一份YOLOX改进的实验报告:如何设计性能优异的单阶段轻量级目标检测器?

极市导读
如何设计在 mAP 和延迟方面表现良好的单级轻量级检测器?本文研究了新型的单阶段轻量检测器和各种操作的准确性和延迟。此基础上分别提出了GPU和CPU的最佳操作和架构。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

论文链接:https://arxiv.org/abs/2210.17151
这项工作是为了设计在mAP和延迟方面表现良好的单阶段轻量级检测器。对于分别以GPU和CPU为目标的基线模型,应用各种操作来代替基线模型主干网络中的主要操作。除了主干网络和操作的实验之外,还研究了几种特征金字塔网络(FPN)架构。在作为目标检测基准数据集的MS COCO数据集上,从参数数量、Gflop、GPU延迟、CPU延迟和mAP等方面分析了基准和建议的检测器。考虑到准确性和延迟之间的权衡,这项工作提出了类似或更好的网络架构。例如,提出的GPU目标骨干网络的性能优于YOLOX tiny,后者在NVIDIA GeForce RTX 2080 Ti GPU上以1.43倍的速度和0.5 mAP的精度被选为基准。
1、介绍
目标检测是对场景中的目标进行定位和分类的各种视觉任务之一。近年来,目标检测被应用于许多领域,如无人商店和基于人脸识别的安全系统。早期关于目标检测的研究基于两阶段检测器,它们显示出高性能但低硬件效率。如今,目标检测在现实生活中渗透得越多,对轻量化检测器的需求就越高。例如,在监视系统领域可能需要实时目标检测,或者边缘设备中可能存在诸如电池限制和计算能力等限制。然而,检测器的效率不仅受到网络中的操作的影响,还受到检测器在其上执行的硬件架构的影响。例如,MobileNetv2中提出的倒置残差瓶颈设计旨在提高效率,同时几乎不牺牲精度。同时,谷歌的TPU是为执行DNN而优化的最出色的硬件之一。不幸的是,倒置残差瓶颈瓶颈在TPU上表现不佳,因为其架构优势不适合开发TPU。因此,有必要在综合考虑操作特性和硬件架构特性的同时设计网络。
在这项工作中检查了新型的单阶段轻量检测器和各种现代操作的准确性和延迟。在此基础上分别提出了GPU和CPU的最佳操作和架构。在GPU实验中,建议的目标检测器基于YOLOX,它在前面采用融合的倒置残差瓶颈,在后面采用倒置的残差瓶颈。它在速度上优于YOLOX微型1.43倍,在精度上优于0.5mAP。在CPU实验中,尽管YOLOX tiny在mAP方面是最好的,但建议的基于PP PicoDet的实验仅显示了74%的参数数量和1.12倍的速度,同时牺牲了1.3 mAP的精度。
2、Lightweight detector design
2.1、Micro architectures for backbone network
