编辑:袁榭 拉燕
【新智元导读】为了让广大视频通话用户体验更佳,也让更多AR、VR用户青睐元宇宙,Meta的AI研发团队最近开发了能更好处理虚拟背景的AI模型。
自新冠疫情开始以来,大部分人都已经习惯了在和朋友、同事和家人远程视频通话。视频聊天的时候都使用过虚拟背景。
用户在视频时变换背景,能赋予其在虚拟影像中掌控身边环境的权利,减少因环境带来的分心,还能保护隐私,甚至还能让用户在视频里看起来更有精气神。
但有些时候虚拟背景呈现出来的效果可能和用户需求的不一样。大部分人都经历过在移动的时候虚拟背景把人脸挡住了,或者是虚拟背景无法识别手和桌子之间的边界。
最近,Meta利用强化的AI模型来分割图像,优化了背景模糊功能,虚拟背景功能和其它Meta产品服务的AR效果。这样可以更好的分辨照片和视频中的不同部分。
来自Meta AI、现实实验室和Meta其它部门的研究人员和工程师,组成了一个跨部门小组,最近开发了新的图像分割模型,已用在Portal、Messenger和Instagram等很多平台的实时视频通话和Spark AR的增强现实应用中。
该小组还优化了双人图像分割模型,已经在Instagram和Messenger上应用了。
该小组在推进图像分割的优化过程中,主要有以下三大挑战:
1.要让AI学会在不同的环境下也能正常识别。比如说环境偏暗、人物肤色不同、人物肤色接近背景色、人物不常见的体态(比方说弯腰系鞋带,或者伸懒腰)、人物被遮挡、人物在移动等等。
2.要让边缘的位置看起来更加的流畅、稳定、连贯。这些特征在目前的研究中讨论较少,但是用户反馈研究表明,这些因素极大影响人们在使用各类背景效果时的体验。
3.要确保模型能够在全世界几十亿部智能手机中都能灵活、高效的运作。只在一小部分最先进的手机中才能使用是不行的,这类手机往往搭载最新款的处理器。
而且,该模型必须能支持各种长宽比的手机,这样才可以在笔记本电脑、Meta的便携式视频通话设备和人们的手机的肖像模式、横向模式中都保证模型的正常使用。
用Meta的AI模型处理后的虚拟背景示例,左为头身像,右为全身像。
图像分割的概念不难理解,但获得高精确度的个人图像分割结果却很困难。要有好结果的话,处理图像的模型必须一致性极高、延迟度极低。
不正确的分割图像输出,会导致各种让使用虚拟背景的视讯用户走神的效果。更重要的是,图像分割错误会导致用户的真实物理环境发生不必要的暴露。
