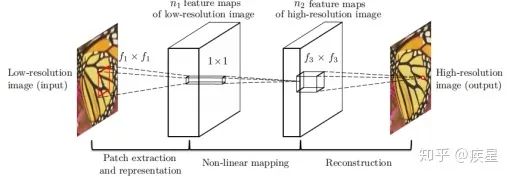
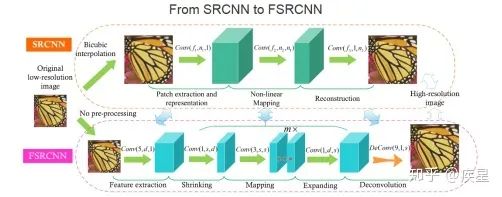
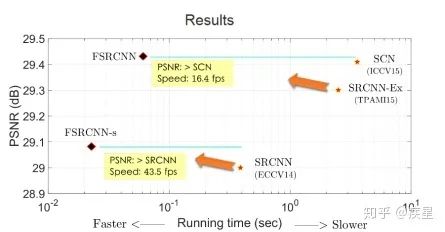
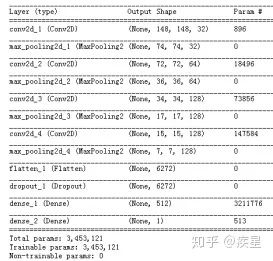
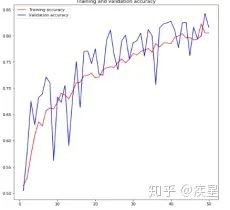
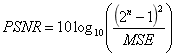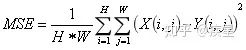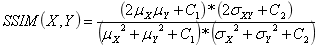本文第一部分介绍了深度学习领域中图像处理的常用技巧,主要包括数据增强、图像去噪以及图像增强领域中的图像高分辨率重建技术(SR,Super Resolution)。数据增强能根据原始图像生成内容、风格相似的更多训练图像,可有效解决因训练图像不足带来的曲线过拟合;图像去噪技术的代表是常见的高斯滤波算法和去噪神经网络,其共同特征是有效过滤图片传输中受到的干扰波动,有利于后续的图像处理;图像高分辨率重建是图像增强领域的显著代表,其基本思想是通过提取原始低分辨率图片的特征,变换映射得到高分辨率图片。这种技术不仅完整保留了原始图片的内容和风格(图像的有效信息),也提升了变换后的图片质量。
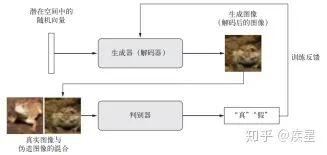
本文第二部分简要分析深度学习技术在图像处理领域的主要应用,按照不同功能划分为图像变换、图像识别和图像生成三个领域。图像变换是图像处理最简单、基本的操作;图像识别是计算机视觉的重要分支研究领域,目的是达到深度学习图像识别网络识别精度和效率的提升,实际应用于人脸识别和遥感图像识别等方面;最后概述了图像生成应用的几个分支:包括神经风格迁移(NST,Neural Style Transfer)和变分自编码器(VAE,Variational autoencode)等。Deep Dream可以看做训练集为Image Net的神经风格迁移网络,它们的共同特点是:从参考图像中进行内容和风格的提取组合后,根据要求生成不同种类的目标图片。图像生成领域的另一个重要分支为生成式对抗网络(GAN,Generative adversarial network),可以生成与原始图像非常相似的目标图像,感兴趣的读者可以自行了解。
图像处理领域是深度学习和机器视觉领域重要的研究分支,相信在未来必将得到蓬勃的发展。本文涉及的图像和代码可在
https://github.com/asbfighting/-.git中下载和访问。
参考文献:[1](美)Francois Chollet著,python深度学习[M],张亮译,北京;人民邮电出版社,2018.8[2] 候宜军著,Keras深度学习实战[M],北京;北京图灵文化发展公司,2017,6[3]Dong, C., Loy, C.C., He, K., Tang, X.: Learning a deep convolutional network for image super-resolution. In: ECCV. (2014) 184–199[4] Aharon, M., Elad, M., Bruckstein, A.: K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. TSP 54(11), 4311–4322 (2006)[5] Burger, H.C., Schuler, C.J., Harmeling, S.: Image denoising: Can plain neural networks compete with BM3D? In: CVPR. pp. 2392–2399 (2012)[6] Freedman, G., Fattal, R.: Image and video upscaling from local self-examples. TOG 30(2), 12 (2011)[7] Yang, J., Lin, Z., Cohen, S.: Fast image super-resolution based on in-place example regression. In: CVPR. pp. 1059–1066 (2013)[8] Dong, C., Loy, C.C., He, K., Tang, X.:Accelerating the Super-Resolution Convolutional Neural (https://Network.In) ECCV.(2016)[9] Dong, C., Loy, C.C., He, K., Tang, X.: Image super-resolution using deep convolutional networks. TPAMI 38(2) (2015) 295–307[10] Yang, C.Y., Yang, M.H.: Fast direct super-resolution by simple functions. In: ICCV. (2013) 561–568[11] Timofte, R., De Smet, V., Van Gool, L.: Anchored neighborhood regression for fast example based super-resolution. In: ICCV. (2013) 1920–1927[12] Gatys L A , Ecker A S , Bethge M . A Neural Algorithm of Artistic Style[J]. Computer Science, 2015.[13] Rezende D J , Mohamed S , Wierstra D . Stochastic Backpropagation and Approximate Inference in Deep Generative Models[J]. 2014.[14] Kingma D P , Welling M . Auto-Encoding Variational Bayes[J]. 2013.