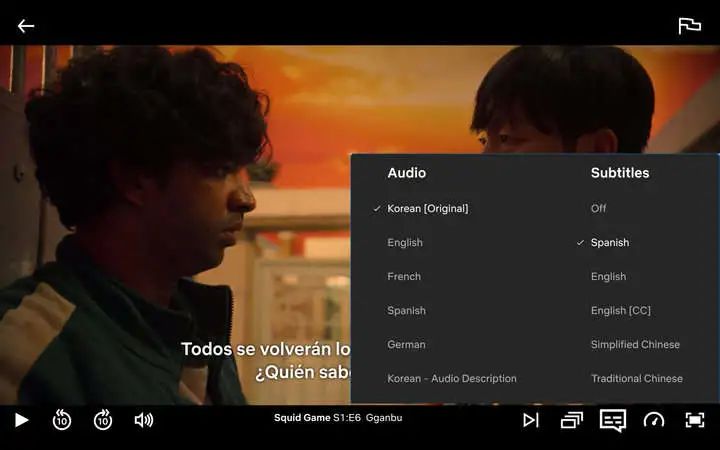
前段时间,韩国反乌托邦题材剧集《鱿鱼游戏》(Squid Game)可谓是相当火爆,上线1个月播放量就达到了1.42亿,霸榜90个国家和地区。
Netflix也为其提供了多达31种语言的字幕和13种语言的配音。
然而韩裔美籍喜剧演员Youngmi Mayer却发现《鱿鱼游戏》的官方字幕过于离谱,完全就是词不达意。
就比如说,当女演员用韩语表示「看什么看」,Netflix 的英文字幕翻译为「走开」。
随着Netflix等流媒体的兴起,像是《鱿鱼游戏》这类的非英语作品也越来越多。
然而,字幕和配音行业的人才却非常紧缺,尤其是小语种直译方面。
还是以《鱿鱼游戏》为例,如果想将其推向西班牙语市场,通常会先输出英文版的字幕,然而再在这个基础上进行法语翻译。
也就是说,部分语种字幕的质量完全取决于英文的翻译如何,而这个转化过程难免会丢失很多信息细节。
据统计,《鱿鱼游戏》的配音版比字幕版的观看人数还要多。
为此,不管是Netflix这样的流媒体巨头,还是一些小型的本地化服务供应商,都在探索能不能用AI技术代替人工翻译。
这就得从Deepfake Voice是什么开始说起了。
复制或克隆一个人的声音,常用到的一项技术叫Deepfake Voice,也称为语音克隆或合成语音,其目的是使用AI生成一个人的语音。
目前,这项技术已经发展到可以在音调和相似度上非常精确地复制人声的地步。
声音克隆是一个过程,在这个过程中,人们使用计算机生成真实个体的语音,使用人工智能(AI)创建一个特定的、独特的声音的克隆。
要克隆某人的声音,必须有训练数据输给人工智能模型。这些数据通常记录了目标人说话的例子。
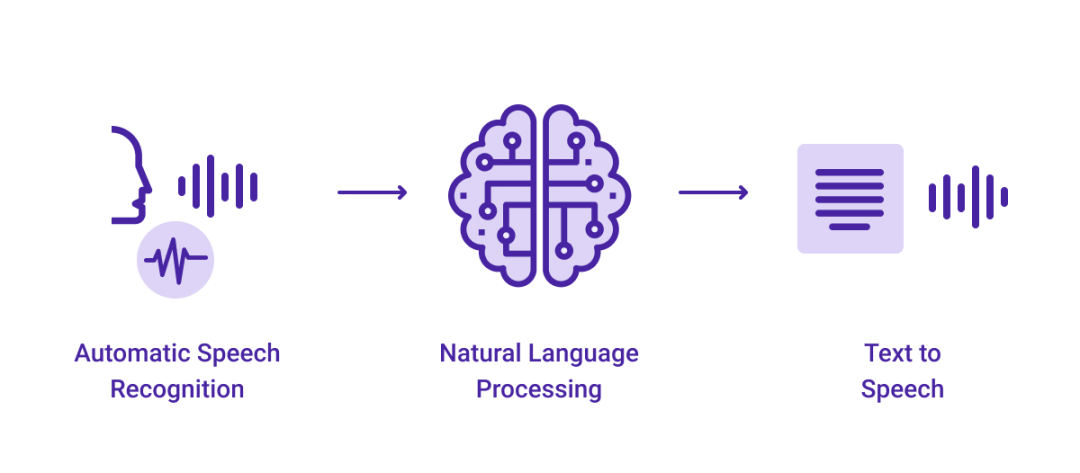
人工智能可以使用这些数据来呈现一个真实的声音,比如可以用文字键入的任何东西生成一段语音,这个过程称为文本到语音。
