「如何跳出鞍点?」NeurIPS 2018优化相关论文提前看
机器之心原创
作者:Joshua Chou
编辑:Haojin Yang
编译:Geek AI
作者介绍:
Joshua Chou 毕业于多伦多大学,目前从事信息论与编码论的相关研究,主要研究内容为格码 (Lattice Codes) 与低密度奇偶检查码 (Low Density Parity Check Codes) 的演算法,以及它们在通讯系统中的应用。其他感兴趣的研究领域包括凸优化 (Convex Optimization) 以及随机规划 (Stochastic Programming)。
对优化的爱好让我很自然地接触到机器学习 (Machine Learning) 领域。我喜欢针对机器学习的演算法,用一个优化的架构去思考,去理解机器学习问题。
我觉得研究机器学习的乐趣不只是在于机器终究能够达成的应用,而是在当你遇到一个问题时,如何想像 (visualize) 这个问题,如何去规划 (formulate) 这个问题,然后用什么演算法去解決 (solve) 这个问题,如何解读演算法的每一个细节、每一个参数。当你深入地了解了问题与演算法的时候,你会发现看上去再复杂的问题都有一个简单易懂的解释。我觉得,当你能够了解演算法的每一步时,解决问题就像在说一场故事一样,特别有条理,非常有趣。因此对于今年 NeurIPS 的文章,我找了几篇关于优化细节的论文推荐给各位。
论文列表
Escaping Saddle Points in Constrained Optimization
Third-order Smoothness Helps: Even Faster Stochastic Optimization Algorithms for Finding Local Minima
SEGA: Variance Reduction via Gradient Sketching
论文 1:Escaping Saddle Points in Constrained Optimization
论文链接:https://arxiv.org/abs/1809.02162
你为什么需要读这篇文章?
简而言之,如果你对研究跳出局部最小值的问题很感兴趣,那么你很有必要阅读一下这篇文章。
Choromanska 等人在 2015 年发表的研究表明,随着问题维度的增加,局部最小值之间的损失的方差会减小。这意味着在局部最小值点产生的损失与在全局最小值点产生的损失类似。
然而,由于优化算法可能陷入鞍点无法跳出,我们并不总是能很轻易地得到局部最小值。本文介绍了一种避开鞍点的方法,该方法具有较高的发生损失,有望更快地收敛到局部最小值。一旦我们达到(近似的)局部最小值,我们就可以安全地使用 Choromanska 发现的结论,并将我们的解作为一个充分解。
因此,我们需要解决的问题是「如何避开鞍点,从而得到一个局部最小值」?
预备知识
本文关注的问题可以被形式化定义如下:
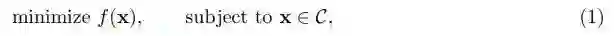