因为这些,图像分割模型的精度必须达到交并比90%以上,才能进入实际的市场产品应用。交并比是衡量图像分割预测值与基底真实值重叠部分比值的常用标准度量。
由于使用场景与实例复杂度之海量,Meta的图像分割模型要达到的交并比,最后10%完成起来远比之前的所有部分都更难。
Meta的软件工程师们发现,当交并比已达到90%时,图像的可衡量指标趋于饱和,在时间一致性与空间稳定性上难有更好提升。
为了克服此障碍,Meta开发了一个基于视频的衡量系统,与其他几个指标一起来解决这额外的难度。
AI模型只能从已交付的数据集里学习。所以想要训练出高精度的图像分割模型,光是简单录入一大堆视频用户在明亮室内正襟危坐的视频样本是不行的。样本类型得尽可能贴近真实世界地丰富。
Meta AI实验室用了自家的ClusterFit模型,来从不同性别、肤色、年龄、身体姿势、动作、复杂背景、多人数的海量样本中提取可用数据。
静态图像的度量值并不准确反映模型实时处理动态视频的质量,因为实时模型通常要有依赖时间信息的追踪模式。为了测量模型的实时质量,Meta AI实验室设计了当模型预测出画面时、计算每帧画面的各指标的定量性视频评估架构。
与论文中的理想状况不同,Meta的个人图像分割模型是被日常的海量用户评判性能。如果有锯齿、扭曲、或其他不满意的效果出现,其他性能比基准值好出再多也没用。
所以Meta AI实验室直接询问自家产品用户对图像分割效果的评价。结果是边缘不平滑和模糊对用户体验影响最大。
针对此需求,Meta AI实验室在视频评估架构中,另添加了「边缘交并比」这一新指标。当画面的普通交并比超过90%、几近饱和时,边缘交并比就是更需注意的指标了。
而且,画面时间一致性不够,会带来图形边缘的混杂效果,这也会影响用户体验。Meta AI实验室用两种方法来测量画面的时间一致性。
首先,Meta研究人员假设时点紧邻的两帧画面,图像基本一致。所以任何模型上的预测差异都代表最终画面会有时间不一致。
其次,Meta研究人员从时点紧邻的两帧画面的前景动作入手。前景里的光流能让模型从第N帧的预测值推进到第N+1帧。然后研究者就将此预测值与真实的N+1帧数值对照。
这两种方法中测算出的差异度都以交并比这一度量来体现。
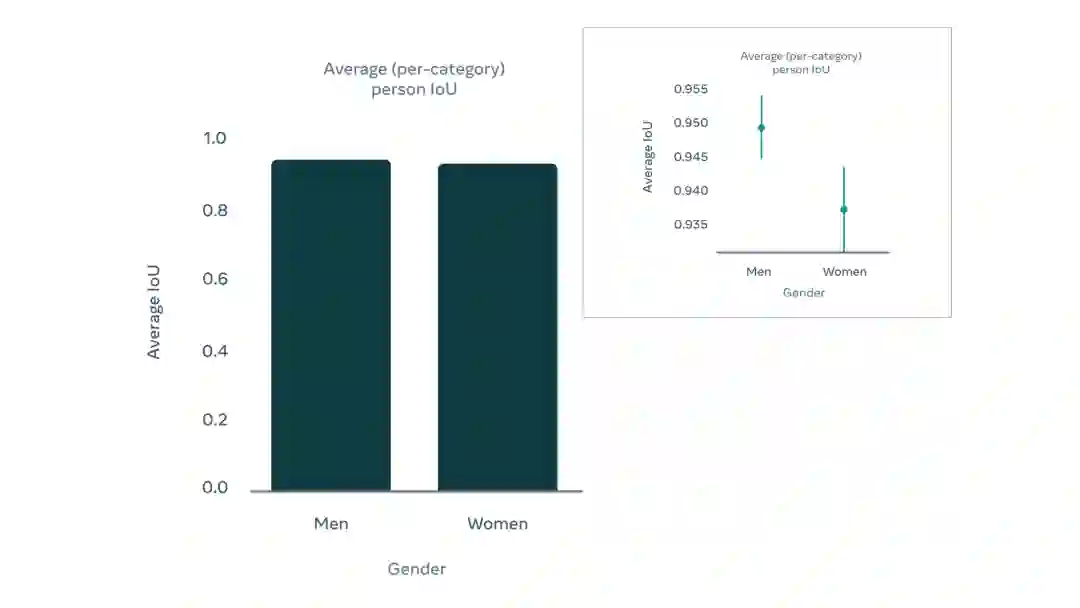
