AAAI 2020 | 计算所:引入评估模块,提升机器翻译流畅度和忠实度(视频解读)

作者 | 谢婉莹
编辑 | Camel
本文是对计算所冯洋组完成,被 AAAI2020 录用的论文《Modeling Fluency and Faithfulness for Diverse Neural Machine Translation》进行解读,相关工作已开源。

论文链接:https://arxiv.org/pdf/1912.00178.pdf 代码链接:https://github.com/ictnlp/DiverseNMT
论文简介:
神经机器翻译模型通常采用Teacher Forcing策略来进行训练,在该策略下,每个源句子都给定一个Ground Truth,在每个时间步翻译模型都被强制生成一个0-1分布,0-1分布将所有的概率分布仅通过Ground Truth词语进行梯度回传,词表中其他的词语均被忽略,从而影响了参数训练。
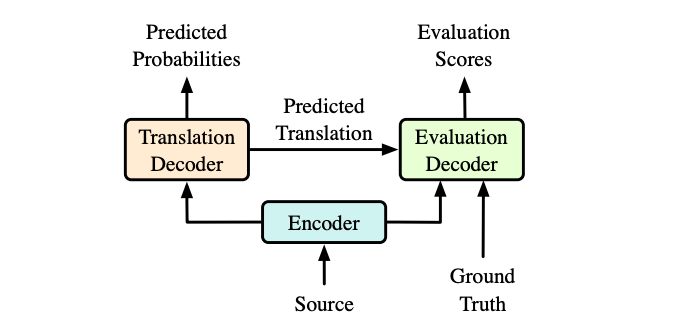
为了解决这个问题,我们提出在神经机器翻译模型中引入一个评估模块,对生成的译文从流利度和忠实度两个方面进行评估,并用得到的评估分数用来指导训练阶段译文的概率分布,而在测试的时候,可以完全抛弃该评估模块,采用传统的Transformer模型进行解码。实验中我们与Transformer模型、强化学习模型以及词袋模型进行了比较,我们的方法在中-英、英-罗马尼亚语言对上相比于所有的基线系统翻译效果均取得了显著提升。
(或者到AI研习社官网观看更多AAAI 2020 论文解读视频:http://www.mooc.ai/open?from=meeting)
文字版解读:计算所冯洋组:引入评估模块,提升机器翻译流畅度和忠实度(已开源)
关注「AI科技评论」微信公众号,后台回复「谢婉莹@AAAI2020」下载讲解 PPT。
作者简介:

谢婉莹,北京语言大学硕士一年级研究生。研究方向为机器翻译,自然语言处理。在北京语言大学取得学士学位,目前在中科院计算所实习。
计算所冯洋研究员也是2019年ACL最佳论文奖的获得者,她领导的实验组继承了刘群教授的衣钵,在机器翻译领域颇有造诣。
更多AAAI 2020信息,将在「AAAI 2020 交流群」中进行,加群方式:添加AI研习社顶会小助手(AIyanxishe2),备注「AAAI」,邀请入群。

AAAI 2020 论文解读系列:
13. [中科院自动化所] 通过解纠缠模型探测语义和语法的大脑表征机制
14. [中科院自动化所] 多模态基准指导的生成式多模态自动文摘
16. [UCSB 王威廉组] 零样本学习,来扩充知识图谱(视频解读)
18. [奥卢大学] 基于 NAS 的 GCN 网络设计(视频解读)
19. [中科大] 智能教育系统中的神经认知诊断,从数据中学习交互函数
30. [东北大学] 基于联合表示的神经机器翻译(视频解读)