其中,f 是在一个凸集上平滑的非凸函数,x∈R^d,C 是一个封闭的凸集,而实数集上的 f:R^d 是 C 上的一个二次连续函数。
无约束优化问题的最优性条件通常包括一阶必要条件(FONC),其中对于所有的 x 有 f(*x*) 的梯度 =0,以及二阶充分条件 (SOSC),其中 FONC 在某个 x*点成立,且在 x* 点的 Hessian 二阶导数矩阵是正半定的。
对于带约束的优化问题,局部最小值具有如下所示的特性:
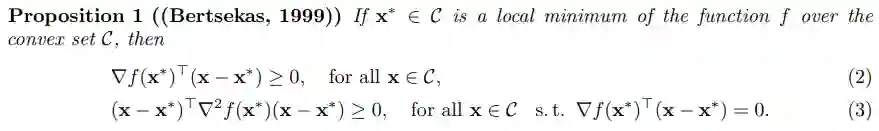
条件(2)和(3)分别为「一阶必要条件」和「二阶充分条件」。下面的定义对于读者阅读这篇文章也会很有帮助。
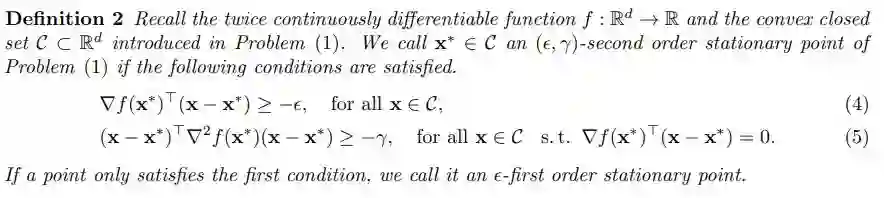
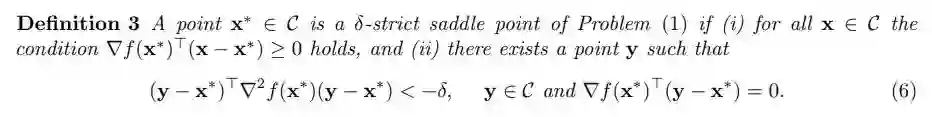
在高维空间中,鞍点控制着损失表面(详情见 Choromanska et al.,2015)。因此,我们的目标是避免算法陷入鞍点,并找到一个(ε,γ)二阶驻点(SOSP),即满足(4)和(5)的 x*。反过来,一个(ε,γ)二阶驻点(SOSP),将接近一个局部最小值,因此它是一个充分解。
下图直观地描述了鞍点和局部最小值之间的区别。
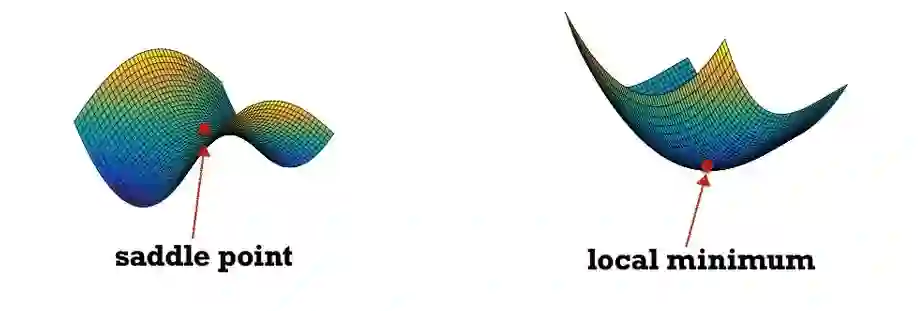
如图所示,当算法处于一个鞍点时,存在一些潜在的方向,当算法沿着这样的方向继续往下「走」(进行梯度下降)时,可以到达损失更小的点。
本文主要的贡献
本文的主要成果是得到了凸集 C 上的非凸函数 f 的一个(ε,γ)二阶驻点(SOSP)的框架。具体而言,本文着重研究了这种形式的二次规划(QP)方法:
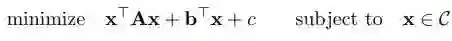
其中,A∈R^d 是一个对称矩阵,b∈R^d 是一个向量,而 c 是一个标量。在这里,假设有一个可行解 x*,和一个属于 (0,1] 常数因子 ρ,作者将问题的解定义如下:
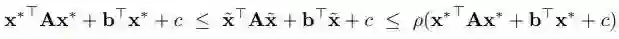
提出的解决方案包括两个步骤。
在第一步中,算法使用一阶更新来查找 ε 一阶驻点(FOSP)。ε 一阶驻点是一个满足条件(4)的点 x*,在第二步中,如果它是一个鞍点,算法利用 f 的二阶信息跳出该驻点。
该算法如下所示,我们接下来将更仔细地研究每个步骤。

一阶步骤:收敛到一阶驻点
作者提出了两种不同的方法来完成这个步骤,一种是使用条件梯度更新规则,另一种是使用投影梯度更新规则。在这里,我将详细解释投影梯度下降 (PGD) 方法。
在这种环境下,PGD 的目的是到达驻点 x^,以使能够到达 x^ 的迭代过程始终在可行解集内。
PGD 的方法可以通过一个例子来理解。我们现在重点关注(1)中的优化问题,其中,我们在凸集 C 上有一个二次规划约束问题(目标函数是变量的二次函数,约束条件是变量的线性不等式),我们将其约束定义为:Mx = y。
