论文浅尝 - EMNLP2020 | 基于分组式对比学习的神经对话生成
论文笔记整理:叶宏彬,浙江大学计算机博士生。

论文地址:https://arxiv.org/abs/2009.07543
摘要:近年来,神经对话问答的产生已广受欢迎。现有对话模型学习中广泛采用了最大似然估计目标(MLE)。但是,当涉及到开放域对话设置时,使用MLE目标函数训练的模型会受到低多样性问题的困扰。人类不仅可以从积极的信号中学习,而且还可以从纠正不良行为的行为中受益,在这项工作中,我们将对比性学习引入了对话生成中,其中模型明确地感知了精心选择的积极与消极之间的差异话语。具体来说,我们采用预先训练的基线模型作为参考。在对比学习期间,与参考模型相比,训练了目标对话模型以提供正样本的较高条件概率和那些负样本的较低条件概率。为了管理人类对话中普遍存在的多重映射关系,我们通过分组对偶采样来增强对比对话学习。大量的实验结果表明,所提出的基于组的对比学习框架适合于训练大量的神经对话生成模型,其性能优于基线训练方法。
动机
在本文中,我们将对比学习引入对话生成,其中模型明确地感知到选择好的正面和负面话语之间的差异。从对比学习的角度来看,对抗学习中的判别器将人类产生的反应视为正面话语,将合成反应视为负面话语。相反,这项工作将高度匹配的上下文响应对视为正样本,将不匹配的训练对视为负样本。特别是,我们利用预训练的基线模型作为参考。在对比学习期间,对于上下文c及其响应r,训练了目标对话模型,与参考模型相比,对正样本给出了更高的条件概率p(r | c),对负样本给出了更低的条件概率。如图1所示对于给定的训练实例,所提出的框架通过鼓励对话生成模型将匹配的样本对拉在一起并将不匹配的对在潜在空间中分开,从而明确考虑了人类对话中的多重映射关系。此外,从一对正样本和负样本中学习是非常简单的,但是,多映射关系在人与人之间的对话中占主导地位,在这种对话中,对于给定的上下文存在多个适当的响应,并且有时这种响应非常适合多个上下文,称为一对多和多对一的关系。这种复杂的多重映射关系在以前的学习框架中被忽略,这妨碍了有效的对话响应学习。如果将潜在高度匹配的对话对视为阴性样本,或者将离群值用作阳性样本,则可能会混淆模型。因此,为了考虑人类对话中的多重映射现象并纠正潜在的有问题的虚假学习样本,并提高训练的稳定性,我们通过分组对偶抽样来增强对比学习,其中对正负实例进行抽样 分别是上下文和响应。为了进一步描述组中实例之间的细微差异,我们使用匹配分数调整实例重要性,并优化加权损失。
