近900000条if-then关系图谱,让神经网络“懂”常识推理
本文授权转载自AI科技大本营(微信ID:rgznai100)
“神经网络能学习日常事件的常识推理吗?能,如果在 ATOMIC 上训练的话。”
ATOMIC(原子) 是一个机器常识图集,一个用自然语言建立的 870, 000 个 if-then 关系的图谱。这一项目的研究者是来自华盛顿大学艾伦人工智能研究所的学者,近日,他们在 AAAI 2019 上对外公开了这一研究项目并发表了论文。
与 9 种 if-then 关系关联的 ATOMIC
根据论文摘要介绍,与以分类学知识为中心的现有资源相比,ATOMIC 关注的是被组织为 if-then 关系的推理知识(例如,“如果 X 给 Y 给与赞美,则 Y 可能会回赞”)。他们提出了 9 种 if-then 关系类型来区分原因 vs.效果,代理 vs. 主题,自愿 vs.非自愿事件,以及行为 vs. 心理状态。
通过对 ATOMIC 中描述的丰富的推理知识进行生成式训练,他们证明了神经模型可以获得简单的常识能力,并推理以前无法预见的事件。实验结果表明,与通过自动和人工评估测量的单独训练模型相比,结合 if-then 关系类型层次结构的多任务模型会有更准确的推理结果。
如果给出对一个事件的快速观察情况,在一个观察事件中,人们可以轻松地预测和推理的相关未观察到的原因(causes)和影响(effects):之前可能发生的事情,接下来可能发生的事情以及不同事件如何通过原因和影响进行链接。
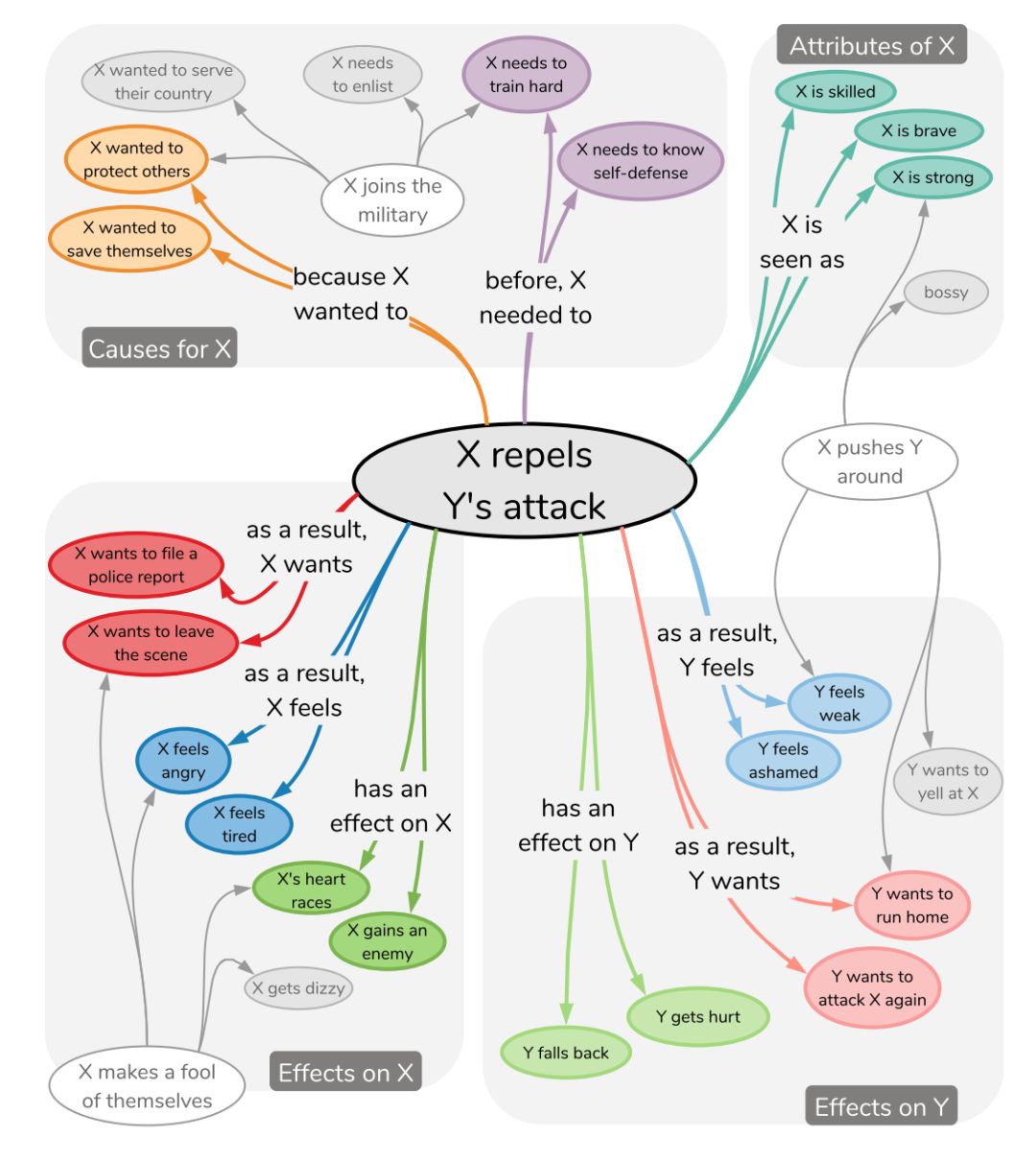
如上图所示,这是 ATOMIC 的一个小子集,是日常事件、原因和结果的机器常识图谱。如果我们观察“X 击退 Y 的攻击”事件,可以立即推断出围绕该事件的各种可信事实。就事件背后的合理动机而言,X 可能是想要保护自己。至于事件发生前合理的前提条件则是,X 可能已经有自卫训练能力来成功抵御 Y 的攻击。我们还可以推断出 X 的合理特征:她可能很强壮、技术娴熟且勇敢。对于这一事件的结果,X 可能会感到愤怒并可能想要报警;另一方面,Y 可能会害怕被抓住并想逃跑。