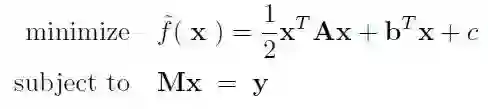
其中 A∈R^(d*d) 以及 M∈R^(p*d)。PGD 背后的思想是,消除等式约束 Mx = y(它定义了凸集 C),从而得到一个无约束的优化问题。首先,我们需要找到一个矩阵 F∈R^(d*(d-p)) 和用参数表示的仿射向量 x^d(因此为凸集),可行解集如下:
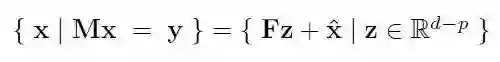
在这里,我们可以选择 Mx=y 的任意一个特解作为 x^,而 F 则是值域在 M 的零空间中的任意矩阵。因此(1)中的问题可以被归结为:
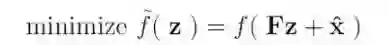
这是一个无约束问题其中变量 z∈R^(d-p)。通过该问题的解 z*,我们可以找到 f 的解为 x*=Fz*+x^。
PGD 得到的结果和出发点是,从可行解集中的某个点 x^ 开始,采取基于梯度方法的运算步骤,其运算结果仍然在这个可行解集中。这样的方法可以通过一个事实得以验证,那就是当 F 为一个 M 的零空间中的一个矩阵时,我们有 M (Fz + x^) = 0 + y = y,而且 x^ 是 Mx=y 的一个特解。
算法 1 将根据一阶更新来更新决策变量 x,直到到达满足条件(4)的点 x_t,即
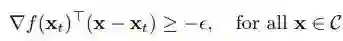
二阶步骤:跳出鞍点
此时,算法 1 已经到达了一个 ε 一阶驻点。现在我们的目标是,如果它是一个局部极大值或一个严格鞍点,我们将使用目标函数 f 的二阶信息来跳出当前的驻点。要做到这一点,我们必须在满足 ▽ f(x_t)(u - x_t) = 0 的切线空间中找到一个可行解 u∈C,使内积 (u - x_t)^T ▽^2 f(x_t) (u - x_t) 小于 -γ。如果存在这样一个点 u,这意味着方向(u- x_t)是梯度下降的方向,我们的算法可以从当前的驻点离开。这是通过解决下面的优化问题来实现的。
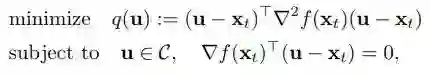
接下来这一步的目的是将上述问题转化为一个容易解决的问题。作者在这里给出了一个例子,如果 C 被构造地很好,上述优化问题可以转化为二次约束二次规划(QCQP)。这样,我们就可以利用标准的凸优化技术来解决这个问题。
本文给出的例子是,当 C 被定义为以原点为中心的 m 个椭球的交点时,即
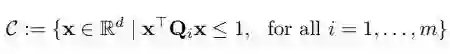
其中,每个 Q_i 是一个 d 维的对称矩阵。因此,该问题可以被重新写作:
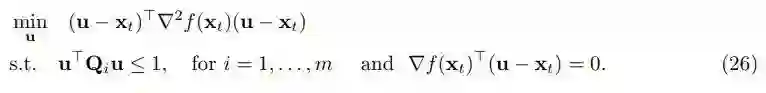
将约束(26)变换为一个二次约束二次规划问题的方法如下。我们需要找到为切线空间找到一个基。首先, 我们可以使用如下形式的 Gramm-Schmidt 过程为 R^d 找到一个基。
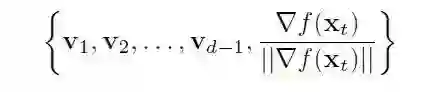