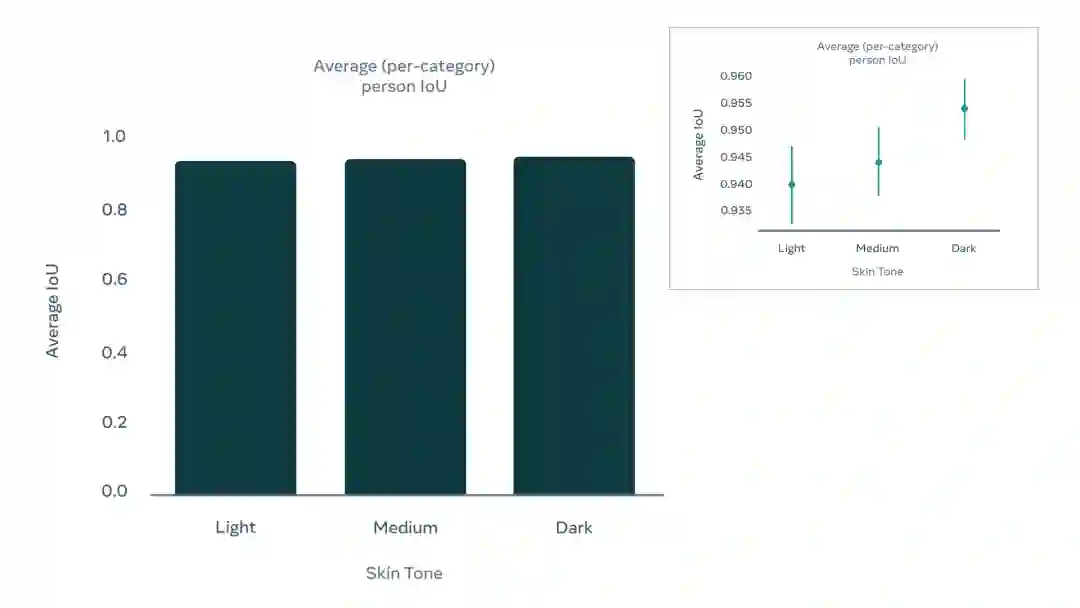
Meta AI实验室使用了来自30种的100余类人群的1100个视频样本来输入AI模型,分类包括所有人类表征性别与菲茨帕特里克量表上的肤色色调。
分析结果是,Meta的AI模型在所有人群子分类的视像处理效果上都有差不多的显著准确性,交并比与置信度都在95%以上,各分类间交并比差异基本都在0.5个百分点左右,性能优异可靠。
不同肤色与性别人群的视频,Meta的AI模型处理后的交并比数据
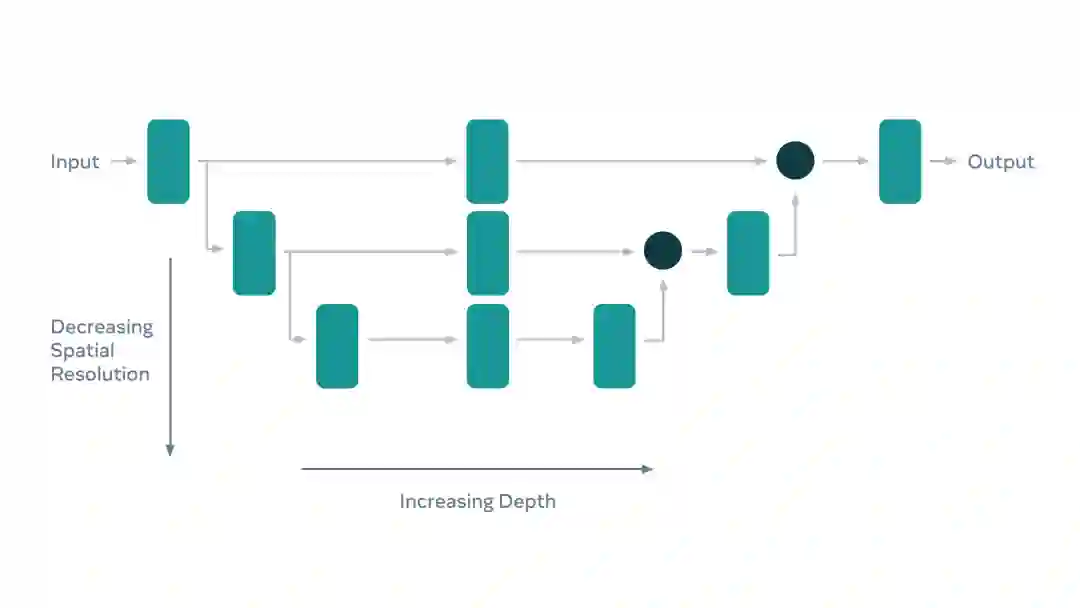
Meta研究人员使用FBNet V3作为优化模型的主干。这是一种由多层混合形成的解编码结构,每一层都有相同的空间分辨率。
研究人员设计了一种配备轻量级解码器加重量级编码器的架构,这样可以拥有比全对称设计的架构更好的性能。生成的架构由神经架构搜索支撑,并对设备上运行的速度进行了高度优化。
语义分割模型架构。绿色的长方形代表卷积层,黑色的圆圈代表各层融合点。
研究人员使用离线大容量的PointRend模型为未注释的数据生成地一个伪标准实值标签,以此来增加训练的数据量。同样地,研究者使用师-生半监督模型来消除伪标签中的偏差。
传统的深度学习模型会将图像重新采样成一个小正方形,输入到神经网络里。由于重新采样,图像会出现畸变。并且由于每帧图像具有不同的长宽比,因此畸变的幅度也会不相同。
畸变的存在、畸变程度的不同,会导致神经网络AI学习到不稳健的低层次特征。这种畸变引起的限制在图像分割应用中会被放大。
如此一来,如果大多数训练图像都是肖像比例,那么该模型在实景图像和视频上的表现要差得多。
为了解决这个问题,研究团队采用了 Detectron 2 的长宽比相关的二次采样方法,该方法将具有相似长宽比的图像分组,并将它们第二次采样到相同的大小。
左为长宽比不调带来畸变的基线图像,右为AI模型处理后的改进图像
长宽比相关的二次采样法需要将具有相似长宽比的图像补边框,但常用的零补框方法会产生伪影(artifact)。
更糟糕的是,当网络的深度不断增加的时候,该伪影会扩散到其他区域。过去的办法是,使用复用边框的手段来移除这些伪影。
