7篇ICLR论文,遍览联邦学习最新研究进展
机器之心分析师网络
作者:仵冀颖
编辑:H4O
本篇提前看重点关注 ICLR 2020 中关于联邦学习(Federated Learning)的最新研究进展。

Fair Resource Allocation in Federated Learning
Differentially Private Meta-Learning
DBA: Distributed Backdoor Attacks against Federated Learning
Generative Models for Effective ML on Private, Decentralized Datasets
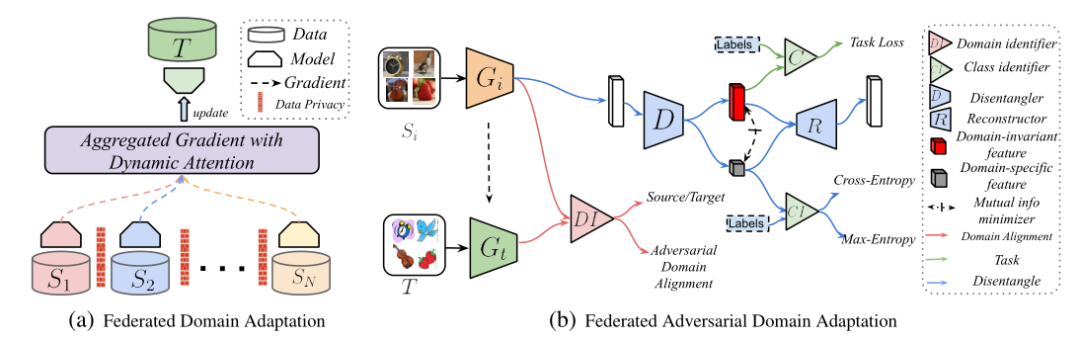
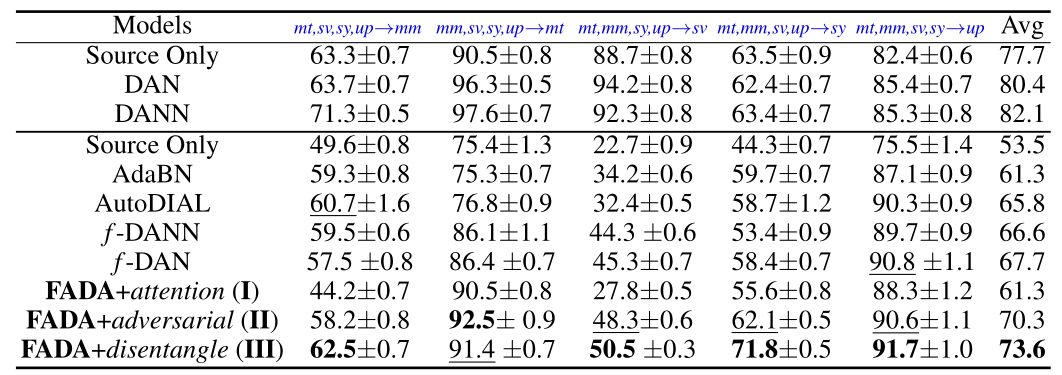
Federated Adversarial Domain Adaptation
On the Convergence of FedAvg on Non-IID Data
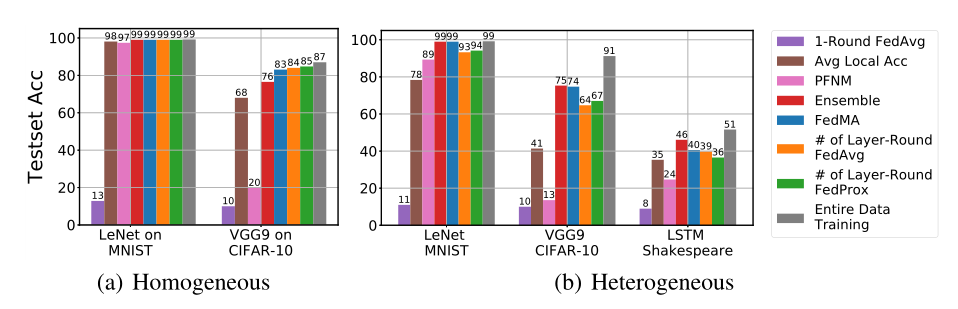
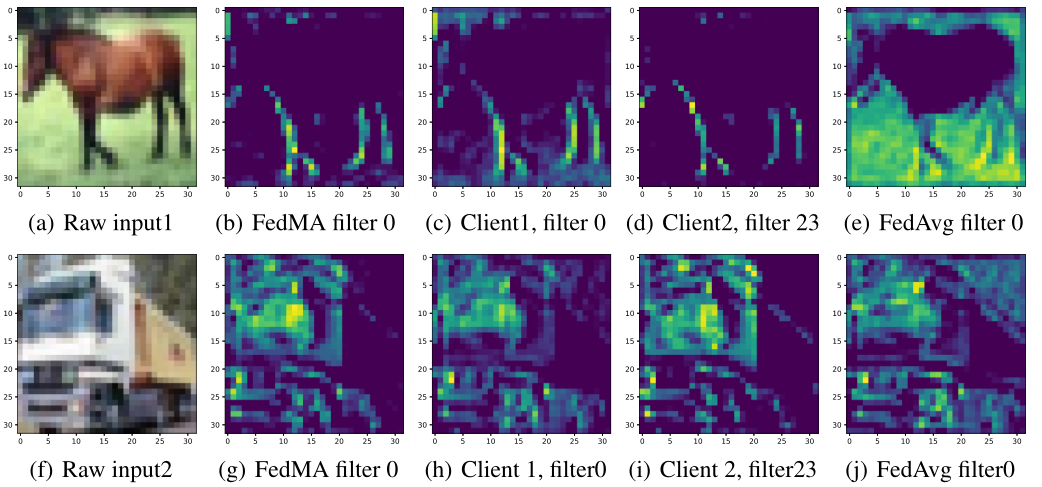
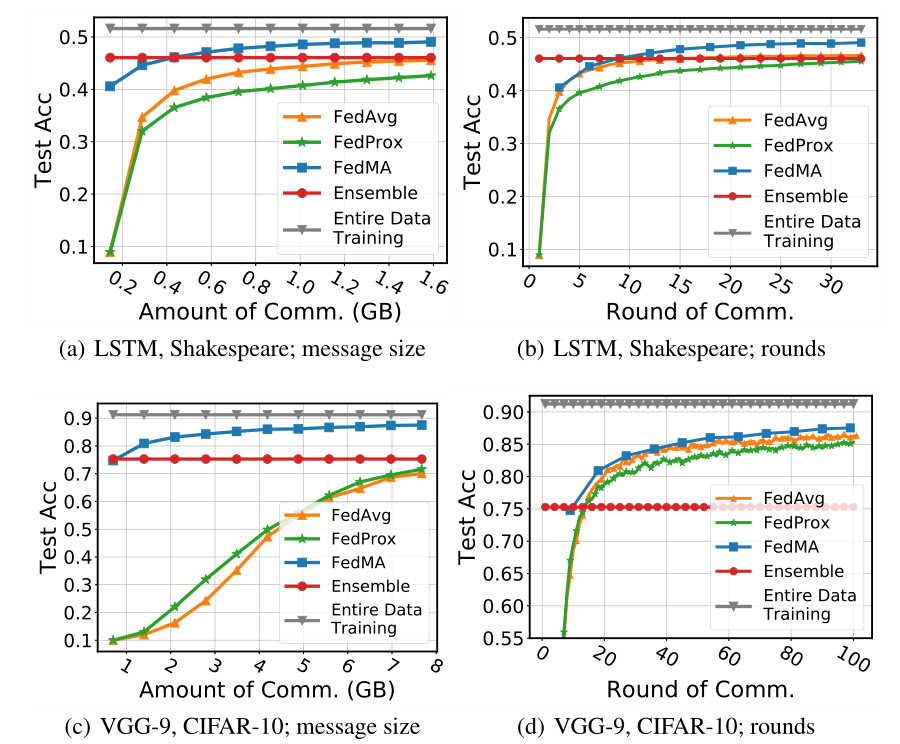
Federated Learning with Matched Averaging

