当知识图谱遇上文本摘要:保留抽象式文本摘要的事实性知识

论文标题:
Boosting Factual Correctness of Abstractive Summarization with Knowledge Graph
论文作者:
Chenguang Zhu, William Hinthorn, Ruochen Xu, Qingkai Zeng, Michael Zeng, Xuedong Huang, Meng Jiang
论文链接:
https://arxiv.org/abs/2003.08612
抽象式文本摘要具有更加灵活的特点,然而,它也容易导致“文本事实偏离”——错误地提取了文章给出的基本事实。此时,尽管生成的文本很通顺,但是它包含了错误的事实,这就改变了原文的信息。
本文提出把知识图谱融入到文本摘要的过程中,通过显式地提取事实性知识,生成的摘要可以更好地利用这些知识,从而最大限度地保留原义。
抽象式文本摘要与事实性知识丢失
文本摘要是NLP中非常重要的一项任务,即给定一篇长文章,模型生成一小段文本作为对该文章的摘要。
总的来讲,文本摘要分为抽取式与抽象式。前者是直接从文章中选取片段作为摘要,后者是从头开始生成一段文本作为摘要。
显然,抽取式文本摘要的好处是它能保留文章的原始信息,但缺点是它只能从原文章中选取,相对不那么灵活。
而抽象式摘要尽管能更加灵活地生成文本,但是它经常包含很多错误的“事实性知识”——错误地生成了原文章本来的信息。
比如,原文章包含了一个重要事实(观点):“诺兰于2010年导演了《盗梦空间》,由莱昂纳多主演。”
但是,抽象式摘要模型可能就会生成:“莱昂纳多导演了《盗梦空间》。”这就是事实性知识的错误。
针对这种现象,本文在抽象式摘要中融入了知识图谱:
首先使用知识图谱动态地提取文章中的事实性知识;
把提取到的事实性知识融合到文本生成的过程中;
使得生成的文本不再包含事实性知识错误。
除此之外,本文还训练了一个事实性知识评估模型,用于评估生成的摘要匹配原文事实性知识的程度。
通过在基准数据集CNN/DailyMail和XSum的实验与分析,本文证明了该方法(FASUM)可以取得显著更好的事实性知识度,同时也具有抽象式文本摘要的灵活的特点。
将知识图谱融入到文本摘要过程
首先定义一下抽象式文本摘要的过程。设输入是一篇文章,输出是对应的摘要
。下图是模型结构示意图:

模型由三个部分组成:知识提取器(知识图谱)、编码器和解码器。知识图谱负责从文章中提取事实性知识,编码器负责编码文本信息,解码器负责融合编码特征和事实性知识从而生成摘要。
知识图谱构建
我们使用Stanford OpenIE从文章中提取事实性知识,每个知识表示为一个三元组。
比如对句子“Born in a town, she took the midnight train”,那么三元组就是(she, took, midnight train)。
在得到三元组之后,我们需要把它编码为特征。为此,我们要首先构建一个基于文章的知识图谱。
对每个三元组,我们把视为三个结点,然后得到两条无向边
。这样一来,通过对所有三元组构建边,我们就能得到一个无向图,这就是该文章的知识图谱。
之后,我们在该知识图谱上使用图注意力模型提取每个结点的特征。如此,我们就完成了事实性知识特征的提取。
注意到,图中的所有结点是文章的所有语言单元(如字、词或子词),如果涉及到事实性知识,它就有边连接,否则它没有边连接。
知识融合
编码器按照常规方法编码文章,之后在解码的时候把它和解码器特征、知识特征融合。
如上图所示,设编码特征和解码特征融合后的特征是,其中
是已经生成的字(词)数,且
是知识图谱中的结点的特征。那么,当前需要融入的事实性知识的特征就是:

这里增加了一个系数是因为知识特征和文本特征的尺度不一致,
是当前解码层数。
在得到之后,就可以通过常规的自注意力机制、层归一化和残差连接,和前馈层将各知识融合在一起,如上图中间所示,得到该层最终的特征表示
。
摘要生成
为了生成下一个语言单元,我们结合拷贝机制:

从而,最终生成语言单元的概率是:

其中,

事实性知识正确度评估
现在的问题是,我们该如何评估我们是否融入了事实性知识呢?我们可以用一个模型


模型

训练集包含正例和负例。正例来自:原摘要训练语料、摘要的反译(Backtranslation)。反例来自:随机将摘要中的一个实体替换为文章中的同类实体。
在测试集上,该模型能实现最低的错误率——约26.8%。
实验
我们在文本摘要的标准数据集CNN/DailyMail和XSum上实验。事实性知识的评估使用上面训练的模型
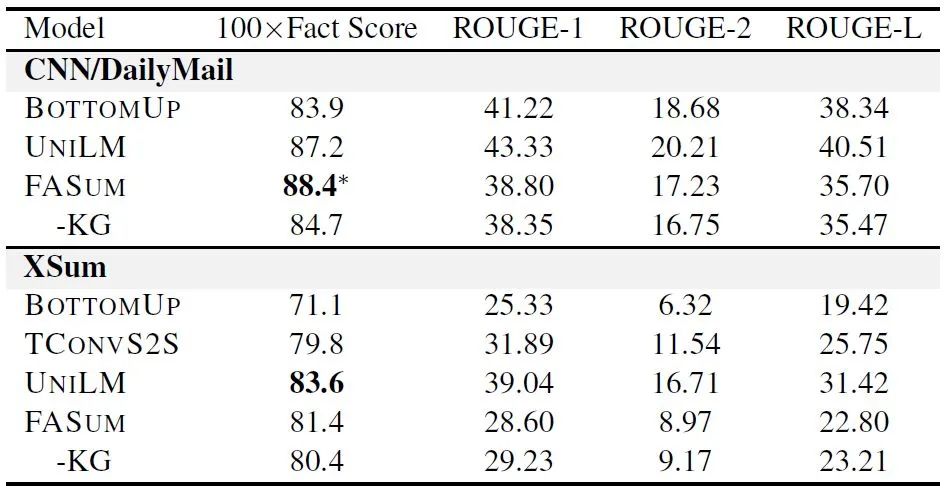
下表是主要结果。可以看到,本文的方法(FASUM)在事实性知识评估上取得了和UNILM差不多的结果(后者使用了大规模预训练),同时,去掉知识图谱(KG)会显著减低其得分,说明了知识图谱提取事实性知识的作用。在ROUGH得分方面,FASUM稍低于基线模型。
为了检验抽象式摘要生成文本的“抽象程度”——生成新的n-gram的比例,如下图所示。可以看到,FASUM在所有方法中,可以生成更加新颖的摘要,同时保留了事实性知识。

下面我们想具体看生成的摘要中包含的事实性知识和原文章的事实性知识的匹配程度如何。假设摘要中的事实性知识是


——correct hit(C)
,但是
或者
——wrong hit(W)
否则,为miss(M)



于是,我们可以计算匹配得分:

下表是计算结果。可以看到,FASUM在事实性知识匹配程度上显著优于基线模型,这说明在文本摘要中加入知识图谱的确可以保留事实性知识。

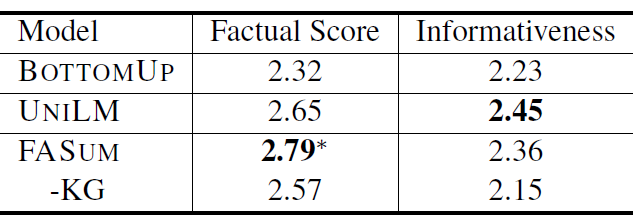
我们再来看看人工评测。如下表所示,在事实性得分上,FASUM毫无疑问取得最好结果;在信息度上,UNILM得分最高,其次是FASUM。
小结
在文本摘要中,提取事实性知识,即原文信息,是非常重要的一个环节。尽可能保留原文可以避免原义的曲解,对于鉴别当前互联网上随处可见的假新闻有重要的意义。
将知识图谱融入到文本摘要任务中是NLP发展的一大趋势,有助于加速NLP大规模落地应用的进程。
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。