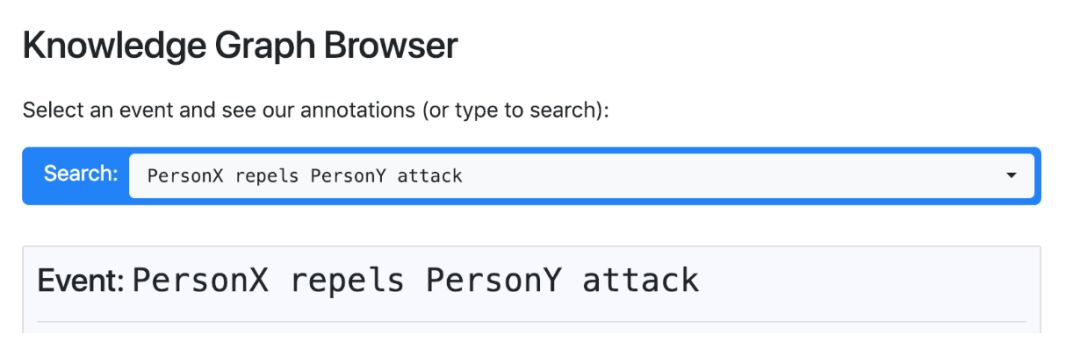
在官网上,研究者给出了一个关于该项目的知识图谱浏览器,可以选择一个事件并查看相关注释。
上面的例子说明如何通过密集连接的推理知识来实现日常的常识推理。正是通过这种知识,我们可以观看一部两小时的电影,并了解一个跨越几个月的故事,因为可以推断出大量的事件、原因和影响。
此外, ATOMIC 还能使我们能够发展关于他人的心智理论(Theories of Mind)。虽然这种能力对于人类而言是普遍而微不足道的,但却是当今人工智能系统所缺乏的。部分原因是绝大多数人工智能系统都针对特定任务的数据集和目标进行了训练,从而使模型能够有效地找到任务特定的相关模式,但缺乏简单且可解释的常识推理。
ATOMIC 如何收集事件中的常识?
既然 ATOMIC 专注于 if-then 的知识推理,他们的研究目标是创建一个满足三个要求的知识库:规模、覆盖范围和质量。因此,他们专注于众包实验而不是从语料库中提取常识,因为后者受到语言中明显的报告偏差影响,这会挑战所提取知识的覆盖范围和质量。
他们的众包框架以对简单问题的自由文本回答的形式收集注释,从而实现大规模、高质量的收集关于事件的常识。
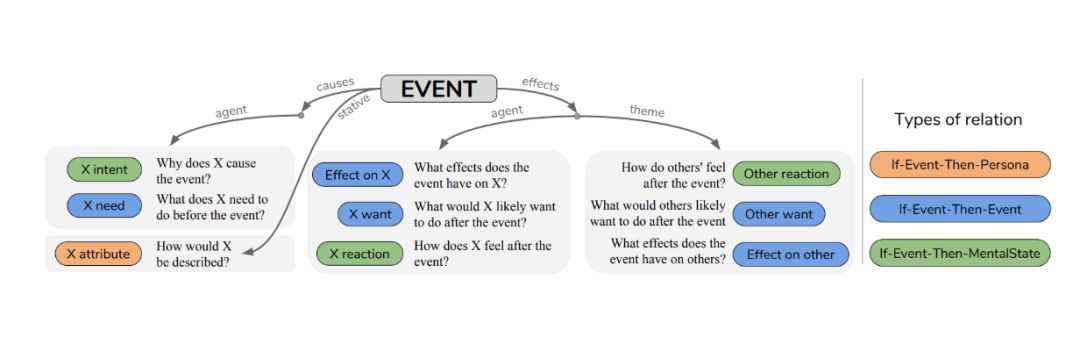
我们提出了 if-then 推理类型的新分类法 ,对该类型进行分类的一种方法是基于预测内容:(1)If-Event-Then-Mental-State,(2)If-Event-Then-Event,以及(3)If-Event-Then-Persona。另一种分类方法是基于它们的因果关系:(1)“原因(causes)”,(2)“影响(effects)”,(3)“稳定(stative)”。使用这种分类法,他们收集了超过 877K 的推理知识实例。
然后,他们研究了神经网络模型,通过嵌入 Atomic 中描述的丰富的推论知识,可以获得简单的常识能力并推理以前无法预见的事件,以便用自然语言生成它们可能发生的原因和影响。
常见疑问
某些事件的注释是多种多样的,这是否意味着数据是杂乱的?