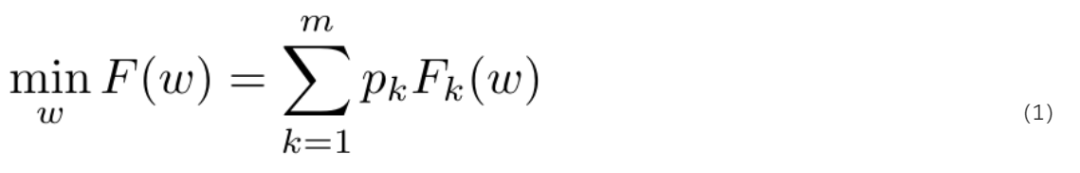
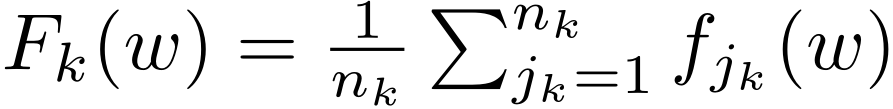

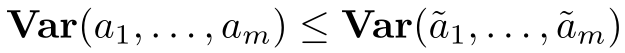
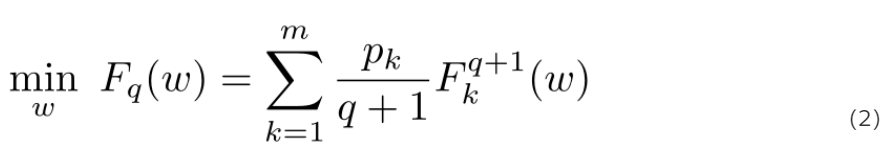




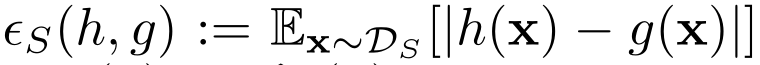
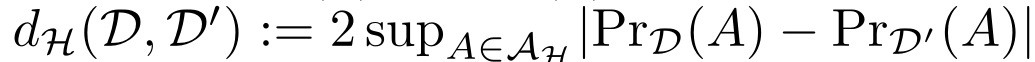
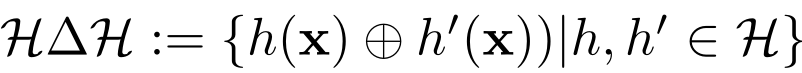
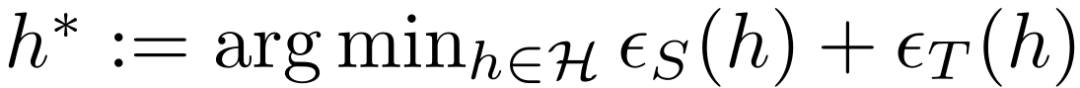
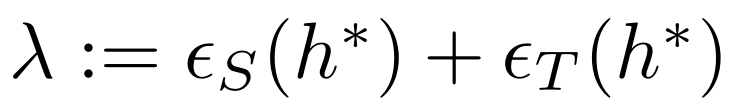
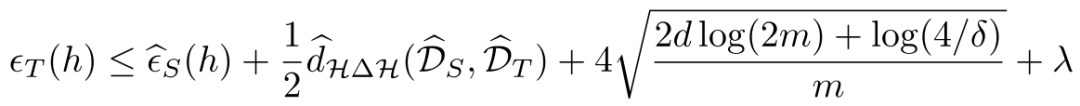
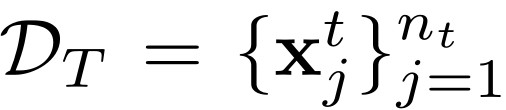
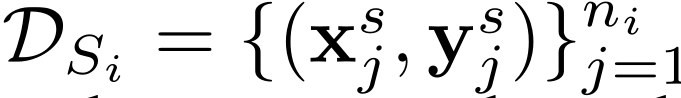
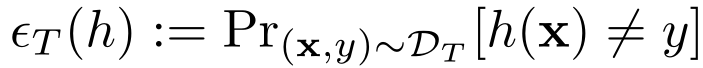
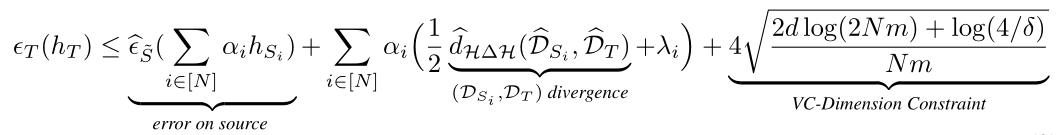
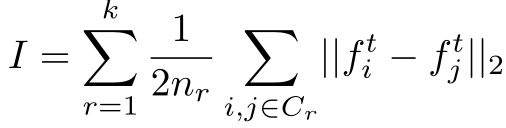
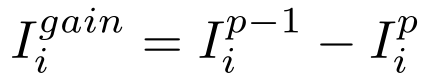
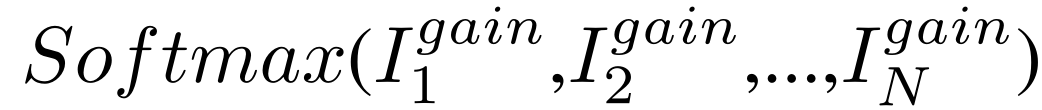
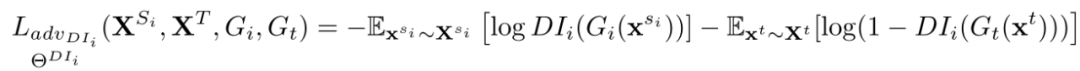
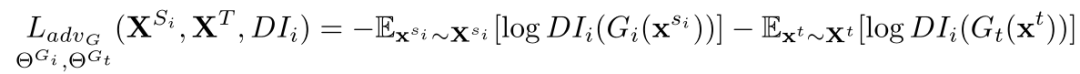
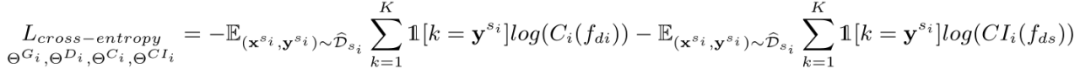
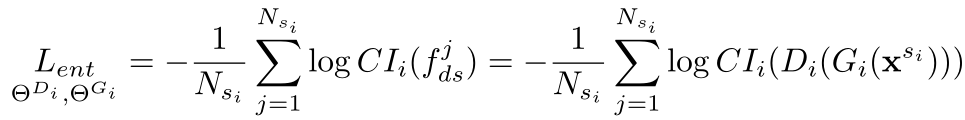
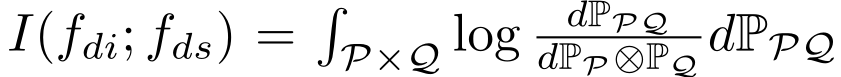
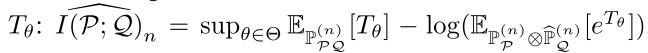
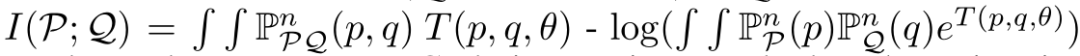
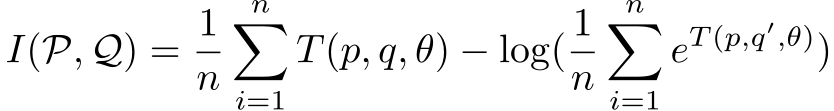