接下来,通过定义下面的矩阵
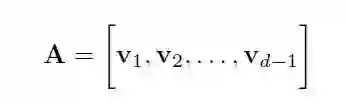
任意满足▽ f(x_t)=0 的向量 z 可以被写作 z=Ay,其中 y=(u-x_t)∈R^(d-1)。因此,(26)中的优化问题可以被写作如下形式:
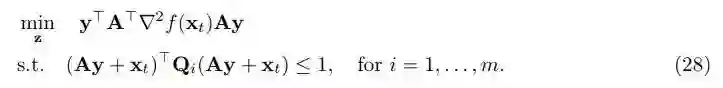
这一步所得的结果(28)是一个众所周知的问题,可以使用标准的优化技术来解决。从(26)到(28)的转换背后的思路是:由于切线方向▽ f(x_t)∈R^d,我们可以让它作为 R^d 的一个基向量。剩下的 A 的列构成的基向量形成了向量空间 R^(d-1),他们都正交于切线方向。通过在 A 的列空间中搜索向量,即,z = Ay,这样可以保证得到满足约束▽ f(x_t)(u - x_t) = 0 的解。
作者指出,即使 x _ t ▽ ^ 2 f(x_t)x_t 是非正的,即▽ ^ 2 f(x_ t ) 不是半正定的,我们仍然可以找到问题(28)的 ρ 的近似解,从而解决问题(26)。最后,从第二阶段返回的解决方案将是一个(ε,γ)二阶驻点(SOSP)。
结论
本文着重关注优化的一些非常实用的问题,即如何跳出鞍点。例如,在神经网络中进行优化时,多层架构中误差表面的统计特性已经显示出鞍点占据的优势。因此,本文提供了如何潜在地克服鞍点的深刻见解。
一个潜在的后续工作是探索具有不同目标函数或约束的优化问题。看看这种方法是否可以进一步推广将会十分有趣。我认为挑战在于一个问题能否转化为一个构造地很好的优化问题,即是否可以将原问题转化为一个众所周知的问题,如线性规划、二次规划、半定规划等。如果可以的化,我们就可以应用本文提出的方法,达到一个满足(松弛后的)最优条件的驻点。
现在,我们已经知道了在非线性优化问题中跳出鞍点的一种方法,那么如何才能更快地跳出鞍点呢?接下来的这篇论文将讨论这个问题。
论文 2:Third-order Smoothness Helps: Even Faster Stochastic Optimization Algorithms for Finding Local Minima
论文链接:https://arxiv.org/abs/1712.06585
你为什么需要读这篇文章?
简单的答案仍然是,如果你对找到局部最小值感兴趣,那么你有必要阅读一下这篇文章。
Bray 和 Dean(2007)的早先理论分析表明,在高维连续空间上存在随机高斯误差函数临界点的某种结构。它们表明,误差远高于全局最小值的临界点极有可能是具有许多负的和近似的平稳方向的鞍点,而所有的局部最小值,极有可能具有非常接近全局最小值的误差。
如前所述,Choromanska et al.(2015)的实证研究证实了,随着问题维度的增加,不同局部最小值处损失的方差会减小。从本质上说,最好和最坏的解之间的「差距」缩小了,所有的局部最小值的情况最终都差不多。
因此,这个问题就变成了:我们如何达到局部最小值而不陷入鞍点?如果我们被陷入鞍点,我们怎么才能跳出鞍点呢?
