一文理解 K8s 容器网络虚拟化

一 内核网络包接收流程
1 从网卡到内核协议栈
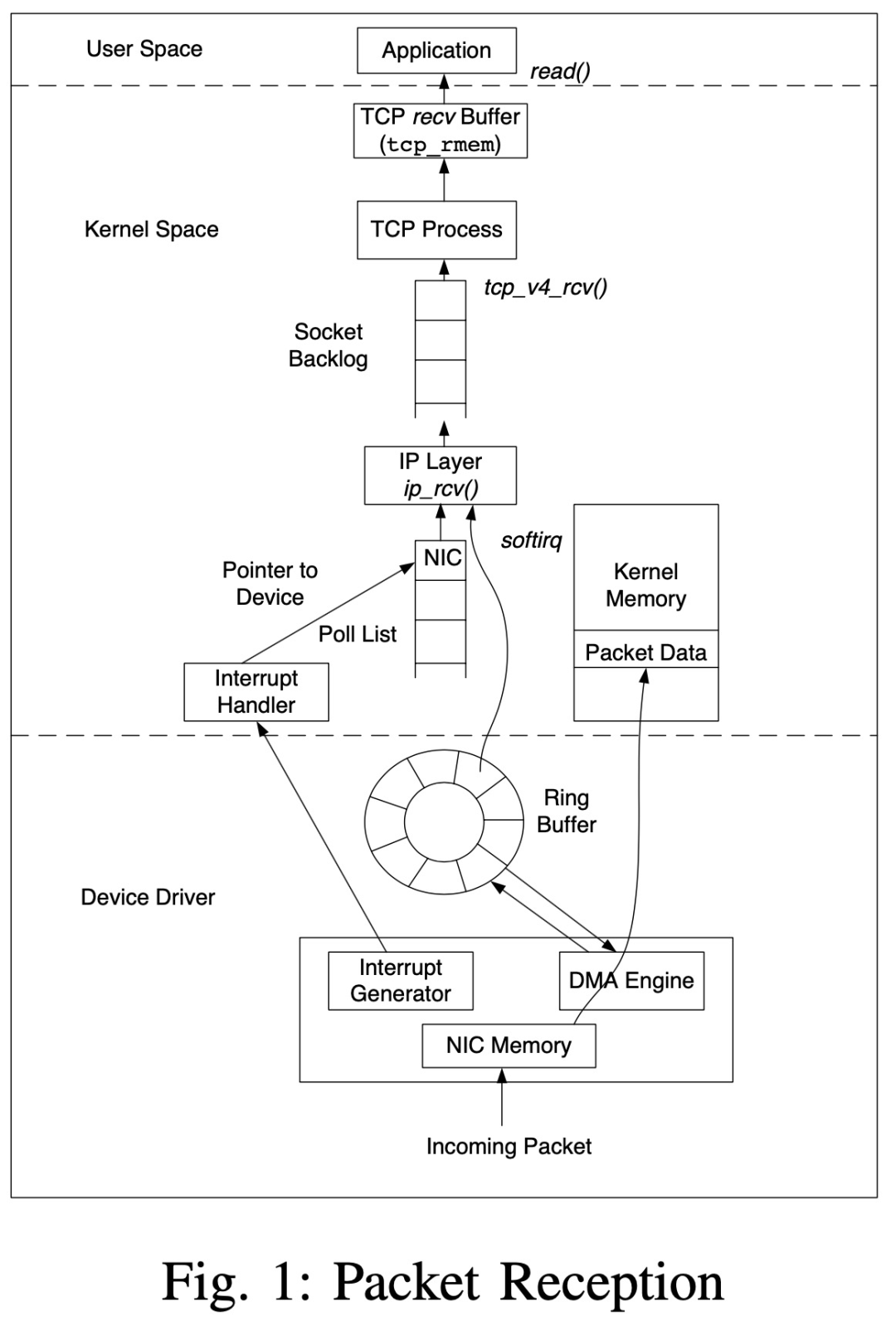
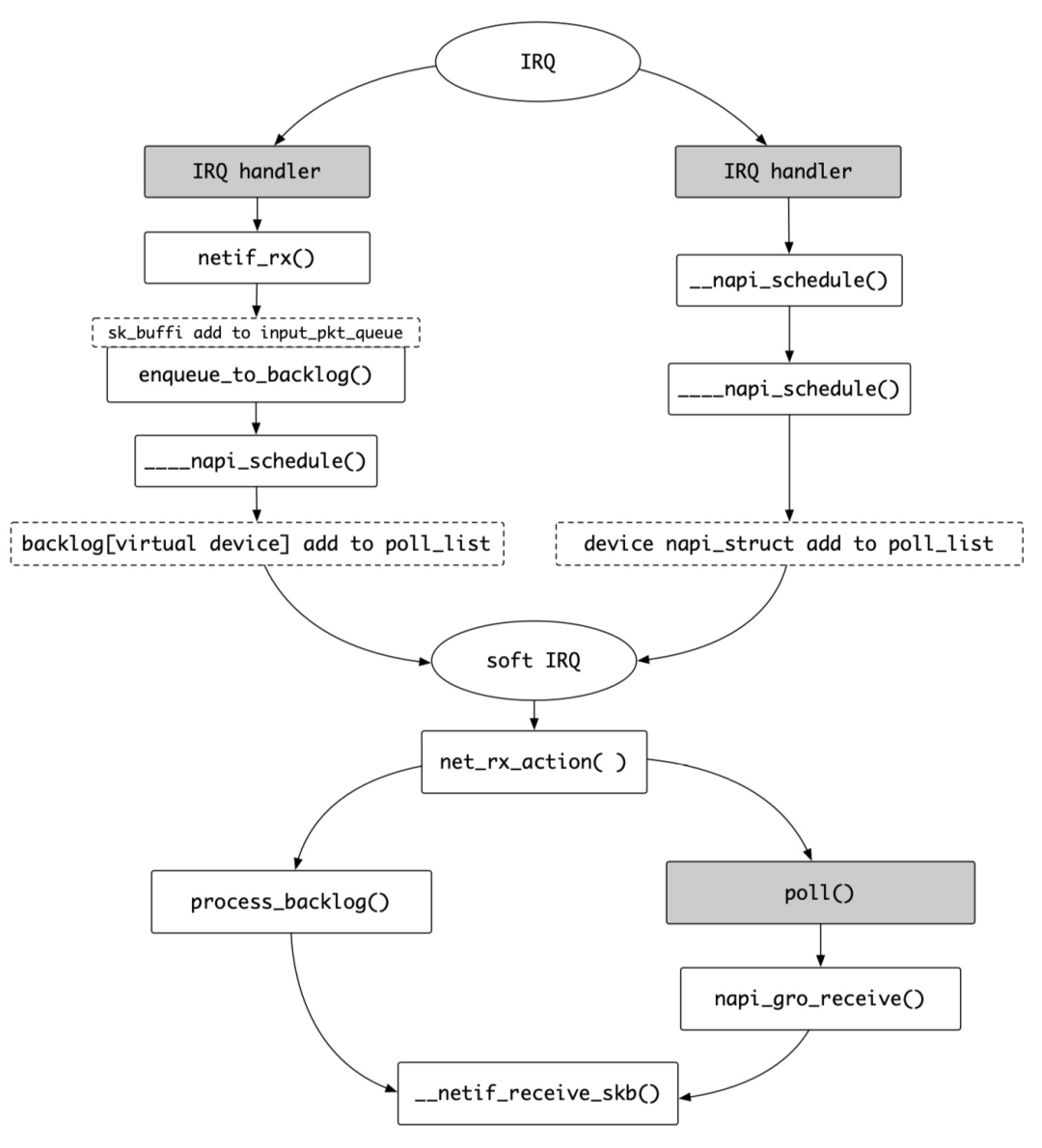
2 内核协议栈网络包处理流程
-
处理 ptype_all 上所有的 packet_type->func() ,典型场景是 tcpdump 等工具的抓包回调( paket_type.type 为 ETH_P_ALL , libcap 使用 AF_PACKET Address Family )
-
处理 VLAN ( Virtual Local Area Network ,虚拟局域网)报文 vlan_do_receive() 以及处理网桥的相关逻辑( skb->dev->rx_handler() 指向了 br_handle_frame() )
-
处理 ptype_base 上所有的 packet_type->func() , 将数据包传递给上层协议层处理,例如指向 IP 层的回调 ip_rcv() 函数
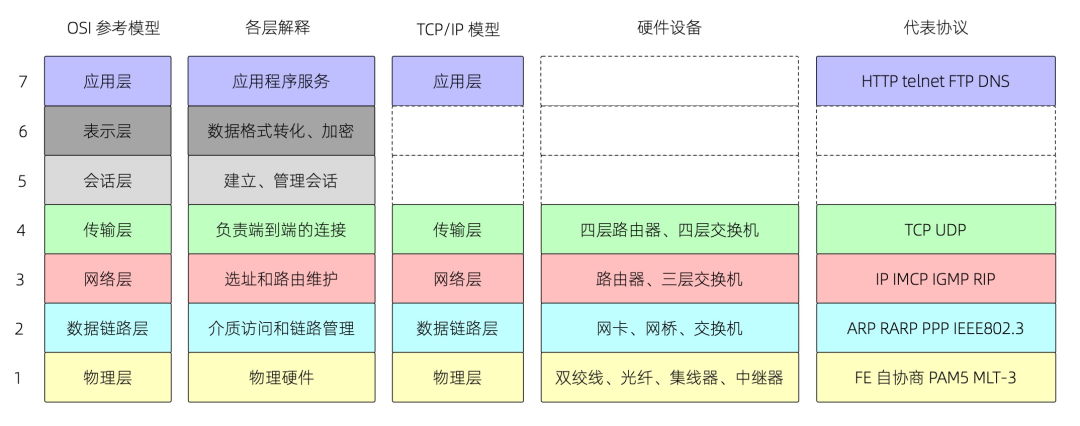
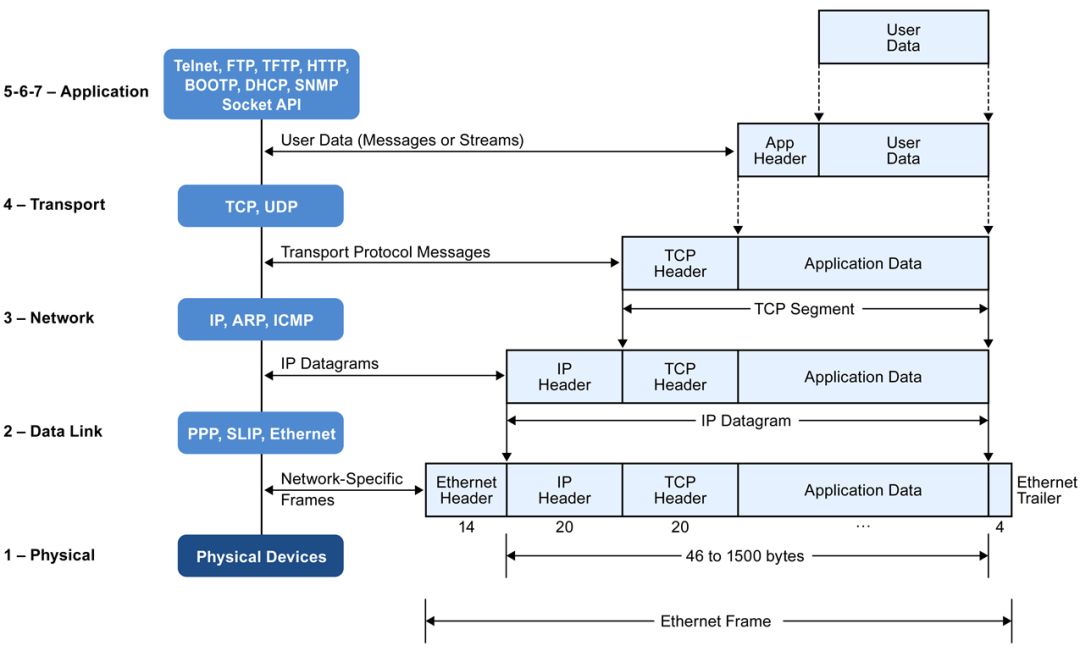
3 Netfilter/iptables 与 NAT(网络地址转换)
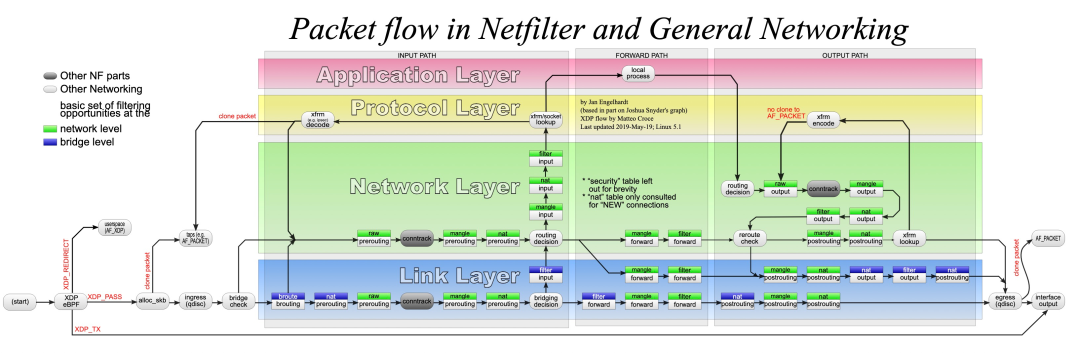
二 虚拟网络设备
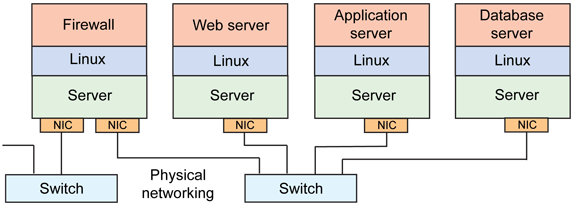
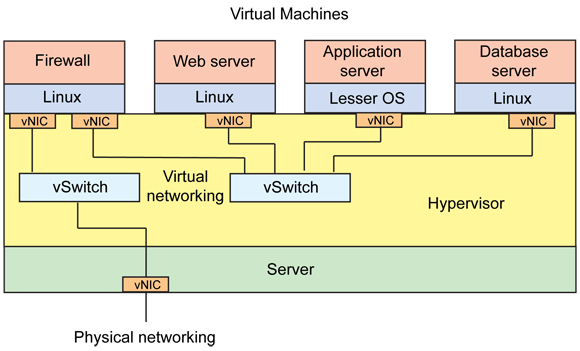
-
Tap/Tun 是 Linux 内核实现的一对虚拟网络设备,Tap/Tun 分别工作在二层/三层。Linux 内核通过 Tap/Tun 设备和绑定该设备的用户空间之间交换数据。基于 Tap 驱动即可实现虚拟机 vNIC 的功能,Tun 设备做一些其他的转发功能。
-
Veth 设备总是成对创建(Veth Pair),一个设备收到内核发送的数据后,会发送到另一个设备上去,可以把 Veth Pair 可以想象成一对用网线连接起来的 vNIC 设备。
-
Bridge 是工作在二层的虚拟网桥。这是虚拟设备,虽然叫网桥,但其实类似 vSwitch 的设计。当 Bridge 配合 Veth 设备使用时,可以将 Veth 设备的一端绑定到一个Bridge 上,相当于真实环境把一个 NIC 接入一个交换机里。
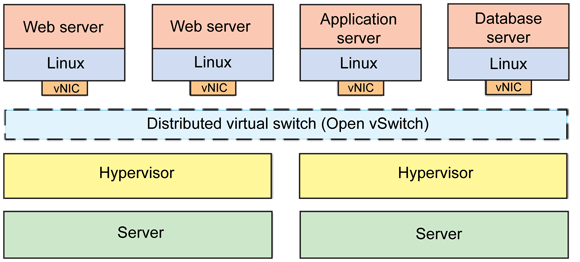
1 Linux Bridge + Veth Pair 转发
创建、查看、删除 Network Namespace
