一文读懂目标检测模型(附论文资源)

来源: 大数据文摘
本文共1443字,建议阅读5分钟。
本文为你详细介绍目标检测,并分享资源大礼包,为你的目标检测入门打下基础。
这是一份详细介绍了目标检测的相关经典论文、学习笔记、和代码示例的清单,想要入坑目标检测的同学可以收藏了!
后台回复“目标检测”可打包下载全部论文~
1. R-CNN
R-CNN是2014年出现的。它是将CNN用于对象检测的起源,能够基于丰富的特征层次结构进行目标精确检测和语义分割来源。
如何确定这些边界框的大小和位置呢?R-CNN网络是这样做的:在图像中提出了多个边框,并判断其中的任何一个是否对应着一个具体对象。

要想进一步了解,可以查看以下PPT和笔记:
http://www.image-net.org/challenges/LSVRC/2013/slides/r-cnn-ilsvrc2013-workshop.pdf
http://www.cs.berkeley.edu/~rbg/slides/rcnn-cvpr14-slides.pdf
http://zhangliliang.com/2014/07/23/paper-note-rcnn/
2. Fast R-CNN
2015年,R-CNN的作者Ross Girshick解决了R-CNN训练慢的问题,发明了新的网络Fast R-CNN。主要突破是引入感兴趣区域池化(ROI Pooling),以及将所有模型整合到一个网络中。

你可以通过以下GitHub链接查看模型的各种实现代码:
https://github.com/rbgirshick/fast-rcnn
https://github.com/precedenceguo/mx-rcnn
https://github.com/mahyarnajibi/fast-rcnn-torch
https://github.com/apple2373/chainer-simple-fast-rnn
https://github.com/zplizzi/tensorflow-fast-rcnn
这里还有一个利用对抗学习改进目标检测结果的应用:
http://abhinavsh.info/papers/pdfs/adversarial_object_detection.pdf
https://github.com/xiaolonw/adversarial-frcnn
3. Faster R-CNN
2015年,一个来自微软的团队(任少卿,何恺明,Ross Girshick和孙剑)发现了一种叫做“Faster R-CNN”的网络结构,基于区域建议网络进行实时目标检测,重复利用多个区域建议中相同的CNN结果,几乎把边框生成过程的运算量降为0。
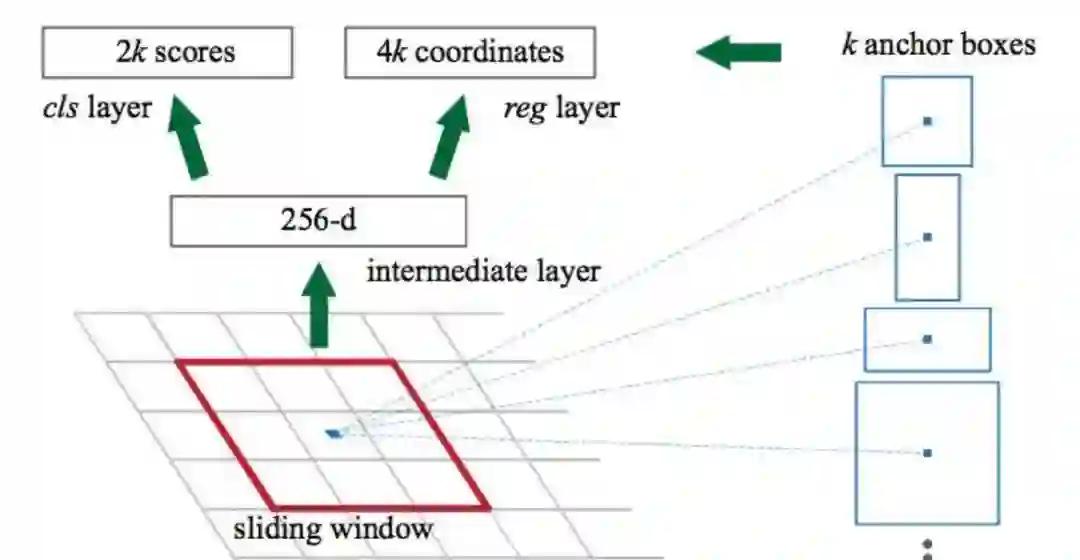
你可以在这里看到关于Faster R-CNN的更多介绍,包括PPT和GitHub代码实现:
http://web.cs.hacettepe.edu.tr/~aykut/classes/spring2016/bil722/slides/w05-FasterR-CNN.pdf
Matlab
https://github.com/ShaoqingRen/faster_rcnn
Caffe
https://github.com/rbgirshick/py-faster-rcnn
MXNet
https://github.com/msracver/Deformable-ConvNets/tree/master/faster_rcnn
PyTorch
https://github.com//jwyang/faster-rcnn.pytorch
TensorFlow
https://github.com/smallcorgi/Faster-RCNN_TF
Keras
https://github.com/yhenon/keras-frcnn
C++
https://github.com/D-X-Y/caffe-faster-rcnn/tree/dev
4. SPP-Net(空间金字塔池化网络)