在以往的文本到语音(TTS)系统中,训练数据是关键组成部分,它控制了语音输出的产生。换句话说,你听到的声音就应该是数据集中给出的声音。
不过现在,随着最新AI技术的引入,使用一些目标声音的特征,比如语音波形,也可以进行更深入的分析和提取。
合成声音是一个术语,也就是通常所说的Deepfake Voice,合成声音也经常与声音克隆互换使用。
但简单来说,合成语音就是计算机生成的语音,也叫语音合成,一般是通过人工智能(AI)和深度学习来实现的。
合成声音的方式主要有两种:文本到语音转换(TTS)和语音到语音(STS)。
文本到语音转换(TTS)在上文中已经介绍过,目前,TTS软件已被用于帮助视障人士阅读数字文本,还被搭载在语音助手等其他应用上。
而语音到语音(STS)不是使用文本,而是使用一段语音修改其声音的特征来创建另一段听起来很真实的合成语音。
过去的语音合成并不能生成以假乱真的声音。但是随着技术的发展,这种情况已经改变。
传统的语音合成通常使用两种基本技术。这两种技术是拼接合成和共振峰合成。
拼接合成采用的方法是将录制声音的短样本拼接在一起,形成一个称为单元的链。这些单元然后被用来生成用户定义的声音模式。
而共振峰合成这种技术最常用来复制人们用元音发出的声音。
这些方法的缺点是,它们时不时会生成一些人们无法发出的声音。但是深度学习和人工智能的出现将TTS技术带到了新的高度。
AI文本到语音转换通常被称为神经文本到语音转换,它利用神经网络和机器学习技术从文本中合成语音输出。
首先,语音引擎接受音频输入,并识别人类声音产生的声波。
接着,这些信息被翻译成语言数据,这被称为自动语音识别(ASR)。在获得这些数据后,语音引擎必须对数据进行分析,以理解它所收集的单词的含义,这被称为自然语言处理(NLP)。
寻找训练数据是合成声音的第一个基本项目。没有清晰的声音录音,就没有办法成功地训练人工智能模型来捕捉一个人说话的所有复杂细节。