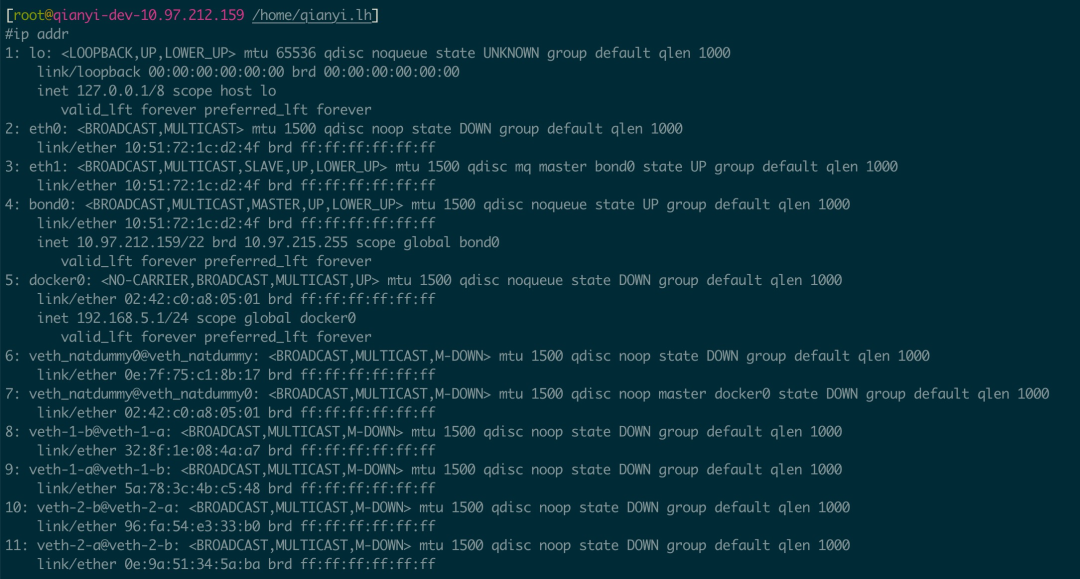
# 创建名为 qianyi-test-1 和 add qianyi-test-2 的命名 netns,可以在 /var/run/netns/ 下查看ip netns add qianyi-test-1ip netns add qianyi-test-2
# 查看所有的 Network Namespaceip netns list
# 删除 Network Namespaceip netns del qianyi-test-1ip netns del qianyi-test-2

在 netns 中执行命令
# 在 qianyi-test-1 这个 netns 中执行 ip addr 命令(甚至可以直接执行 bash 命令得到一个 shell)# nsenter 这个命令也很好用,可以 man nsenter 了解ip netns exec qianyi-test-1 ip addr

# 开启 lo 网卡,这个很重要ip netns exec qianyi-test-1 ip link set dev lo upip netns exec qianyi-test-2 ip link set dev lo up

创建 Veth Pair 设备
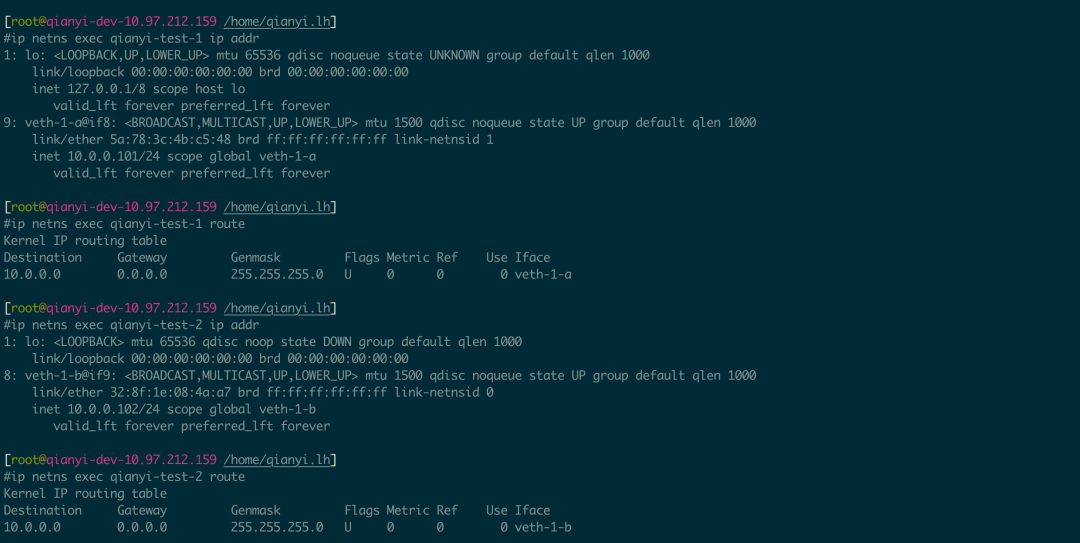
# 分别创建 2 对名为 veth-1-a/veth-1-b 和 veth-2-a/veth-2-b 的 Veth Pair 设备ip link add veth-1-a type veth peer name veth-1-bip link add veth-2-a type veth peer name veth-2-b
将 Veth Pair 设备加入 netns
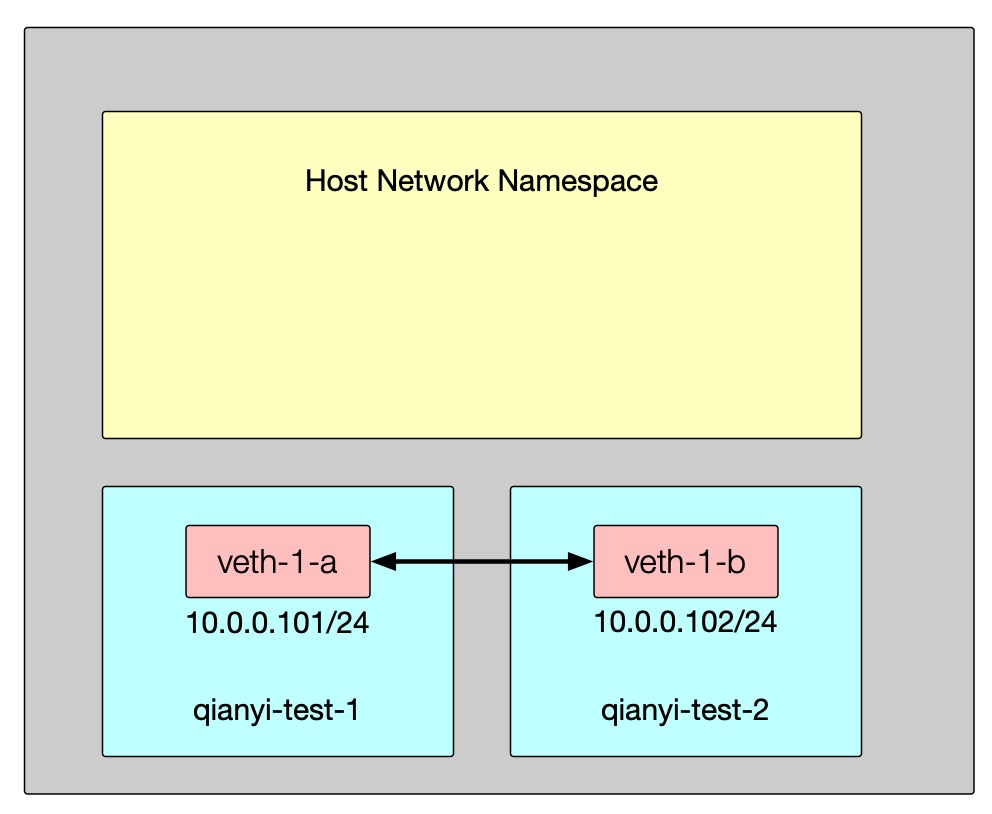
# 将 veth-1-a 设备加入 qianyi-test-1 这个 netnsip link set veth-1-a netns qianyi-test-1
# 将 veth-1-b 设备加入 qianyi-test-2 这个 netnsip link set veth-1-b netns qianyi-test-2
# 为设备添加 IP 地址/子网掩码并开启ip netns exec qianyi-test-1 ip addr add 10.0.0.101/24 dev veth-1-aip netns exec qianyi-test-1 ip link set dev veth-1-a up
ip netns exec qianyi-test-2 ip addr add 10.0.0.102/24 dev veth-1-bip netns exec qianyi-test-2 ip link set dev veth-1-b up