SPP-Net是基于空间金字塔池化后的深度学习网络进行视觉识别。它和R-CNN的区别是,输入不需要放缩到指定大小,同时增加了一个空间金字塔池化层,每幅图片只需要提取一次特征。
相关资源:
https://github.com/ShaoqingRen/SPP_net
http://zhangliliang.com/2014/09/13/paper-note-sppnet/
更多论文:
DeepID-Net:基于变形深度卷积神经网络进行目标检测
http://www.ee.cuhk.edu.hk/%CB%9Cwlouyang/projects/imagenetDeepId/index.html
深度感知卷积神经网络中的目标检测器
https://www.robots.ox.ac.uk/~vgg/rg/papers/zhou_iclr15.pdf
segDeepM:利用深度神经网络中的分割和语境进行目标检测
https://github.com/YknZhu/segDeepM
基于卷积特征激活图的目标检测网络
http://arxiv.org/abs/1504.06066
利用贝叶斯优化与结构化预测改进基于深度卷积神经网络的目标检测
http://arxiv.org/abs/1504.03293
DeepBox:利用卷积网络学习目标特性
http://arxiv.org/abs/1505.02146
5. YOLO模型
YOLO是指标准化、实时的目标检测。
可以先看大数据文摘翻译的这个视频了解YOLO:
TED演讲 | 计算机是怎样快速看懂图片的:比R-CNN快1000倍的YOLO算法

有了YOLO,不需要一张图像看一千次,来产生检测结果,你只需要看一次,这就是我们为什么把它叫"YOLO"物体探测方法(You only look once)。
代码实现:
https://github.com/pjreddie/darknet
https://github.com/gliese581gg/YOLO_tensorflow
https://github.com/xingwangsfu/caffe-yolo
https://github.com/tommy-qichang/yolo.torch
https://github.com/nilboy/tensorflow-yolo
相关应用:
Darkflow:将darknet转换到tesorflow平台。加载训练好的权值,用tensorflow再次训练,再将导出计算图到C++环境中。
https://github.com/thtrieu/darkflow
使用你自己的数据训练YOLO模型。利用分类标签和自定义的数据进行训练,darknet支持Linux / Windows系统。
https://github.com/Guanghan/darknet