最新的一项研究中显示,卷积层中的反射边框可以通过最小化伪影传播的方式来进一步提高模型的质量,但相对应地,时延成本也会增加。伪影的案例,和如何移除伪影的示例如下。
时间不一致,会让AI处理图形时在帧到帧之间存在预测性差异,带来闪烁(flicker),它的出现会极大损害用户的体验。
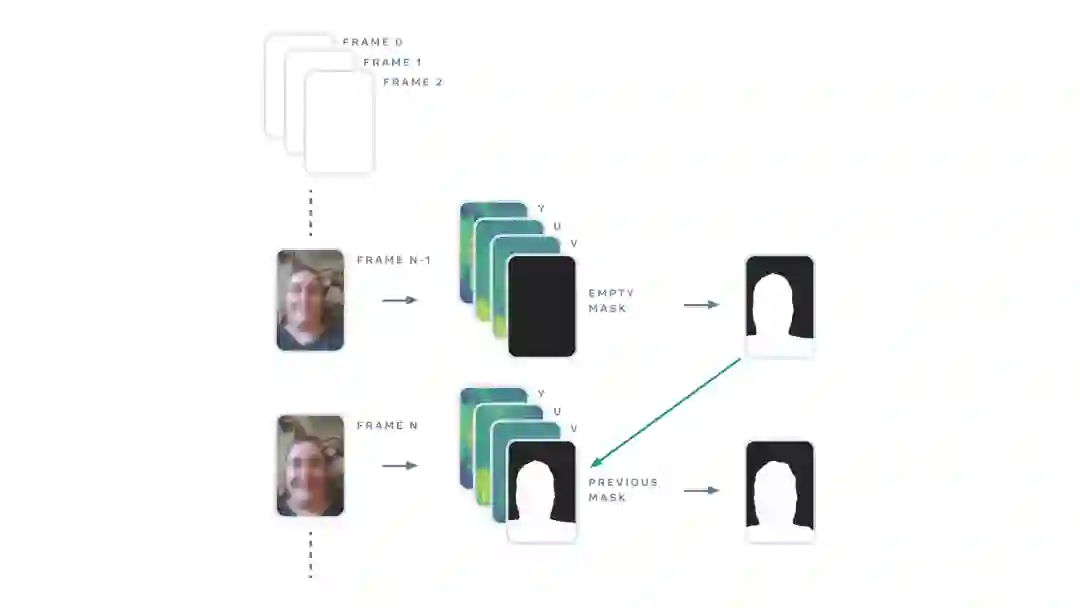
为了提高时间一致性,研究人员设计了一个名为「面具侦测」的检测过程。它从当前帧图像(YUV)中获取三个通道,并且还存在第四通道。
对于第一帧图像,第四通道只是一个空矩阵,而对于随后的帧数,第四通道则是对上一帧的预测。
研究人员发现,这种利用第四通道跟踪的策略显著提高了时间一致性。同时,他们还采用了最先进的跟踪模型中的一些想法,例如CRVOS和变换不变性CNN等建模策略,来获得时间上较为稳定的分割模型。
![]()
构建平滑、清晰的边界,对于AR图像分割的应用至关重要。除了在分割图像的时候会有的标准交叉熵损失之外,研究人员还必须考虑边界加权损失。
研究人员发现,对象的内部是更容易被分割的,所以Unet模型与其之后大多数变体的作者都建议使用三元图加权损失来提升模型的质量。
然而,三元图加权损失有一个限制,就是三元图只会根据标准实值来计算边界区域,因此它对所有的误判都不敏感,是一种非对称的加权损失。
受「边界交并比」的启发,研究人员采用交并比的方法为标准实值和各种预测提取边界区域,并在这些区域中建立交叉熵损失。在边界交叉熵上训练的模型,很明显是优于基准的。
如此除了能使最终掩码输出中的边界区域更清晰之外,应用新方法后,新模型的误报率更低。
![]()
Meta虚拟背景处理器应用的新AI模型,其新功能效率更高、更稳定,也更多样化。这些优化都会提高背景滤镜的质量和连贯性,从而提高在产品中的应用效果。
举例来说,优化过的分割模型可以被用来识别多人场景和人物的全身,也可以识别被沙发、书桌或餐桌遮挡的全身人像。
除去应用在视频通话以外,通过虚拟环境和和现实世界中的人、物结合,这项技术还可以给AR和VR技术增添新的维度。在建设元宇宙、营造沉浸式体验时,这项应用会尤其重要。
参考资料:https://ai.facebook.com/blog/creating-better-virtual-backdrops-for-video-calling-remote-presence-and-ar/
![]()