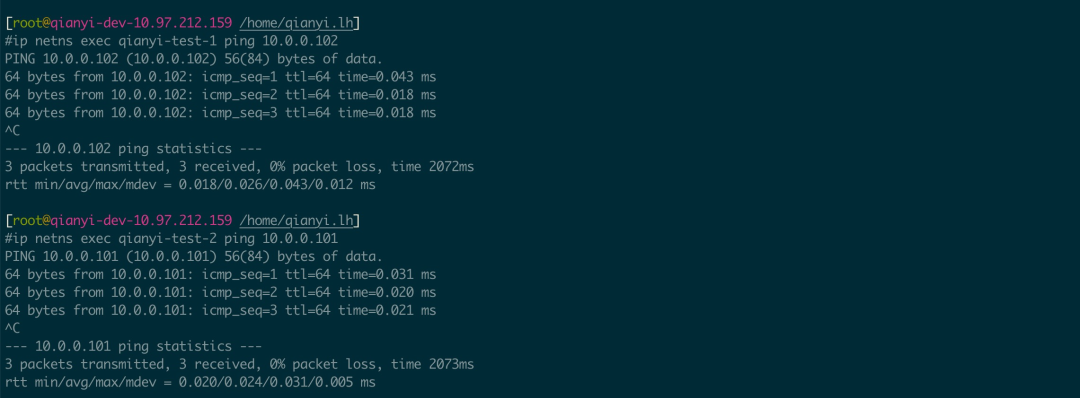
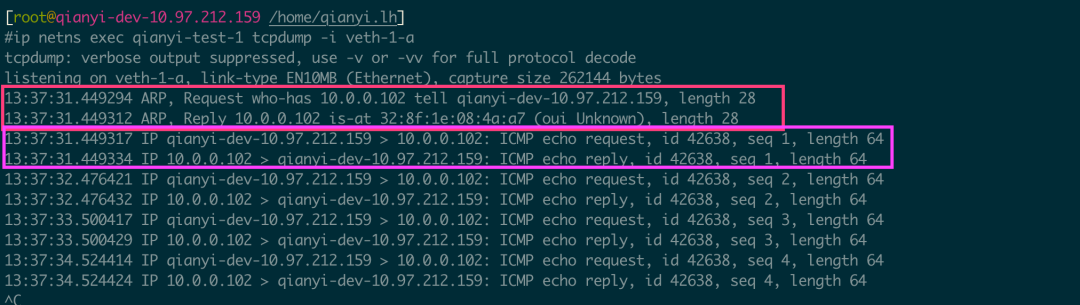

# 宿主机的 netns id 是 1(有些系统可能不是,请查询相关系统的文档)ip netns exec qianyi-test-1 ip link set veth-1-a netns 1ip netns exec qianyi-test-2 ip link set veth-1-b netns 1
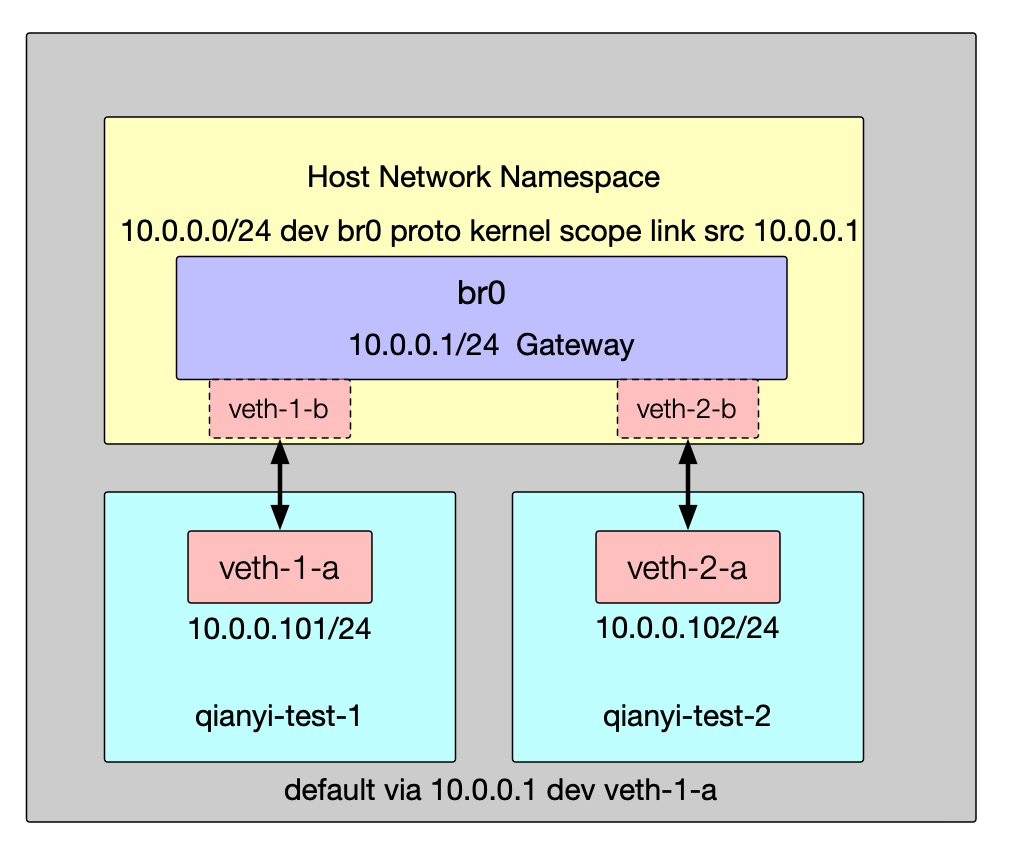
创建 Linux Bridge 并配置网络
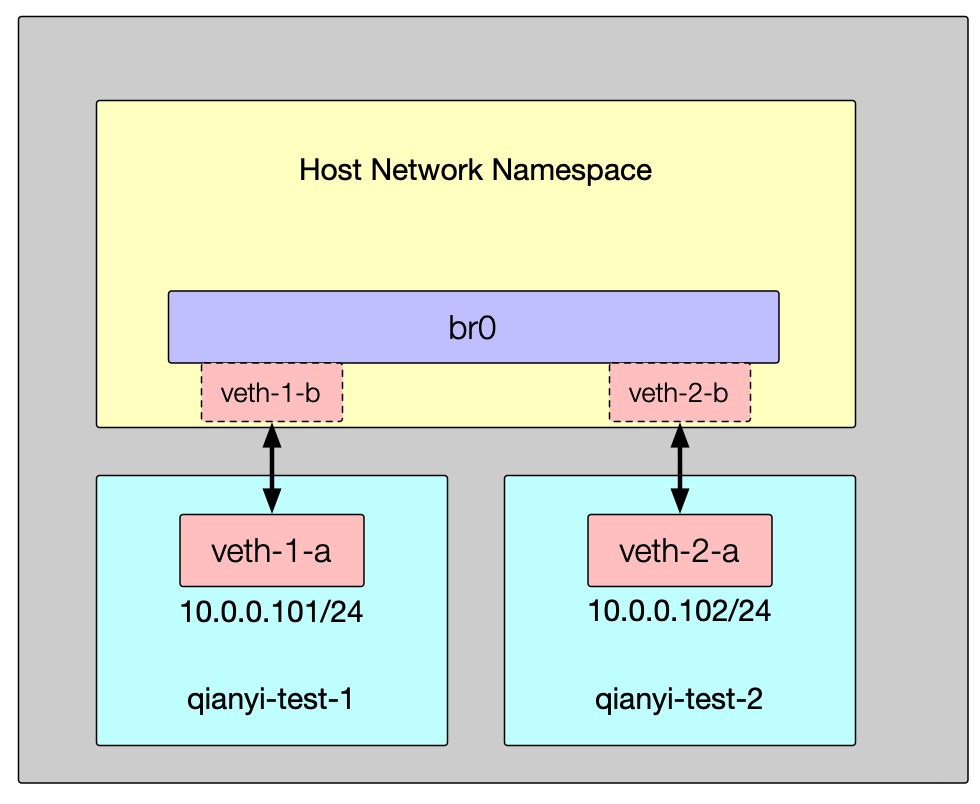
# 创建一个名为 br0 的 bridge 并启动(也可以使用 brctl 命令)ip link add br0 type bridgeip link set br0 up
# 将 veth-1-a/veth-1-b 和 veth-2-a/veth-2-b 这两对 Veth Pair 的 a 端放入 qianyi-test-1 和 qianyi-test-2ip link set veth-1-a netns qianyi-test-1ip link set veth-2-a netns qianyi-test-2
# 为 veth-1-a 和 veth-2-a 配置 IP 并开启ip netns exec qianyi-test-1 ip addr add 10.0.0.101/24 dev veth-1-aip netns exec qianyi-test-1 ip link set dev veth-1-a up
ip netns exec qianyi-test-2 ip addr add 10.0.0.102/24 dev veth-2-aip netns exec qianyi-test-2 ip link set dev veth-2-a up
# 将 veth-1-a/veth-1-b 和 veth-2-a/veth-2-b 这两对 Veth Pair 的 b 端接入 br0 网桥并开启接口ip link set veth-1-b master br0ip link set dev veth-1-b upip link set veth-2-b master br0ip link set dev veth-2-b up
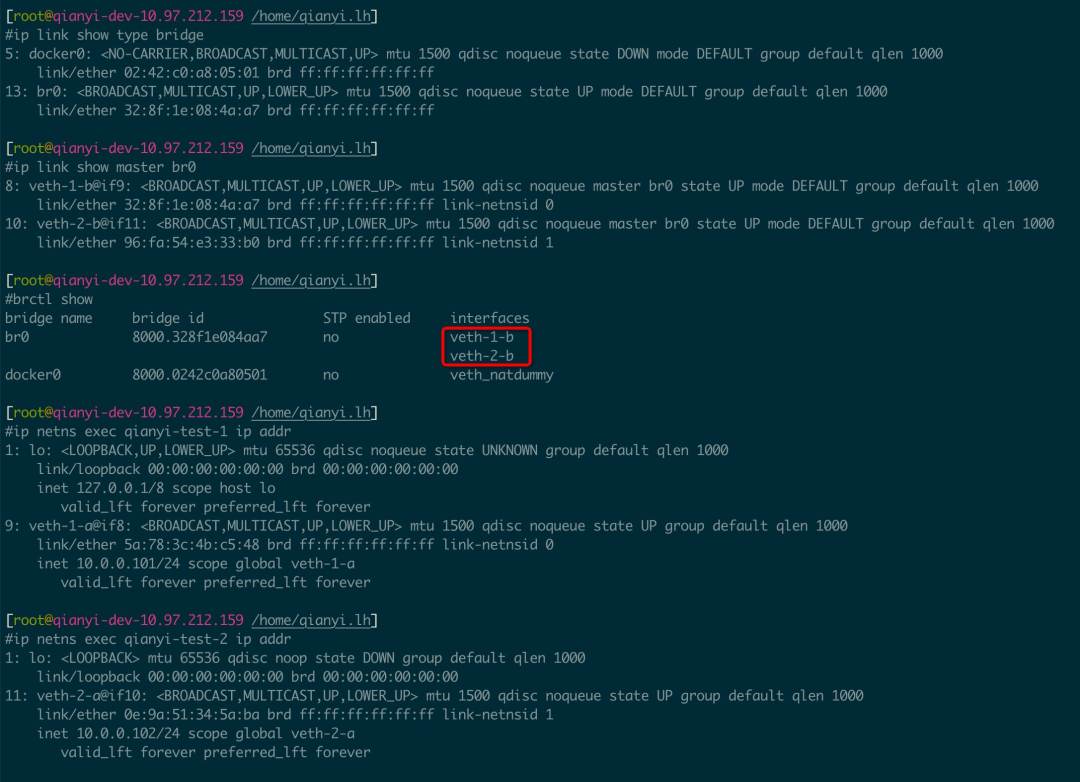