IOS上的YOLO实战:CoreML vs MPSNNGraph,用CoreML和新版MPSNNGraph的API实现小型YOLO。
https://github.com/hollance/YOLO-CoreML-MPSNNGraph
安卓上基于TensorFlow框架运行YOLO模型实现实时目标检测。
https://github.com/natanielruiz/android-yolo
6. YOLOv2模型
时隔一年,YOLO作者放出了v2版本,称为YOLO9000,并直言它“更快、更高、更强”。YOLO v2的主要改进是提高召回率和定位能力。
各种实现:
Keras
https://github.com/allanzelener/YAD2K
PyTorch
https://github.com/longcw/yolo2-pytorch
Tensorflow
https://github.com/hizhangp/yolo_tensorflow
Windows
https://github.com/AlexeyAB/darknet
Caffe
https://github.com/choasUp/caffe-yolo9000
相关应用:
Darknet_scripts是深度学习框架中YOLO模型中darknet的辅助脚本,生成YOLO模型中的参数anchors。
https://github.com/Jumabek/darknet_scripts
Yolo_mark:图形化标记用于训练YOLOv2模型的图像目标
https://github.com/AlexeyAB/Yolo_mark
LightNet:改进的DarkNet
https://github.com//explosion/lightnet
用于生成YOLOv2模型所需训练数据的边界框标记工具
https://github.com/Cartucho/yolo-boundingbox-labeler-GUI
Loss Rank Mining:基于实时目标检测的一种通用的困难样本挖掘方法。LRM是第一个高度适用于YOLOv2模型中的困难样本挖掘策略,它让YOLOv2模型能够更好的应用到对实时与准确率要求较高的场景中。
https://arxiv.org/abs/1804.04606
7. YOLOv3模型
再次改进YOLO模型。提供多尺度预测和更好的基础分类网络。相关实现:
https://pjreddie.com/darknet/yolo/
https://github.com/pjreddie/darknet
https://github.com/experiencor/keras-yolo3
https://github.com/marvis/pytorch-yolo3
8. SSD(单网络目标检测框架)
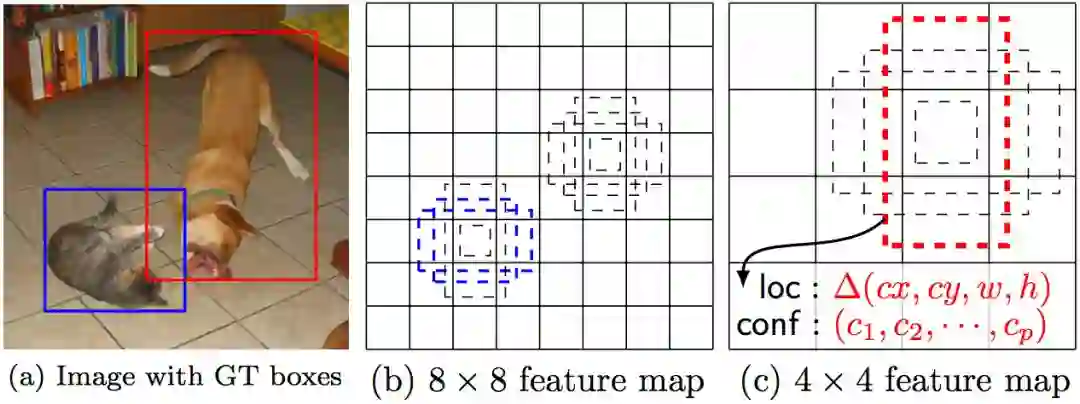
SSD可以说是YOLO和Faster R-Cnn两者的优势结合。相比于Faster R-Cnn,SSD的目标检测速度显著提高,精度也有一定提升;相比YOLO,速度接近,但精度更高。
相关实现:
https://github.com/zhreshold/mxnet-ssd
https://github.com/rykov8/ssd_keras
https://github.com/balancap/SSD-Tensorflow
https://github.com/amdegroot/ssd.pytorch
https://github.com/chuanqi305/MobileNet-SSD
9. DSOD(深度监督目标检测方法)
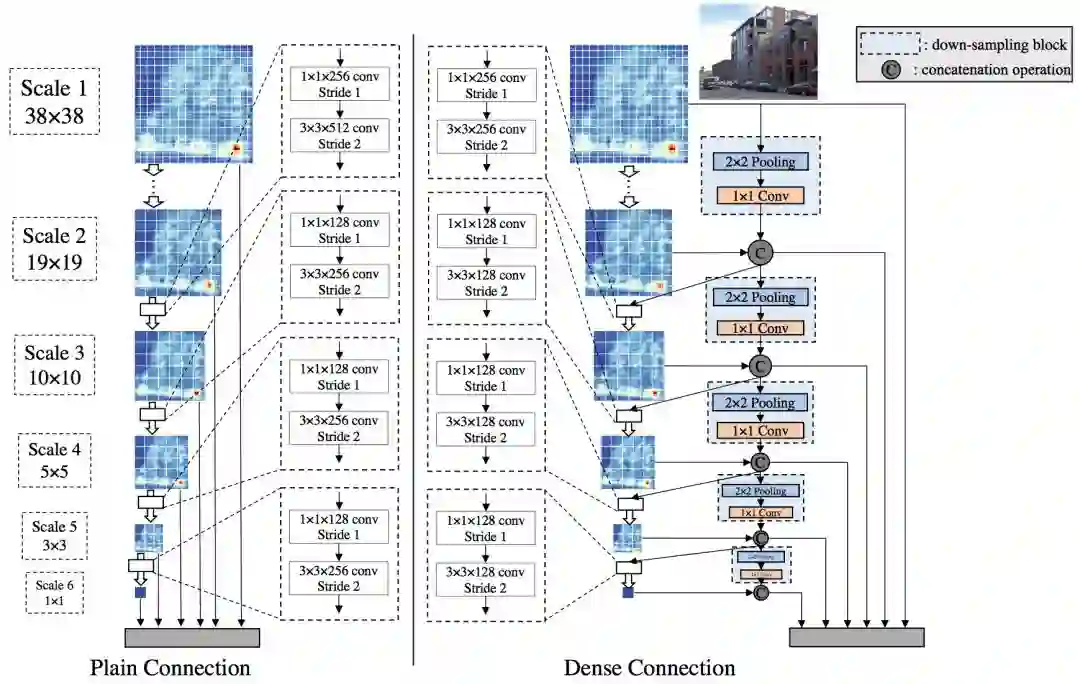
与SSD类似,是一个多尺度不需要proposal的检测框架,是一种完全脱离预训练模型的深度监督目标检测方法。
相关实现:
https://arxiv.org/abs/1708.01241
https://github.com/szq0214/DSOD
https://github.com/Windaway/DSOD-Tensorflow
https://github.com/chenyuntc/dsod.pytorch
后台回复“目标检测”可打包下载全部论文~
更多更全面的目标检测资源链接可以前往GitHub查看:
https://github.com/amusi/awesome-object-detection