预备知识
本文的目标是利用目标函数的三阶平滑度来避开鞍点。感兴趣的读者应该已经熟悉平滑和三阶导数的定义。以下定义直接取自本文:
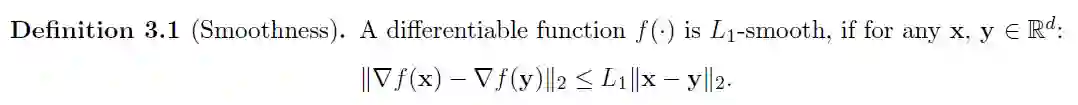
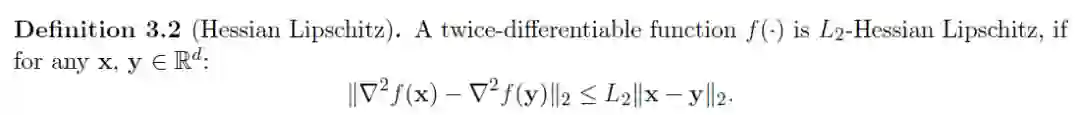
正如上面所示的定义,Lipschitz 常数 L1 和 L2 分别取决于▽ f(x) 和 ▽ ^2 f(x)。因此,这些常数可能对于一个函数来说很小而对于另一个函数很大。从定义 3.1 可以看出,如果 L1 很小,那么 f(x) 在 x 的变化很小时可能也只有很小的变化,而如果 L1 很大,那么 f(x) 在 x 变换很小时也可能有很大的变化。
直观上,Lipschitz 连续性利用 Lipschitz 常数 L 量化了函数 f(x) 的连续行为的概念。

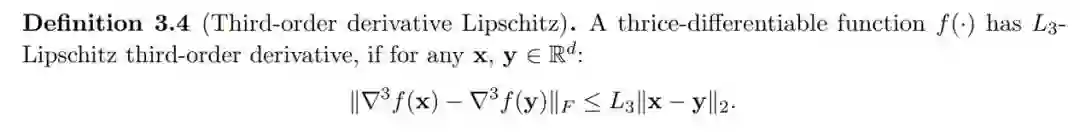
Anandkumar 和 Ge(2016)引入了上述定义,Carmon et al.(2017)也将三阶导数 Lipschitz 称为三阶平滑度。三阶导数 Lipschitz 和三阶平滑这两个术语在下面的章节中可以互换使用。
本文主要的贡献
理论分析
在非凸优化问题中,若我们找到了一个 ε 一阶驻点 x^,但它不是(ε,γ)二阶驻点(这与 Mokhtari、Ozdaglar 和 Jadbabaie 前面的论文中的(ε,γ)二阶驻点一样)。这意味着 x^ 是一个鞍点,并且存在一些如下所示的向量 v^:
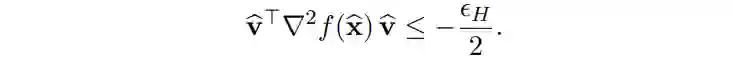
之前 Carmon et al., 2016;Xu and Yang, 2017; Allen-Zhu and Li, 2017b; Yu et al., 2017 在通过负曲率跳出鞍点方面的研究告诉我们,我们可以沿着 v^ 的负曲率下降步骤跳出鞍点 x^。这在本文的(4.1)中有描述。
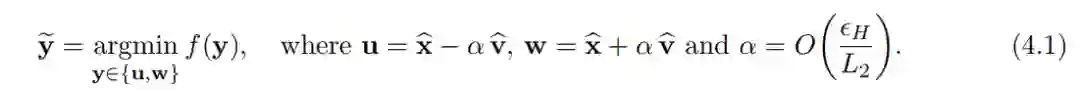
其中,f(y) 是目标函数,假设其为 L1 Lipschitz 和 L2 Lipschitz。此外,α 是步长,其数量级为 O(ε _H/ L2)(可以认为它是步长的大小)。
这与 Mokhtari, Ozdaglar, and Jadbabaie 之前的论文中描述的方法是类似的。这里的思路还是一样的。算法首先找到一个 ε 一阶驻点,如果这个点是一个鞍点,算法就会试图跳出鞍点。
在这种情况下,在没有任何三阶信息的情况下,负曲率下降可以在目标函数值上实现如下所示的下降方式:
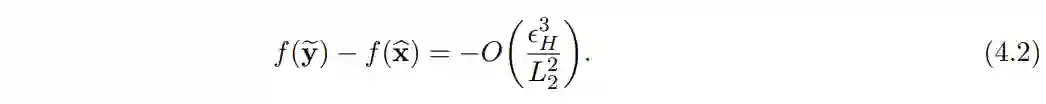