# 确认路由转发开启echo "1" > /proc/sys/net/ipv4/ip_forward
# 为 br0 设置 IP 地址ip addr add local 10.0.0.1/24 dev br0
# 为 veth-1-a 和 veth-2-a 设置默认网关ip netns exec qianyi-test-1 ip route add default via 10.0.0.1ip netns exec qianyi-test-2 ip route add default via 10.0.0.1

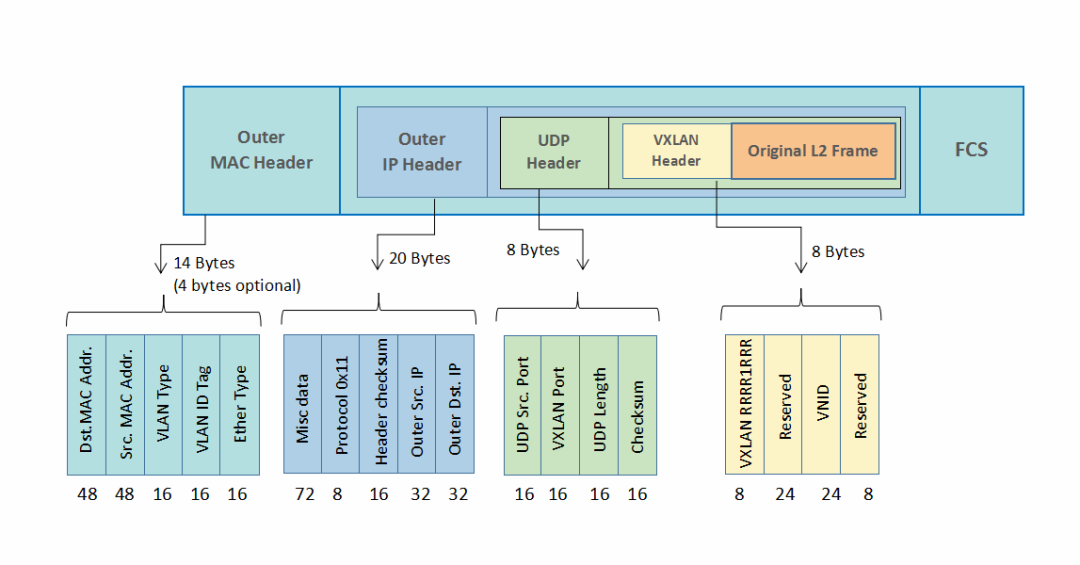
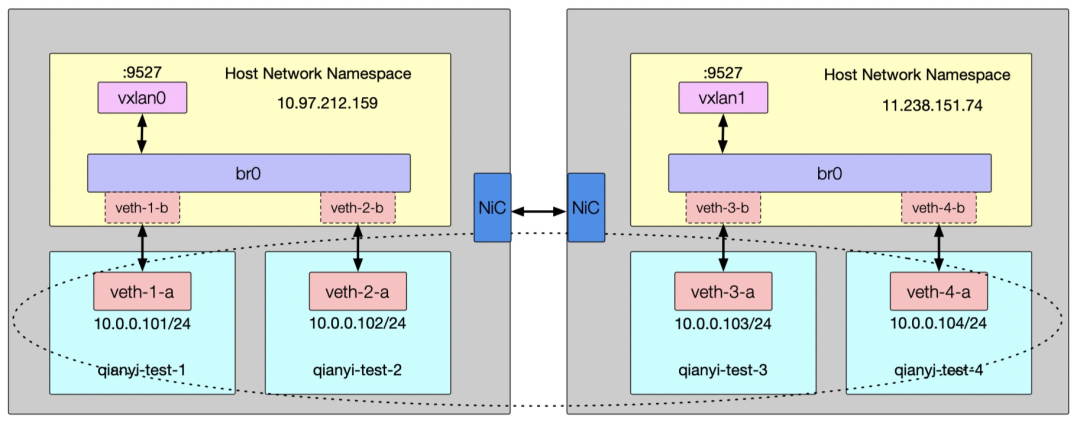
2 Overlay 网络方案之 VXLAN
-
VTEP(VXLAN Tunnel Endpoints,VXLAN 隧道端点),负责 VXLAN 报文的封装和解封,对上层隐藏了链路层帧的转发细节
-
VNI(VXLAN Network Identifier,VXLAN 网络标识符),代表不同的租户,属于不同 VNI 的虚拟网络之间不能直接进行二层通信。
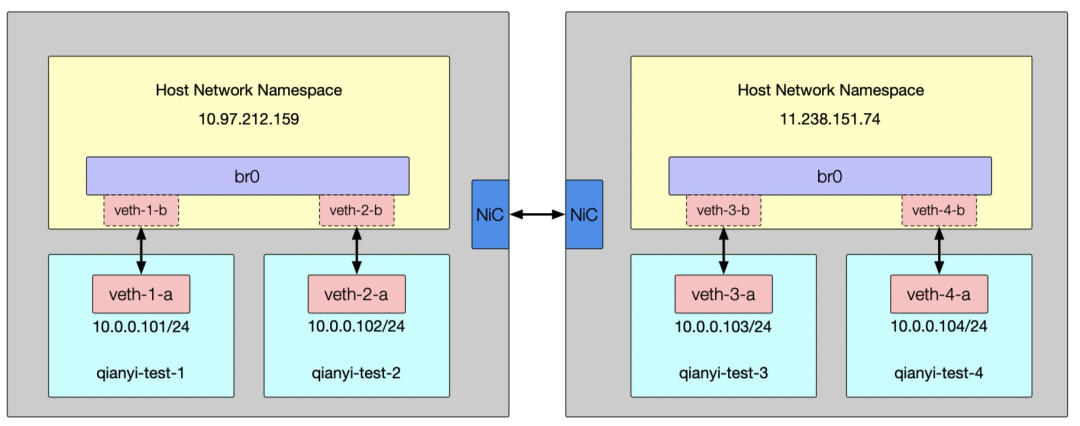
# 10.97.212.159 上操作
# 创建名为 qianyi-test-1 和 add qianyi-test-2 的命名 netns,可以在 /var/run/netns/ 下查看ip netns add qianyi-test-1ip netns add qianyi-test-2
# 开启 lo 网卡,这个很重要ip netns exec qianyi-test-1 ip link set dev lo upip netns exec qianyi-test-2 ip link set dev lo up
# 创建一个名为 br0 的 bridge 并启动(也可以使用 brctl 命令)ip link add br0 type bridgeip link set br0 up
# 分别创建 2 对名为 veth-1-a/veth-1-b 和 veth-2-a/veth-2-b 的 Veth Pair 设备ip link add veth-1-a type veth peer name veth-1-bip link add veth-2-a type veth peer name veth-2-b
# 将 veth-1-a/veth-1-b 和 veth-2-a/veth-2-b 这两对 Veth Pair 的 a 端放入 qianyi-test-1 和 qianyi-test-2ip link set veth-1-a netns