录制过程可能需要几个小时到几个小时,语音解决方案团队将提供一个全面的短语列表,以捕捉一个人声音的所有特征。
通常,这个列表不会超过4000个短语,但目标确实是围绕某人独特的声音捕获尽可能多的数据——捕获的数据越多,声音克隆就越准确。
使用神经网络获取一组有序的音素,然后将它们转换成一组频谱图。频谱图是信号频带频谱的可视化呈现。
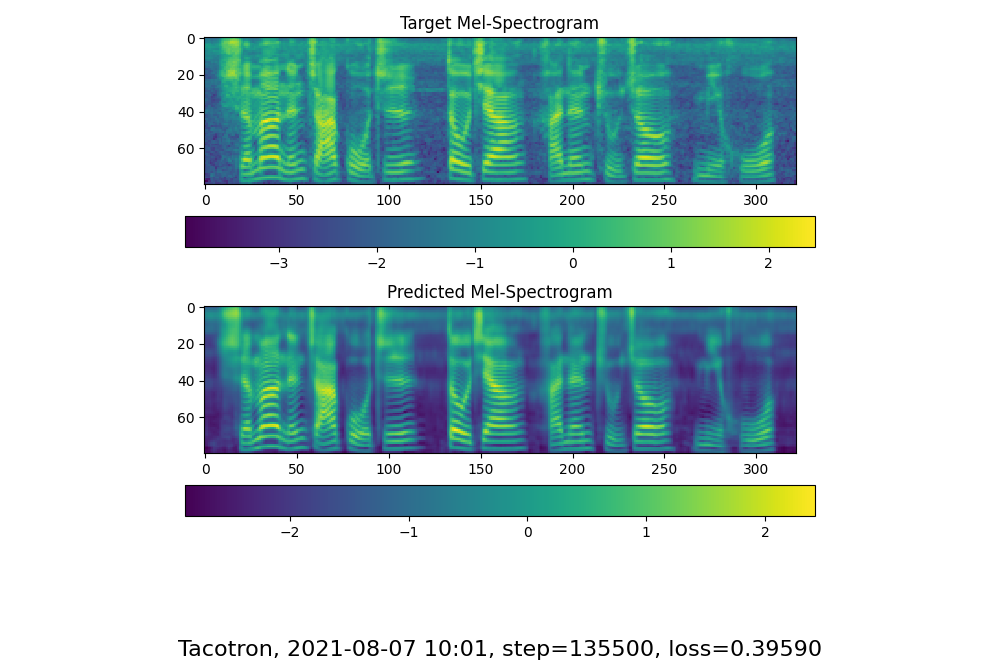
神经网络选择合适的频谱图,其频带能够更准确地刻画人脑在理解语音时使用的声学特征。然后,神经声码器将这些频谱图转换成语音波形,就可以发出自然且逼真的声音。
今年10月,GitHub上的一个项目狂揽13k星。
只需5秒,就能用AI技术来模拟声音来生成任意语音内容,并且还支持中文。
https://github.com/babysor/MockingBird/blob/main/README-CN.md
支持普通话并使用多种中文数据集进行测试:aidatatang_200zh, magicdata, aishell3, biaobei,MozillaCommonVoice等
适用于pytorch,已在1.9.0版本中测试,GPU Tesla T4和GTX 2060
可在Windows操作系统和Linux操作系统中运行(苹果系统M1版也有社区成功运行案例)
仅需下载或新训练合成器(synthesizer就有良好效果,复用预训练的编码器/声码器,或实时的HiFi-GAN作为vocoder)
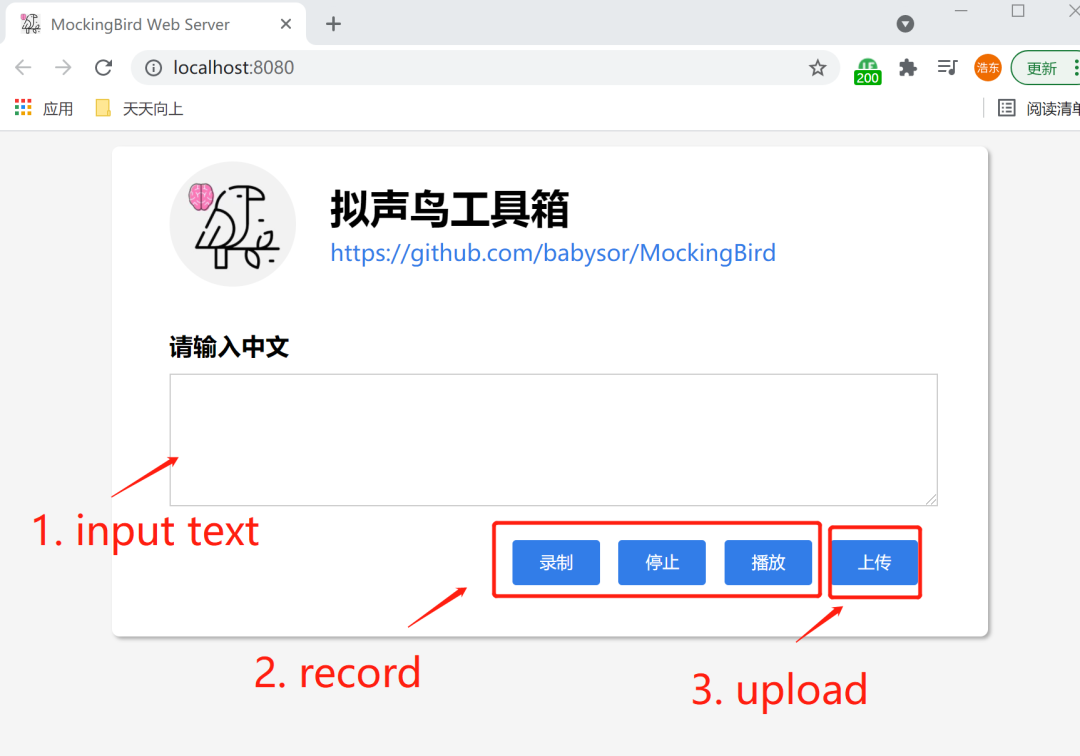
提供一个Webserver可查看训练结果,供远程调用
![]()
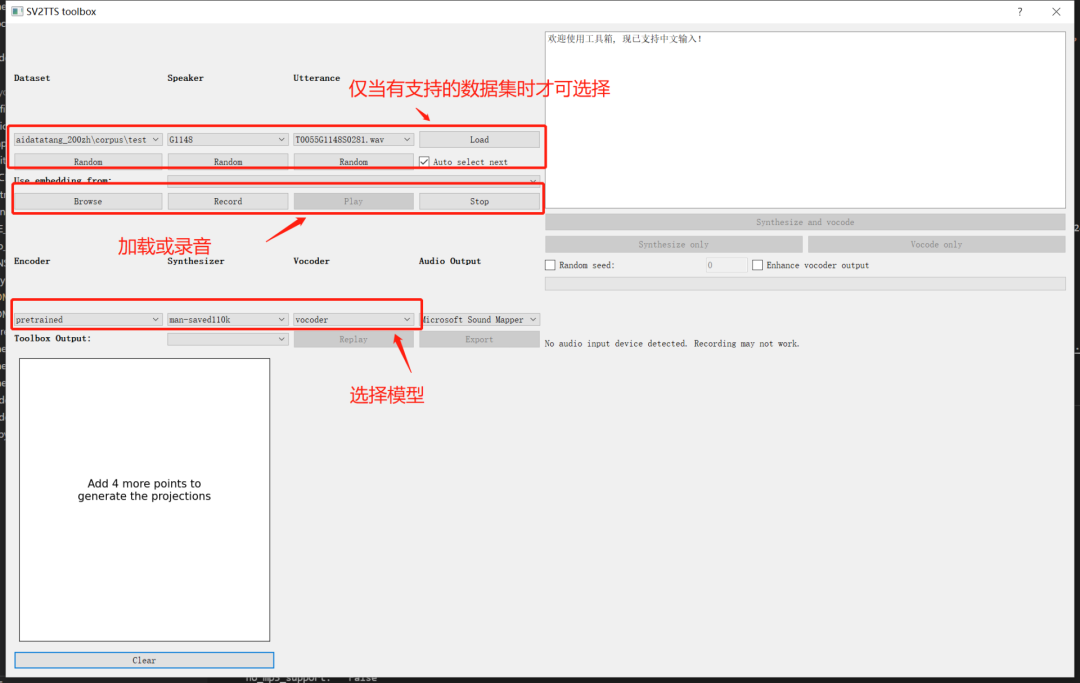
Mocking Bird除了在知乎上有专栏分享保姆级教程和训练技巧之外,其使用也非常简单。