在GPU实验中,CSPDarknet中的CSP层被几个瓶颈架构所取代,例如MBConv、融合倒置残差瓶颈、RegNet瓶颈和沙漏瓶颈,以验证CSP层是否是YOLOX骨干网络中的最佳架构。EfficientNetv2提出,在网络前端使用融合的倒置残差瓶颈,在其余部分使用倒置残差瓶颈对准确性和效率都有好处。在本文中,讨论了仅包含倒置残差瓶颈、仅融合倒置残差瓶颈并且同时使用这两种操作的每个网络。在单个网络中使用倒置残差瓶颈和融合倒置残差瓶颈的策略称为混合倒置残差瓶颈。
在CPU实验中,使用PP-PicoDet检查深度可分离卷积运算和深度可分离卷积运算。为了与YOLOX基线进行公平比较,每个区块的通道设置与YOLOX相同。此外,PP-PicoDet中的FPN架构和检测头被YOLOX取代。
2.2、Feature pyramid network
YOLOX的PAFPN的主要操作分别是CSP层和LCPAN的深度可分离卷积。此外,这两个FPN之间的主要区别在于,在FPN操作之前,输入特征的通道是否均衡。在PAFPN中,输入特征的通道不均衡。相反,FPN输出的通道在被馈送到检测头之前被均衡。它在精度方面带来了更好的性能,但对延迟不利,因为FPN中的信道很大。相反,在LCPAN中,输入特征的信道在FPN之前被均衡。然后,输出特征的通道相同,而FPN中的通道减少。SepFPN基于YOLOX的PAFPN。也就是说,SepFPN的主要操作是CSP层,并且输入特征的通道不均衡。在这项工作中,提出了一种改进的PAFPN架构,该架构将FPN中的拼接操作替换为和。通过这样做,可以减少FPN中的通道,同时期望保留特征图中的丰富语义。该技术应用于YOLOX的PAFPN和PP-PicoDet的LCPAN,并进行了测试。
3、实验
3.1、Experimental settings
为了公平比较,在两个基线中都使用了YOLOX的检测头。也就是说,这项工作的目标是几个操作、主干和FPN架构。在GPU实验中,除沙漏瓶颈之外的瓶颈架构的扩展比被设置为1,沙漏瓶颈的扩展比设置为0.5。与网络设计相关的超参数(例如,块的数量、每个块的通道等)被设置为与YOLOX tiny相同。在训练网络时,除网络架构之外的任何其他超参数都遵循YOLOX的默认设置。在GPU实验中,NVIDIA GeForce RTX 2080 Ti用于测量GPU延迟。在CPU实验中,Intel(R)Core(TM)i9-9900K CPU@3.60GHz用于测量CPU延迟。在测量延迟时,将小批量大小和线程数设置为1。
3.2、Baseline latency breakdown
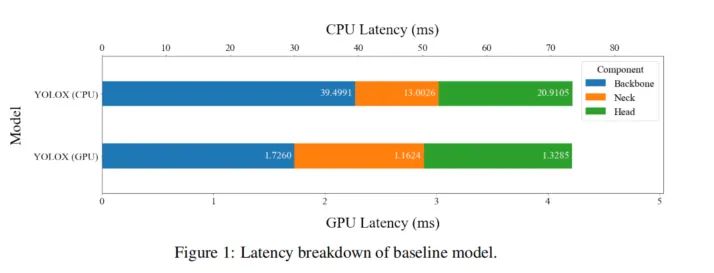