qianyi-test-1ip link set veth-2-a netns qianyi-test-2
# 为 veth-1-a 和 veth-2-a 配置 IP 并开启ip netns exec qianyi-test-1 ip addr add 10.0.0.101/24 dev veth-1-aip netns exec qianyi-test-1 ip link set dev veth-1-a up
ip netns exec qianyi-test-2 ip addr add 10.0.0.102/24 dev veth-2-aip netns exec qianyi-test-2 ip link set dev veth-2-a up
# 将 veth-1-a/veth-1-b 和 veth-2-a/veth-2-b 这两对 Veth Pair 的 b 端接入 br0 网桥并开启接口ip link set veth-1-b master br0ip link set dev veth-1-b upip link set veth-2-b master br0ip link set dev veth-2-b up
# 11.238.151.74 上操作
# 创建名为 qianyi-test-3 和 add qianyi-test-4 的命名 netns,可以在 /var/run/netns/ 下查看ip netns add qianyi-test-3ip netns add qianyi-test-4
# 开启 lo 网卡,这个很重要ip netns exec qianyi-test-3 ip link set dev lo upip netns exec qianyi-test-4 ip link set dev lo up
# 创建一个名为 br0 的 bridge 并启动(也可以使用 brctl 命令)ip link add br0 type bridgeip link set br0 up
# 分别创建 2 对名为 veth-3-a/veth-3-b 和 veth-4-a/veth-4-b 的 Veth Pair 设备ip link add veth-3-a type veth peer name veth-3-bip link add veth-4-a type veth peer name veth-4-b
# 将 veth-3-a/veth-3-b 和 veth-4-a/veth-4-b 这两对 Veth Pair 的 a 端放入 qianyi-test-3 和 qianyi-test-4ip link set veth-3-a netns qianyi-test-3ip link set veth-4-a