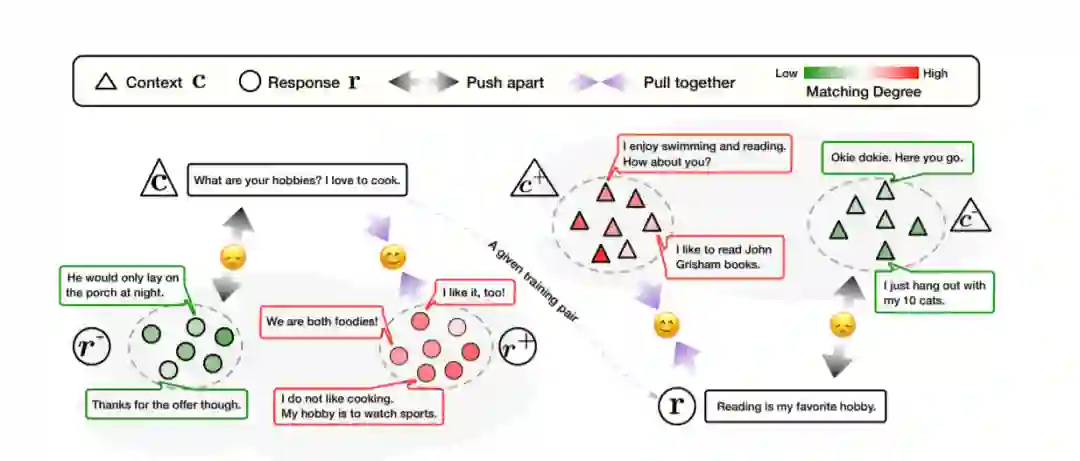
图1:分组对比学习的示意图
损失函数改进
给定包含上下文响应对,由θ参数化的对话模型旨在将输入上下文c映射到输出响应r。为了实现这一点,传统的对话学习方法通过使训练样本上的条件概率pθ(r | c)最大化来搜索参数θ。
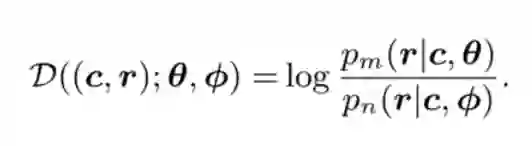
假如按以往基于正负对的对话学习做法,我们将以下损失函数最小化:
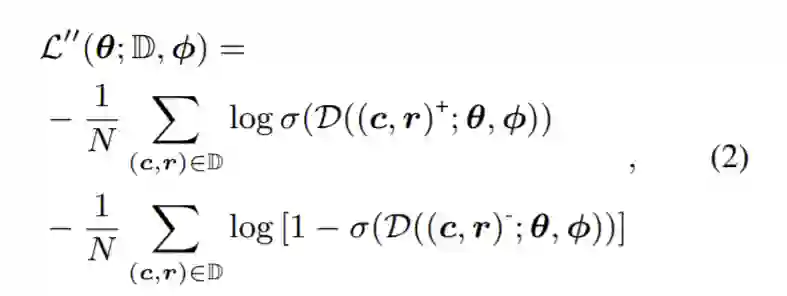
然而,在人类对话中存在多重映射关系的情况下,在对话中对正负对进行有效采样并不是那么简单,甚至存在引入错误学习样本的风险。为了处理人类对话中复杂的多重映射现象并提高训练稳定性,我们通过分组双重抽样来增强对比学习,其中分组抽样的正例和负例分别针对上下文和响应。如图2所示,对于每个训练对,它首先使用现成的会话匹配模型对一组高度匹配的示例进行采样,并对另一组与上下文和响应有关的最不匹配的话语进行采样,以建立对比示例。然后使用分组对比学习训练目标对话模型。
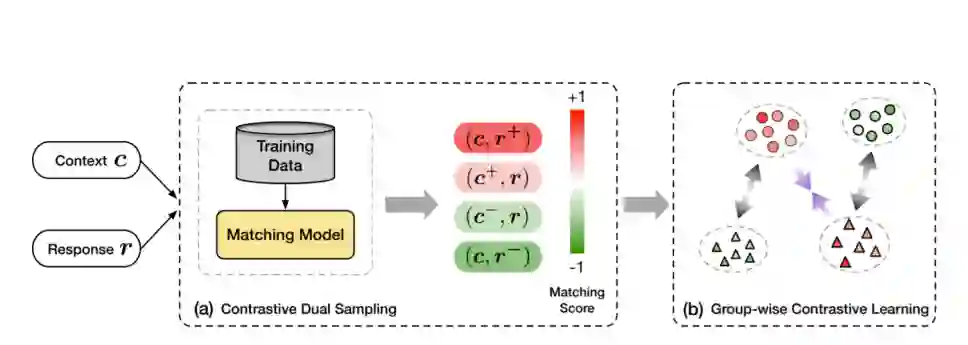
图2:分组式对比对话学习管道的演示
基于对比学习的损失函数更新为:
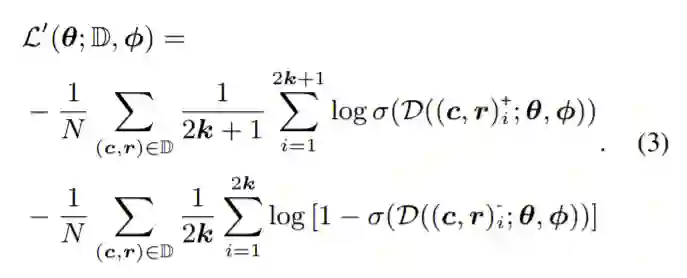
给定在开放域对话中收集的上下文响应对的匹配程度不同,对此类数据进行不加区分的训练会阻止模型感知这些样本的组内差异。因此,我们利用每个样本所附的匹配分数s来调整其实例效果对分组式对比对话学习的影响。
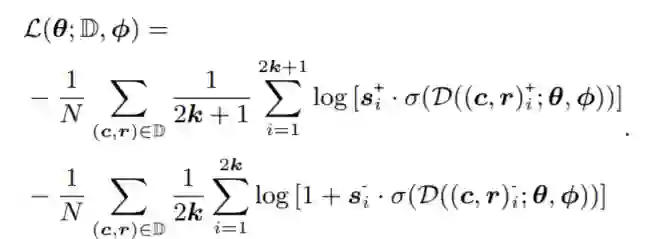
实验
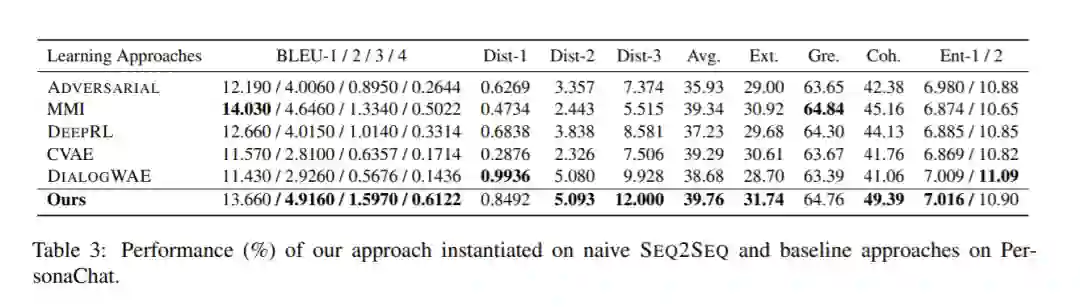
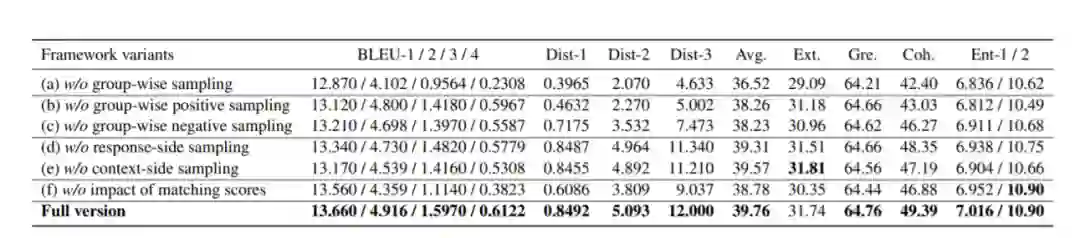
作者在三个数据集上进行了实验。PersonaChat是一种英语数据集,包含通过Amazon Mechanical Turk收集的成对说话者之间的多轮对话。Douban包含来自受欢迎的社交网络服务-中国豆瓣小组的日常对话。OpenSubtitles包含从英语电影字幕转换而来的人与人之间的对话。基线模型和消蚀实验均证明了分组式对比学习方法在对话问答生成领域的有效性。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 网站。



