MIT华人助理教授新作:加快神经网络设计自动化的步伐
新智元报道
来源:news.mit.edu
作者:Rob Matheson 编辑:肖琴
【新智元导读】MIT韩松等人团队开发了一种高效的神经结构搜索算法,可以为在特定硬件上自动设计快速运行的神经网络提供一个“按钮型”解决方案,算法设计和优化的机器学习模型比传统方法快200倍。
使用算法自动设计神经网络是人工智能的一个新领域,而且算法设计的系统比人类工程师开发的系统更准确、更高效。
但是这种所谓的神经结构搜索 (NAS) 技术在计算上非常昂贵。
谷歌最近开发的最先进的NAS算法,它可以在一组 GPU 上运行,需要 48000 小时来生成一个用于图像分类和检测任务的卷积神经网络。当然了,谷歌拥有并行运行数百个GPU 和其他专用硬件的资金实力,但这对其他大部分人来说是遥不可及的。
在 5 月份即将举行的 ICLR 会议发表的一篇论文中,MIT 的研究人员描述了一种 NAS 算法,仅需 200 小时,可以专为目标硬件平台 (当在大规模图像数据集上运行时) 直接学习卷积神经网络。这可以使这类算法得到更广泛的使用。

论文:ProxylessNAS: 在目标任务和硬件上直接搜索神经架构
地址:https://arxiv.org/pdf/1812.00332.pdf
研究人员表示,资源匮乏的研究人员和企业可以从节省时间和成本的算法中受益。论文作者之一、MIT 电子工程与计算机科学助理教授、微系统技术实验室研究员韩松 (Song Han) 表示,他们的总体目标是 “AI 民主化”。

MIT 电子工程与计算机科学助理教授韩松
他说:“我们希望通过在特定硬件上快速运行的一个’按钮型’(push-button)的解决方案,让 AI 专家和非专家都能够高效地设计神经网络架构。”
韩松补充说,这样的NAS算法永远不会取代人类工程师。“目的是减轻设计和改进神经网络架构所带来的重复和繁琐的工作,” 他说。他的团队中的两位研究人员 Han Cai 和Ligeng Zhu 参与了论文。
在他们的工作中,研究人员开发了一些方法来删除不必要的神经网络设计组件,以缩短计算时间,并仅使用一小部分硬件内存来运行 NAS 算法。另一项创新确保每个输出的CNN 在特定的硬件平台 (CPU、GPU 和移动设备) 上运行得比传统方法更高效。在测试中,研究人员用手机测得 CNN 运行速度是传统方法的 1.8 倍,准确度与之相当。
CNN 的架构由可调参的计算层 (称为 “过滤器”) 和过滤器之间可能的连接组成。过滤器处理正方形网格形式的图像像素,如 3x3、5x5 或 7x7,每个过滤器覆盖一个正方形。过滤器基本上是在图像上移动的,并将其覆盖的像素网格的所有颜色合并成单个像素。不同的层可能具有不同大小的过滤器,并以不同的方式连接以共享数据。输出是一个压缩图像 —— 来自所有过滤器的组合信息 —— 因此可以更容易地由计算机进行分析。
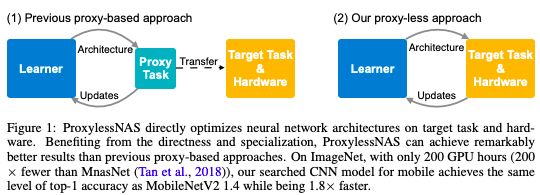
由于可供选择的架构的数量 —— 称为 “搜索空间”—— 是如此之大,因此应用 NAS 在大型图像数据集上创建神经网络在计算上是令人望而却步的。工程师们通常在较小的proxy 数据集上运行 NAS,并将它们学到的 CNN 架构转移到目标任务。然而,这种泛化方法降低了模型的精度。此外,相同的输出架构也适用于所有硬件平台,这造成了效率问题。
研究人员直接在 ImageNet 数据集中的一个图像分类任务上训练并测试了他们的新 NAS算法。他们首先创建了一个搜索空间,其中包含所有可能的 CNN 候选 “路径”(paths)—— 即层和过滤器连接以处理数据的方式。这使得 NAS 算法可以自由地找到最优的架构。
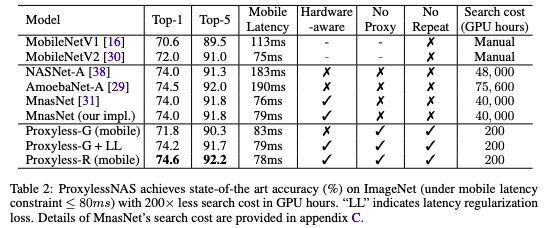