netns qianyi-test-4
# 为 veth-3-a 和 veth-4-a 配置 IP 并开启ip netns exec qianyi-test-3 ip addr add 10.0.0.103/24 dev veth-3-aip netns exec qianyi-test-3 ip link set dev veth-3-a up
ip netns exec qianyi-test-4 ip addr add 10.0.0.104/24 dev veth-4-aip netns exec qianyi-test-4 ip link set dev veth-4-a up
# 将 veth-3-a/veth-3-b 和 veth-4-a/veth-4-b 这两对 Veth Pair 的 b 端接入 br0 网桥并开启接口ip link set veth-3-b master br0ip link set dev veth-3-b upip link set veth-4-b master br0ip link set dev veth-4-b up
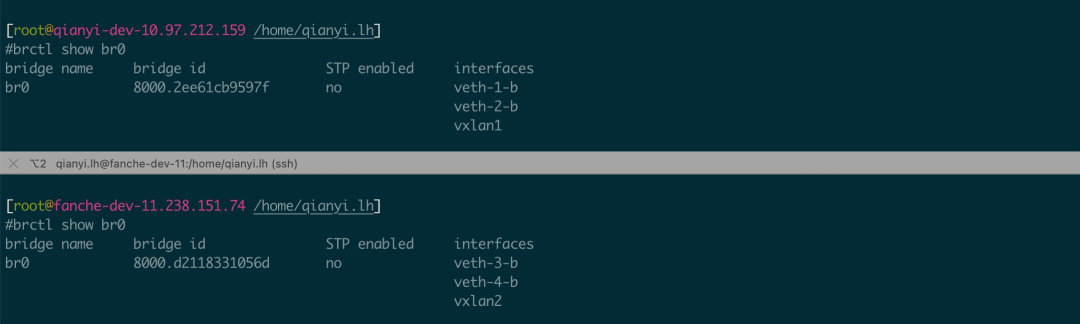
# 10.97.212.159 上操作(本机有多个地址时可以用 local 10.97.212.159 指定)ip link add vxlan1 type vxlan id 1 remote 11.238.151.74 dstport 9527 dev bond0ip link set vxlan1 master br0ip link set vxlan1 up
# 11.238.151.74 上操作(本机有多个地址时可以用 local 11.238.151.74 指定)ip link add vxlan2 type vxlan id 1 remote 10.97.212.159 dstport 9527 dev bond0ip link set vxlan2 master br0ip link set vxlan2 up



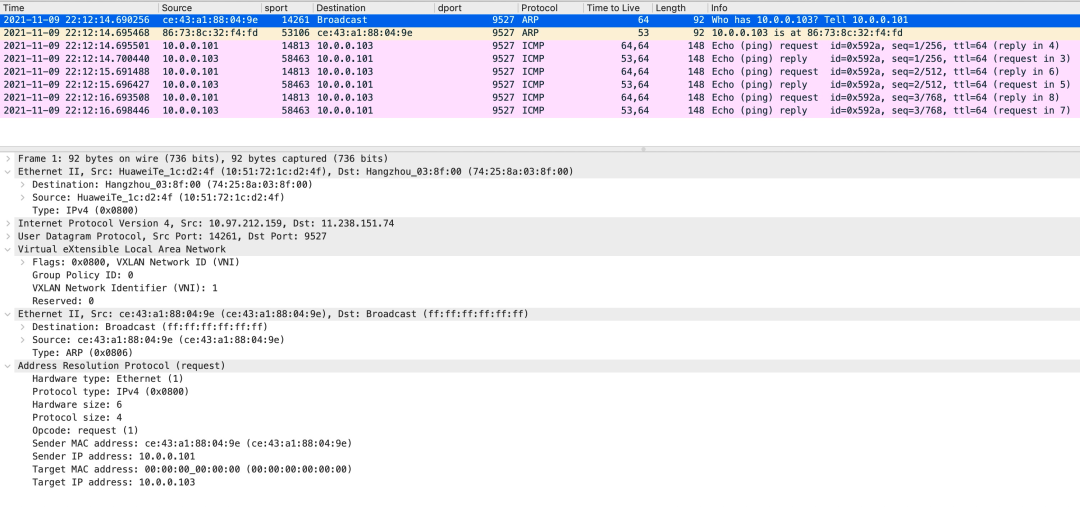
# 新增条目bridge fdb add <remote_host_mac_addr> dev <vxlan_interface> dst <remote_host_ip_addr>
# 删除条目bridge fdb del <remote_host_mac_addr> dev <vxlan_interface>
# 替换条目bridge fdb replace <remote_host_mac_addr> dev <vxlan_interface> dst <remote_host_ip_addr>
# 显示条目bridge fdb show
三 K8s 的网络虚拟化实现