图1显示了基线模型的GPU和CPU延迟。主干网络在GPU上占总延迟的40%,在CPU上占53%。因此,减少主干延迟以减轻检测器的重量至关重要。FPN也是这项工作中需要改进的目标,占GPU总延迟的27%,CPU总延迟的18%。与FPN相比,检测头占用更多空间。然而,因为它与探测器的损失函数高度相关,所以在所有实验中都固定了检测头,以便进行公平的比较。
3.3、GPU-target detector
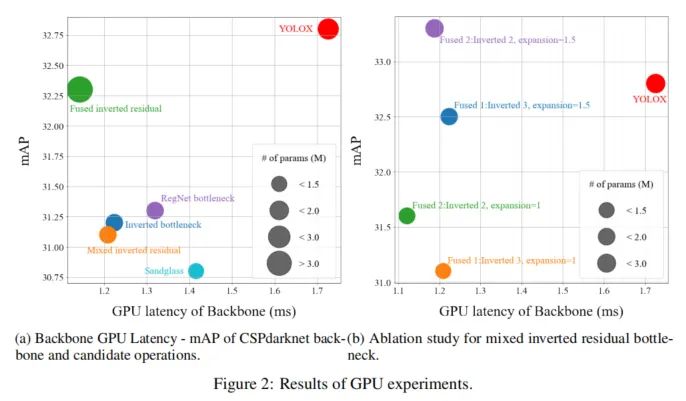
图2显示了主干网络和mAP的GPU延迟,具体取决于主干网络的主要操作。如图2a所示,就mAP而言,YOLOX tiny是最好的,但其GPU延迟是最差的。由融合的倒置残差瓶颈组成的主干网络具有最大的参数数目。然而,它的GPU延迟是所有设置中最快的。融合倒置残差瓶颈是唯一使用3×3卷积运算而不是3×3深度卷积运算的瓶颈。3×3卷积运算是最基本的卷积运算,在GPU上进行了高度优化。这就是为什么采用融合倒置残差瓶颈作为主干的主要操作的检测器在GPU上是最快的,尽管参数的数量是最大的。
这项工作的重点是Efficientnetv2中提出的策略;在网络前端使用融合的倒置残差瓶颈,其余部分使用倒置残差瓶颈。在图2a中,混合倒置残差瓶颈很明显,因为它速度快、重量轻,并且在设计方面有很多多样性。混合倒置残差瓶颈可以利用并行计算,通过使用融合倒置残差瓶颈获得更好的mAP,同时通过使用倒置残差瓶颈来追求轻量化。
此外,它具有很大的潜力,因为融合倒置残差瓶颈操作的数量是一项重要的设计策略。CSPDarknet是YOLOX的主干网络,有4个区块。因此,研究了使用1或2个融合的倒置残差瓶颈的网络。此外,由于混合倒置残差瓶颈中的参数数量小于YOLOX基线的参数数量,因此还研究了将扩展比设置为1.5的网络。
图2b显示了消融研究的结果。在等待时间和mAP方面,使用2个融合的倒置残差瓶颈和2个倒置残差瓶颈优于1个融合的倒置残差瓶颈和3个倒置残差瓶颈。
此外,使用更大扩张比率的策略仍比YOLOX基线更快。因此,图2b中的紫色点被选为GPU实验中的最佳检测器。
3.4、CPU-target detector
在本节中,作为YOLOX骨干网络的CSPDarknet被PP-PicoDet中的PP-LCNet取代。此外,深度可分离卷积运算被应用于PP-LCNet,作为深度可分离卷积的替代,这是PP-LCNet的主要操作。PP-LCNet的通道设置与CSPDarknet的通道相同,以便公平比较。然而,由于PP-LCNet比CSPDarknet小得多,因此也会检查使用两倍于默认网络的检测器。请注意,这些检测器的FPN架构与其他检测器不同,以便使用相同的检测头进行公平比较。
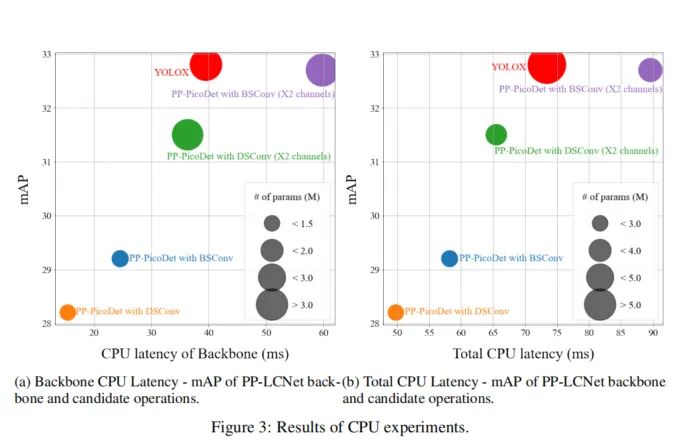