重要的是,有些事件引发了高度选择性的常识预期(commonsense anticipations),而其他事件则引发了更多样化的预期。关于这种不同程度的不确定性的知识(即在不同推理上的相对宽泛的分布),这是我们常识知识中很自然且重要的一部分。因此,对于某些事件,看到不同的注释是没问题的。
ML 模型(如神经网络)可以从潜在的多样化注释中进行学习吗?
当然! 这与为什么可以训练“语言模型”的原因相同。尽管语言变化很大,但有可能将语言中的可归纳模式作为概率模型进行学习。我们将常识视为随机建模的问题。
协议级别是什么?
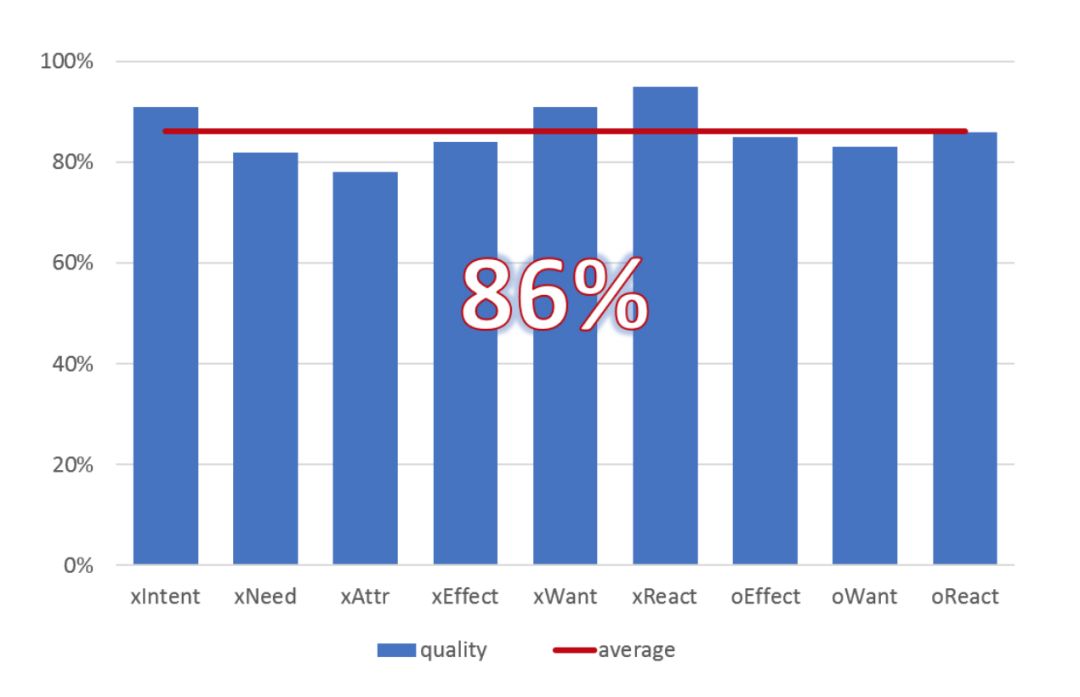
为了阐明所有维度的数据质量,我们对 100 个事件的随机子集进行了单独的数据质量验证研究,要求五个 MTurkers(众包平台上的众包工人) 根据事件和维度验证单个注释是否正确。我们发现,平均而言,注释在86% 的时间内都有效,每个维度的研究如上图所示。
数据下载:
https://homes.cs.washington.edu/~msap/atomic/data/atomic_data.tgz
论文链接:
https://homes.cs.washington.edu/~msap/atomic/data/sap2019atomic.pdf


推荐阅读
基础 | TreeLSTM Sentiment Classification
原创 | Simple Recurrent Unit For Sentence Classification
原创 | Attention Modeling for Targeted Sentiment
 欢迎关注交流
欢迎关注交流