1 K8s 的网络模型
每一个 Pod 都有它自己的 IP 地址,这就意味着你不需要显式地在每个 Pod 之间创建链接, 你几乎不需要处理容器端口到主机端口之间的映射。这将创建一个干净的、向后兼容的模型,在这个模型里,从端口分配、命名、服务发现、 负载均衡、应用配置和迁移的角度来看,Pod 可以被视作虚拟机或者物理主机。
Kubernetes 对所有网络设施的实施,都需要满足以下的基本要求(除非有设置一些特定的网络分段策略):
节点上的 Pod 可以不通过 NAT 和其他任何节点上的 Pod 通信 节点上的代理(比如:系统守护进程、kubelet)可以和节点上的所有 Pod 通信
备注:仅针对那些支持 Pods 在主机网络中运行的平台(比如:Linux):
那些运行在节点的主机网络里的 Pod 可以不通过 NAT 和所有节点上的 Pod 通信
这个模型不仅不复杂,而且还和 Kubernetes 的实现廉价的从虚拟机向容器迁移的初衷相兼容, 如果你的工作开始是在虚拟机中运行的,你的虚拟机有一个 IP,这样就可以和其他的虚拟机进行通信,这是基本相同的模型。
Kubernetes 的 IP 地址存在于 Pod 范围内 - 容器共享它们的网络命名空间 - 包括它们的 IP 地址和 MAC 地址。这就意味着 Pod 内的容器都可以通过 localhost 到达各个端口。这也意味着 Pod 内的容器都需要相互协调端口的使用,但是这和虚拟机中的进程似乎没有什么不同, 这也被称为“一个 Pod 一个 IP”模型。
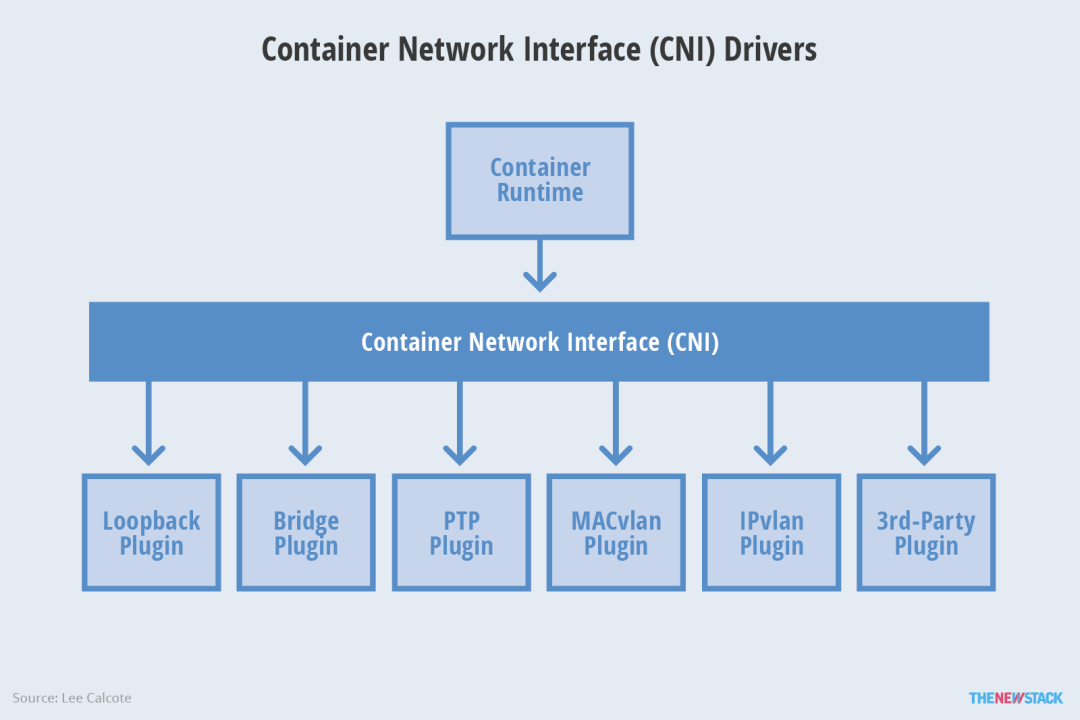
2 K8s 的主流网络插件实现原理
-
CNI 插件:遵守 CNI(Container Network Interface,容器网络接口)规范,其设计上偏重互操作性
-
Kubenet 插件:使用 bridge 和 host-local CNI 插件实现了基本的 cbr0
-
Flannel:https://github.com/flannel-io/flannel -
Calico:https://github.com/projectcalico/calico
-
Cilium:https://github.com/cilium/cilium
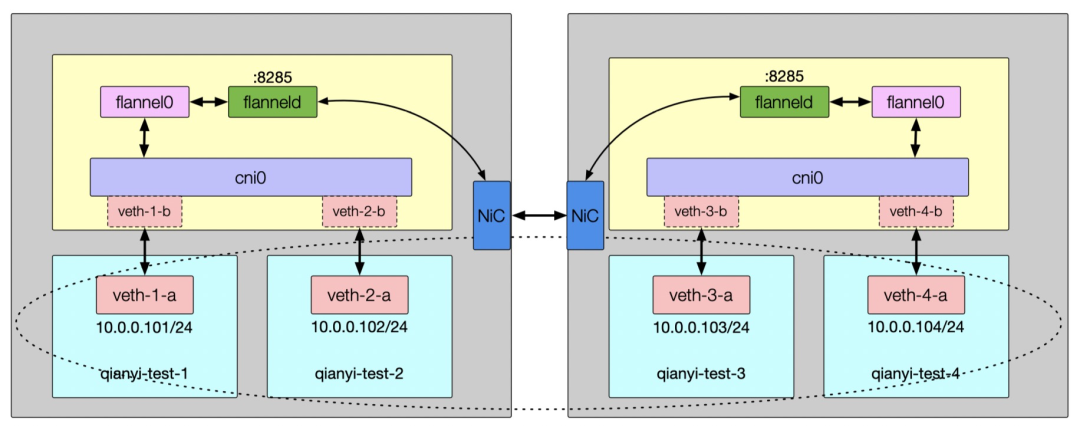
Flannel
1)VXLAN
2)host-gw
3)UDP
Calico
Cilium
eBPF-based Networking, Security, and Observability
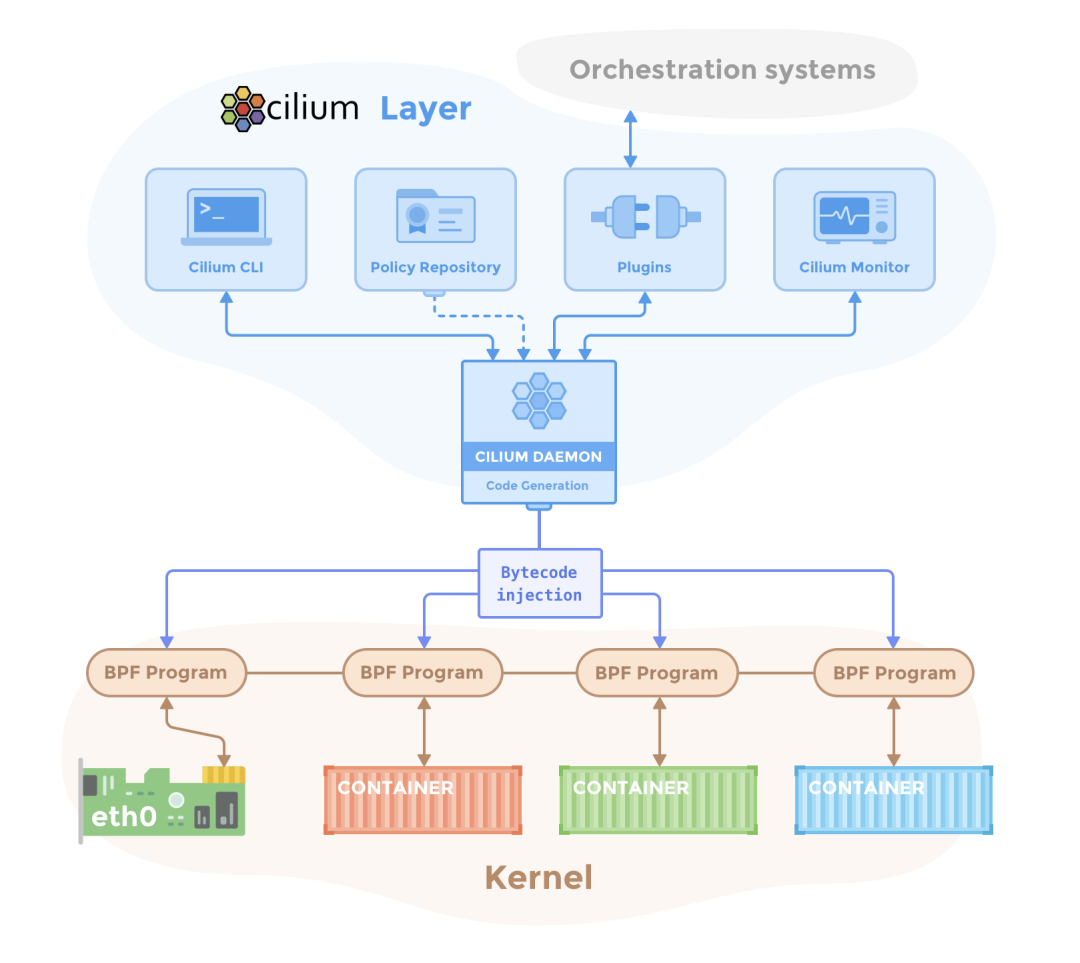
