Circle Loss之一:Unified Loss是如何统一的?
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

CVPR2020,来自旷视孙奕帆,瑞斯派克特

https://arxiv.org/abs/2002.10857
摘要:
研究领域是深度特征学习(deep feature learning),领域内研究目的是最小化类间相似度(


intro简单:
提出关于深度特征学习的两条路子:类别标签 以及 样本对应关系标签。但殊途同归都会归结到同一个优化目标的变种: 
对于
和
相同的惩罚力度,举例来说,当
已经接近0但
还很小的时候,虽然直觉上需要对
更多关注,但依然会给
和
相同尺度的关注。
优化
的目标往往会得到一个分类边界
,而该分类面会带来模糊性(模棱两个),举例来说,两个样本获得的<
>分别是<0.7, 0.4> <0.5, 0.2>,他们都有
,但是前者的
和后者的
仅有0.1的差距。这种模糊性会对特征空间的可分离性造成较大影响。
 ,而该分类面会带来模糊性(模棱两个),举例来说,两个样本获得的<
,而该分类面会带来模糊性(模棱两个),举例来说,两个样本获得的< >分别是<0.7, 0.4> <0.5, 0.2>,他们都有
>分别是<0.7, 0.4> <0.5, 0.2>,他们都有  ,但是前者的
,但是前者的 尝试解决上面问题1,比较好的思路是分别对 








相比与之前的研究,作者列举了三个circle loss和之前损失函数不同的点:
一种统一的深度特征学习损失(统一class label 和 pairwise label);
灵活的优化方向(相比sn-sp对于两者相同的惩罚);
确定的收敛状态,对于特征的可区分性有裨益。
本文先讨论文章中提出的Unified Loss(统一的深度特征学习损失),介绍上面提到的传统两条路子里的经典损失函数,并推导Unified Loss是如何将他们统一的。关于Circle Loss的主体将在接下来的文章里介绍。
两条路子
文中提到了进行深度特征学习的两条经典路子:给定类别标签 vs 给定成对标签,下面首先对这两条路子里比较经典的损失函数进行介绍。
给定类别标签的损失
Softmax
初始的softmax损失函数表达为: 





A-Softmax
首先对上面的式子进行了约束,使 


举二分类的例子,可视为在圆上的两个半圆,这种情况下分类边界并未直接拉开,直接比较 






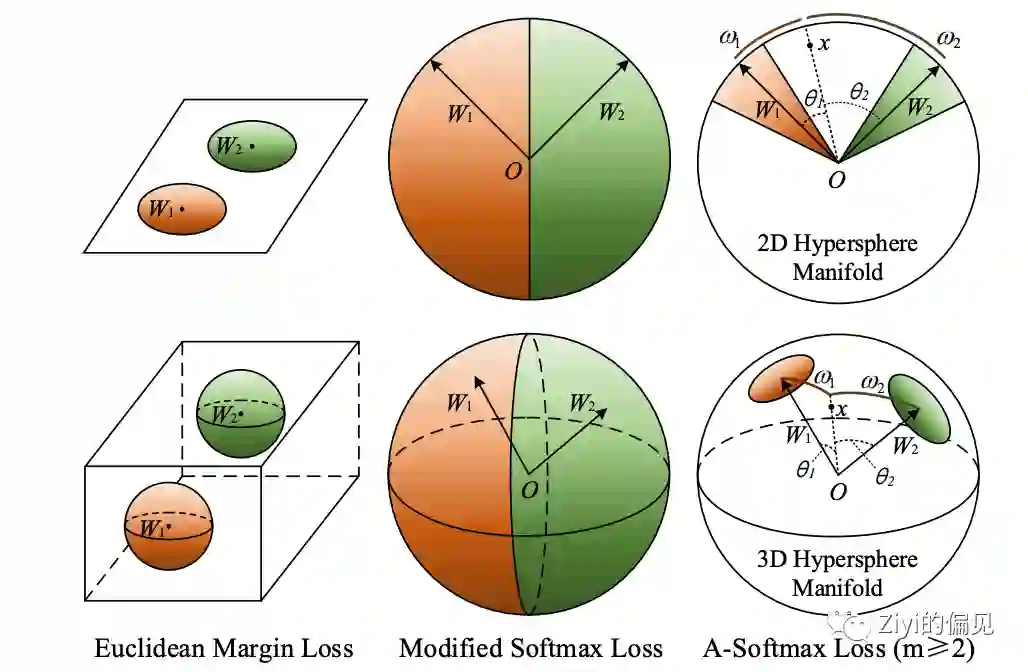
拓展进多分类并对上面的 

其中有约束 




m是一个直接控制分类边界距离的量,当其取1时A-Softmax就回归到正常的Softmax,而m越大则对于分类边界距离的要求越高。
AM-Softmax
相比A-Softmax里只对W进行归一化处理,这里更进一步,将得到的特征f也进行归一化处理,即 




这里只有一个超参 

关于A-Softmax和AM-Softmax之间的区别,这里说一下自己的理解,大致上有两点:
优化目标上,A-Softmax依然是关于
进行优化,包括对分类边界的约束也是加在
上,利用余弦函数在一定区间上的单调递减使不同类之间的分类边界有分隔;而AM-Softmax则是直接对余弦函数进行优化,并直接把边界放在了余弦函数上。
对于分类边界的控制参数m,A-Softmax通过调大m来使分类边界之间的距离(通过控制
中的前一项)变大,但并无法直接控制
使分类边界更宽;AM-Softmax调大m则非常直观,对应了调大分类边界之间的角度(
)。
 )。
)。给定成对标签的损失
Contrastive Loss
对比损失,更像是在给定成对标签情况下对softmax的直接修改,其损失函数如下。

其中 

Triplet Loss
挖坟才知道triplet loss这文章已经是15年的文章,与上面的对比损失一样,均选择数个与当前样本同类和异类的样本进行特征抽取,其定义如下。

其中 

统一的损失函数
这里给出作者提出的一种统一化的损失函数(Unified Loss),定义如下

其中,
1. 针对给定类别标签的情况
首先对特征进行归一化处理,并使用余弦函数作为上述相似性度量,那么unified loss就转化为

这时只取一个正样本对,即K=1,那么损失函数再次转变为下面的形式,可以直接得到AM-Softmax:

再继续转化下去,取 
2. 针对给定成对标签的情况
需引入两点:
Softplus函数是对Relu的平滑近似:
LogSumExp是对max函数的平滑近似:


在这两点的基础上,对Unified Loss进行下面变换

这样就实现了从 Unified Loss到Triplet Loss的转化(并且是hard-mining)。
最后提一嘴,这文章一开始写在知乎专栏上(名字是一样的),微信公众号对公式的友好度并不很高,可以顺道移步帮点波赞

https://zhuanlan.zhihu.com/p/138356112
论文下载
在CVer公众号后台回复:0508,即可下载本论文
重磅!CVer-论文写作与投稿 交流群已成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满1400+人,旨在交流顶会(CVPR/ICCV/ECCV/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI/TIP等)、SCI、EI等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
请给CVer一个在看!