图3a显示了主干网络的CPU延迟和上述检测器的mAP。使用PP-LCNet作为主干,可以生成轻量化检测器。与采用深度可分离卷积运算的检测器相比,采用蓝图可分离卷积运算作为主要运算的检测器速度较慢,并且显示出更高的mAP。不幸的是,与YOLOX基线相比,采用PP-LCNet作为主干网络的检测器显示出低mAP,其参数数量少。
为了改进mAP,还分析了具有较大通道的骨干网络。它们在牺牲延迟的同时显示了mAP的许多改进。尽管每个主干中的参数数量与YOLOX相似,但延迟或mAP都比YOLOX差。当主干网络中的通道数改变时,FPN中的通道也应改变。然而,由于检测头在所有实验中都是固定的,所以具有较大通道的PP-LCNet的输出通道是均衡的,因此其FPN架构比其他的更小。
图3b显示了图3a中相同检测器的整个检测器和mAP的CPU延迟,以考虑其FPN架构。与YOLOX基线相比,采用DSConv作为主要操作并具有较大通道的检测器显示出更快的延迟和更少的参数。
3.5、FPN architecture analysis
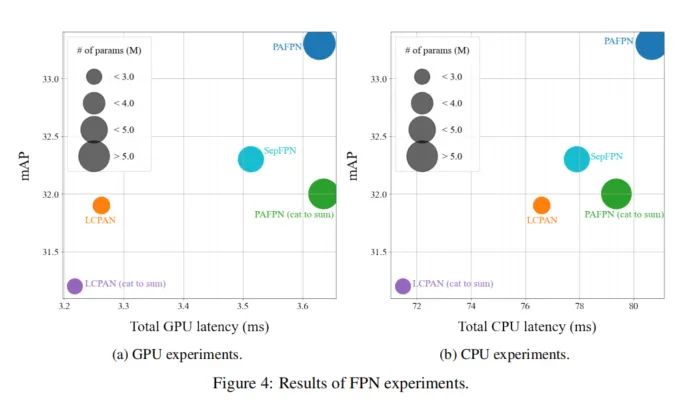
在本节中,使用第4.3节中搜索的主干网络来研究FPN架构的性能。PAFPN是YOLOX的默认FPN架构,在mAP方面是最好的。LCPAN是PP-PicoDet的默认FPN架构,在参数数量和延迟方面是最好的。建议的FPN架构(用和替换级联操作)与基线相比性能不佳。所提出的FPN架构的预期效果是保留语义,同时通过对不同块的特征求和来减少FPN中的通道。然而,它并没有像预期的那样工作。特别是,基于PAFPN的FPN架构在GPU上表现不佳。这意味着减少FPN中的信道并不能减少延迟,因为GPU具有巨大的并行计算能力。
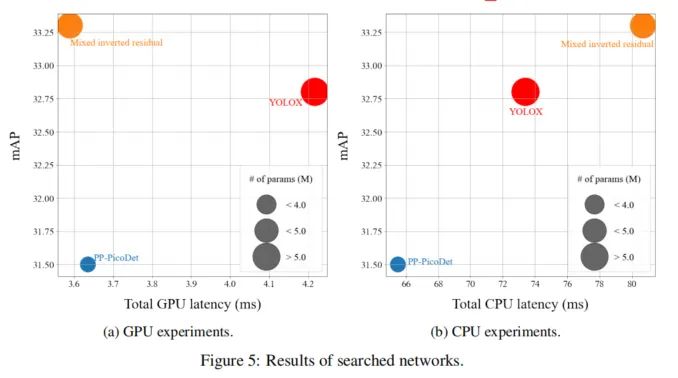
4、结论
这项工作分析了一种新型单阶段检测器的设计空间。目标检测器的最佳结构设计取决于目标硬件和用途。图5显示了第4节中搜索的网络以及YOLOX基线。图5a表示在GPU上执行的基线、GPU目标检测器和CPU目标检测器的mAP和延迟。GPU目标检测器 用橙色圆点标记的表示最佳mAP,同时实现最佳GPU延迟,即使CPU目标检测器的参数数量较少。
因此,本文搜索的GPU目标检测器在这两方面都是最好的。图5a表示在CPU上执行的与图5a相同的检测器的mAP和延迟。用蓝点标记的CPU目标检测器显示最差的mAP,但它比其他CPU检测器快得多。
此外,与其他参数相比,它的参数数量要少得多。因此,如果没有足够的计算能力和能量预算,CPU目标检测器可能是一个很好的解决方案。图5没有绘制FPN结果。然而,FPN也是检测器中的一个重要因素,应根据用途仔细设计。
参考:Tech Report:One-stage Lightweight Object Detectors
公众号后台回复“ECCV2022”获取论文资源分类汇总下载~

“
点击阅读原文进入CV社区
收获更多技术干货