3 K8s 容器内访问隔离
4 K8s 容器内服务透出
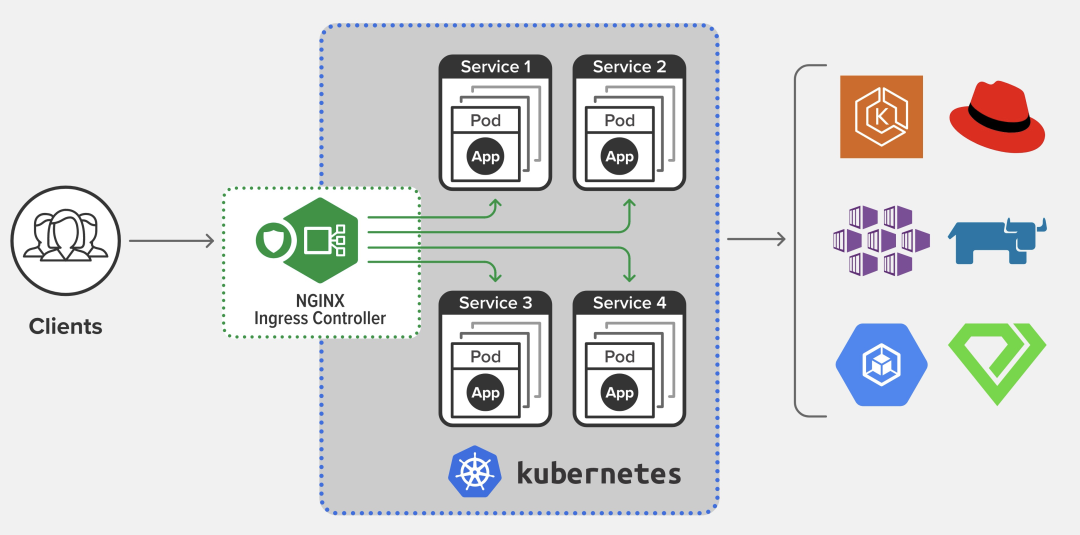
四 总结
参考文献
23、基于 BPF/XDP 实现 K8s Service 负载均衡 (LPC, 2020)https://linuxplumbersconf.org/event/7/contributions/674/
24、A Deep Dive into Iptables and Netfilter Architecture, Justin Ellingwood:https://www.digitalocean.com/community/tutorials/a-deep-dive-into-iptables-and-netfilter-architecture
25、Iptables Tutorial 1.2.2, Oskar Andreasson:https://www.frozentux.net/iptables-tutorial/iptables-tutorial.html
26、Virtual IPs and service proxies, 英文地址:https://kubernetes.io/docs/concepts/services-networking/service/#virtual-ips-and-service-proxies
27、Ingress, 英文地址:https://kubernetes.io/docs/concepts/services-networking/ingress/
28、NGINX Ingress Controller, https://www.nginx.com/products/nginx-ingress-controller/
29、Ingress Controllers, 英文地址:https://kubernetes.io/docs/concepts/services-networking/ingress-controllers/
30、Cracking kubernetes node proxy (aka kube-proxy), [译] 深入理解 Kubernetes 网络模型:自己实现 Kube-Proxy 的功能:https://cloudnative.to/blog/k8s-node-proxy/
虚拟化技术入门
本章主要讲解云计算技术的核心技术之一虚拟化技术,课程首先说明了虚拟化技术的主要作用以及常见实现方法,并针对硬件中常用的虚拟化技术(CPU、内存、IO)进行详细的讲解,最后还针对目前流行的开源虚拟化项目进行说明,讲解其出现的漏洞以及阿里云是怎样完成漏洞分析和处理的。点击阅读原文查看详情!