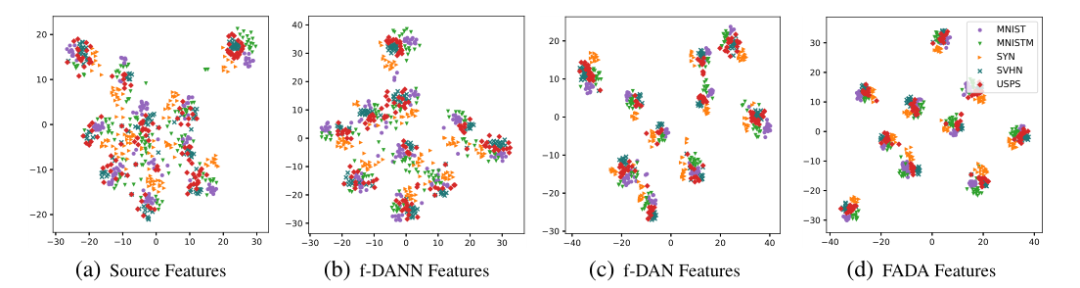
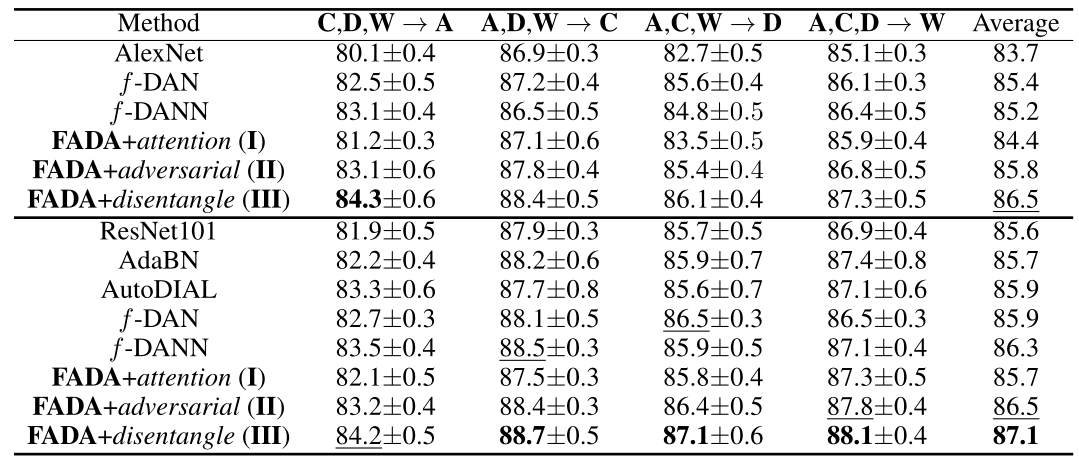
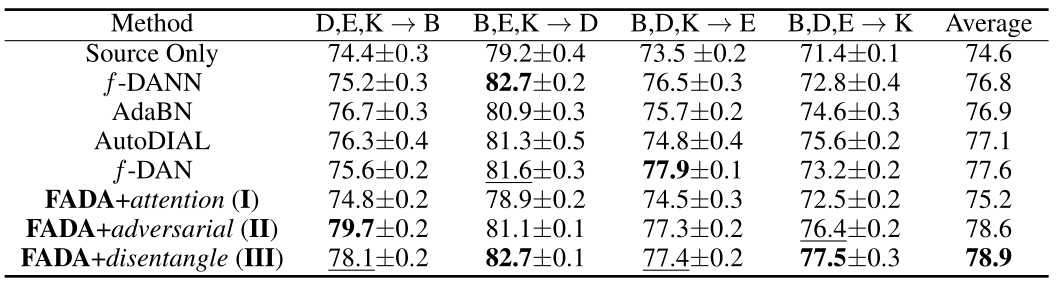