ProxylessNAS在ImageNet上达到最高精度,且搜索成本的GPU hours减少了200倍
通常,这意味着所有可能的路径都必须存储在内存中,这将超过 GPU 的内存限制。为了解决这个问题,研究人员利用了一种称为 “路径级二值化”(path-level binarization)的技术,这种技术一次只存储一个采样路径,并节省了一个数量级的内存消耗。他们将这种二值化与 “path-level pruning” 相结合,后者是一种传统的技术,可以在不影响输出的情况下学习删除神经网络中的哪些 “神经元”。然而,他们提出的新 NAS 算法并不是丢弃神经元,而是修剪了整个路径,这完全改变了神经网络的结构。
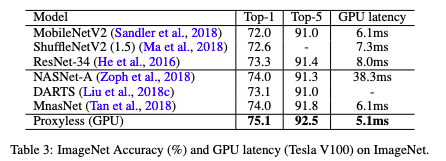
ImageNet上精度和延迟的结果
在训练中,所有路径最初都被赋予相同的选择概率。然后,该算法跟踪路径 —— 一次只存储一个路径 —— 以记录输出的准确性和损失 (对错误预测的数字惩罚)。然后,它调整路径的概率,以优化精度和效率。最后,该算法修剪掉所有低概率路径,只保留了概率最高的路径 —— 这就是最终的 CNN 架构。
韩松表示,该研究另一个关键的创新是使 NAS 算法具备 “硬件感知”(hardware-aware),这意味着它将每个硬件平台上的延迟作为反馈信号来优化架构。
例如,为了测量移动设备上的延迟,Google 这样的大公司会使用大量的移动设备,这是非常昂贵的。相反,研究人员构建了一个模型,只使用一部手机就能预测延迟。
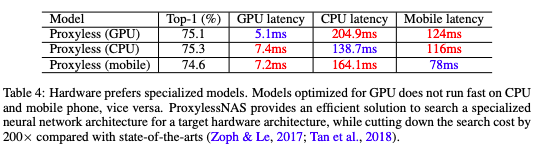
不同硬件的延迟结果
对于网络的每个所选层,算法都对该延迟预测模型的架构进行采样。然后,使用这些信息来设计一个尽可能快地运行的架构,同时实现高精度。在实验中,研究人员的 CNN在移动设备上的运行速度几乎是标准模型的两倍。
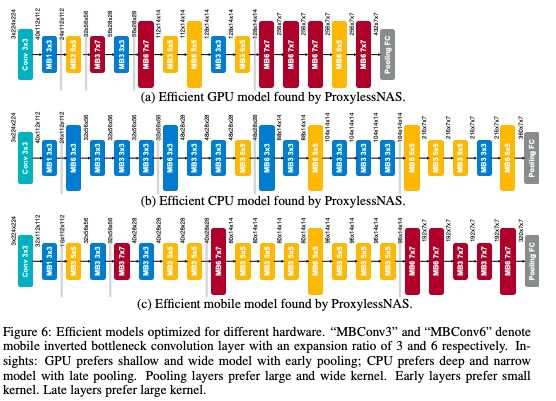
针对不同硬件优化的高效模型
韩松说,一个有趣的结果是,他们的 NAS 算法设计的 CNN 架构长期以来被认为效率太低,但在研究人员的测试中,它们实际上针对特定的硬件进行了优化。
例如,工程师基本上已经停止使用 7x7 过滤器,因为它们的计算成本比多个更小的过滤器更昂贵。然而,研究人员的 NAS 算法发现,具有部分 7x7 过滤器层的架构在 GPU 上运行得最快。这是因为 GPU 具有高并行性 —— 意味着它们可以同时进行许多计算 —— 所以一次处理一个大过滤器比一次处理多个小过滤器效率更高。
“这与人类以前的思维方式背道而驰,” 韩松说。“搜索空间越大,你能找到的未知事物就越多。你不知道是否会有比过去的人类经验更好的选择。那就让 AI 来解决吧。”
原文:
http://news.mit.edu/2019/convolutional-neural-network-automation-0321
论文地址:
https://arxiv.org/pdf/1812.00332.pdf
更多阅读
【2019新智元 AI 技术峰会精彩回顾】
2019年的3月27日,新智元再汇AI之力,在北京泰富酒店举办AI开年盛典——2019新智元AI技术峰会。峰会以“智能云•芯世界“为主题,聚焦智能云和AI芯片的发展,重塑未来AI世界格局。
同时,新智元将在峰会现场权威发布若干AI白皮书,聚焦产业链的创新活跃,评述AI独角兽影响力,助力中国在世界级的AI竞争中实现超越。
现场精彩回顾:
爱奇艺(全天):
https://live.iqiyi.com/s/19rsj6q75j.html
头条科技(上午):
m.365yg.com/i6672243313506044680/
头条科技(下午):
m.365yg.com/i6672570058826550030/