首先安装好PyTorch、ffmpeg、webrtcvad-wheels和requirements.txt 中要求的剩余包。
第二步是准备预训练模型,可以使用作者提供的或者是其他人训练好的模型。
重要的数据处理操作是进行音频和梅尔频谱图预处理:python pre.py <datasets_root> 可以传入参数 --dataset {dataset} 支持 aidatatang_200zh, magicdata, aishell3
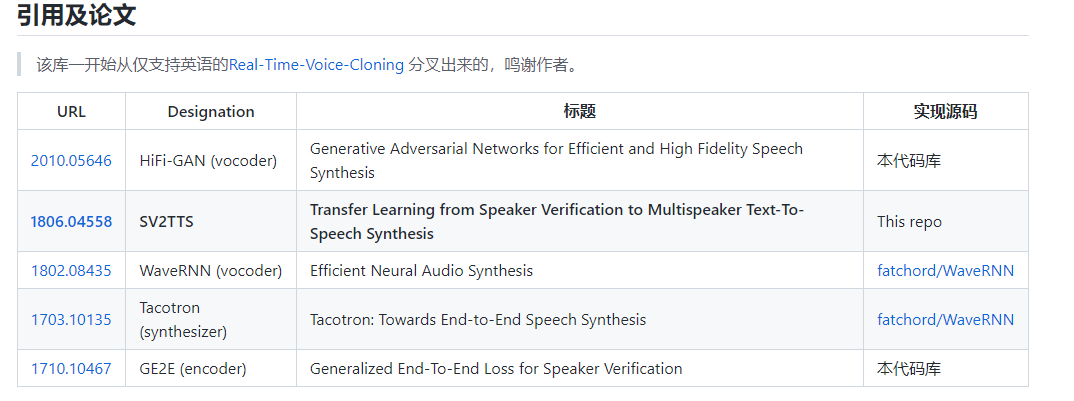
作者还贴心的附上了所有可以学习的论文及原始代码仓库。
这个仓库的名字MockingBird 是仿声鸟、反舌鸟,以善于模仿其他鸟类及昆虫、两栖动物的叫声而闻名,也是一种经常出现在西方文学或影视作品之中的鸟类,在生物学上是嘲鸫的俗称。
著名的书的名字《杀死一只知更鸟》的英文就是To Kill a Mocking Bird,实际上属于翻译的错误,知更鸟的英文是Robin。
Deepfake Voice带来的语音欺诈是一个很大的问题。
2019年,犯罪分子克隆了一家总部位于英国的能源公司CEO的声音,骗走了24万美元,原因就是这个假CEO在口音和语气上听起来都是十分真实的。这起事件是欧洲已知的第一起直接使用人工智能的网络犯罪。
另一起事件发生在2020年。一位在阿拉伯联合酋长国工作的银行经理接了一个电话,他当时以为他在和一家公司的董事说话,结果掉进了一个彻头彻尾的语音骗局,错误地批准了3500万美元的转账。
随着技术的发展,Deepfake Voice诈骗变得越来越复杂,许多人可能在社交媒体上就已经遇到过一些Deepfake Voice伪造的声音。
那么,如何防范Deepfake Voice欺诈呢?
第一种方法是创建一个检测器,分析声音以确定它是否是使用deepfake技术制作的。不幸的是,因为Deepfake Voice技术会不断发展,检测器无法永远保持正确。
第二种方法则相对更加现实,主要是实现一个听众听不到、人们也无法编辑的音频水印。音频水印本质上是声音被创造、编辑和使用的记录。这样一来,人们就更容易知道一段声音是否是合成的。
参考资料:
https://www.axios.com/artificial-intelligence-voice-dubbing-synthetic-14bfb3c6-99db-4406-920d-91b37d00a99a.html
https://www.businesswire.com/news/home/20210514005132/en/Veritone-Launches-MARVEL.ai-a-Complete-End-to-End-Voice-as-a-Service-Solution-to-Create-and-Monetize-Hyper-Realistic-Synthetic-Voice-Content-at-Commercial-Scale
https://www.veritone.com/blog/combining-conversational-ai-and-synthetic-media/
https://www.veritone.com/blog/everything-you-need-to-know-about-deepfake-voice/
https://www.veritone.com/blog/how-ai-companies-are-tackling-deepfake-voice-fraud/
https://www.veritone.com/blog/how-to-create-a-synthetic-voice/
特别鸣谢ifan
https://www.ifanr.com/1454818
![]()