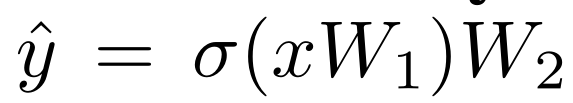
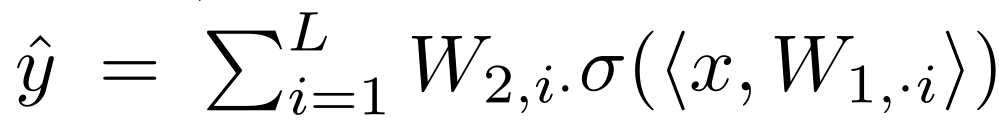
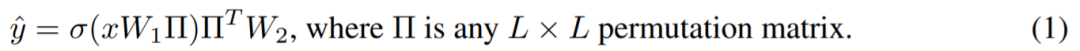
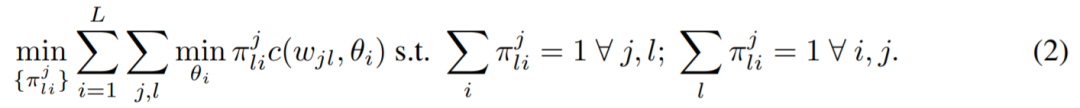
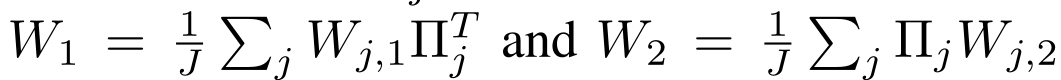

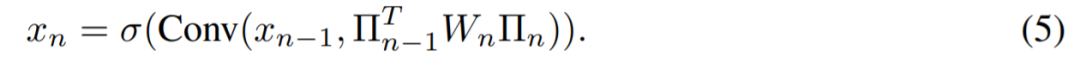
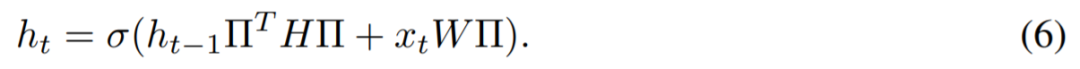

登录查看更多
相关内容

专知会员服务
79+阅读 · 2020年3月19日
Arxiv
11+阅读 · 2020年2月18日
Arxiv
4+阅读 · 2018年4月23日


相关VIP内容
专知会员服务
79+阅读 · 2020年3月19日
相关资讯
相关论文
Arxiv
11+阅读 · 2020年2月18日
Arxiv
4+阅读 · 2018年4月23日