作者的主要工作是增加了目标函数为 L3-Lipschitz 三阶导数的假设。他们的研究结果如下:通过使用目标函数的三阶平滑,可以利用更大的步长 α 跳出鞍点。具体来说,新的步长的数量级为 O(sqrt (ε / L_3))。
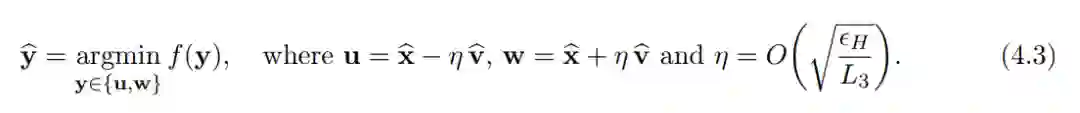
因此,我们可以看到当引入三阶信息时,步长的大小 η 比二阶信息的步长大小 α 要大的多。
结果是,当我们使用三阶平滑时,与(4.2)相比,负曲率下降方法可以在目标函数值上实现一种更好(更快)的下降。
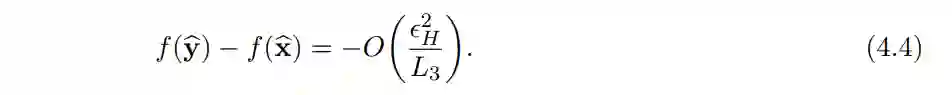
算法分析
在前人研究的负曲率查找算法的基础上,本文作者利用三阶平滑对该算法进行了改进,使步长增大。算法如下所示:

在这里,ApproxNC-FiniteSum(·) 函数是利用随机梯度或随机 Hessian 向量积求负曲率方向的函数。该函数会返回一个向量 v^,它是从当前点 x 开始的一个负的下降方向。请注意,我们还可以通过其它方法找到这个向量,即使用 Mokhtari、Ozdaglar 和 Jadbabaie 提出的方法。
准确率参数 ε_H 通常非常小。因此,我们可以从算法 1 中看到,步长 η 与 ε_H 的平方根成正比,它将会比 α 的步长大得多,而 α 的步长与 ε_H 成正比。
综合分析
在讨论算法的基础上,作者提出了一种求解非凸有限和以及随机优化问题近似局部最小值的方法(基于负曲率下降算法)。
作者所关注的优化问题可以形式化定义如下:
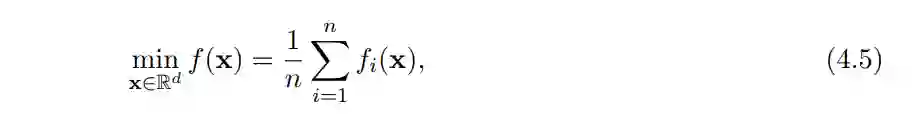
其中 f_i(·) 可能是非凸的。这种情况下,算法可以访问每个单独的函数 f_i(·) 和整个函数 f_i(·) 的信息。对于有限和结构,可以采用基于方差缩减的方法提高不同非凸优化算法的梯度复杂度。
因此,综上所述,我们可以得到以下步骤。首先,我们应用方差缩减随机梯度法,直到找到一个一阶驻点。然后,我们应用算法 1 找到负曲率方向来跳出鞍点(如果它是鞍点的话)。
结论
作者研究了目标函数(可能是非凸的)三阶平滑在随机优化中的好处。他们提出了一种将三阶信息与负曲率下降算法相结合的改进方法,从而展示了三阶平滑可以帮助算法更快地跳出鞍点。
作者在他们提出的负曲率下降算法的基础上,进一步提出了一种实用的改进运行时复杂度的随机优化算法,能够为目标函数是一个有限和形式的非凸优化问题找到局部最小值。
最后,目前最先进的随机局部最小值查找算法(Allen-Zhu, 2017; Tripuraneni et al., 2017; Xu and Yang, 2017; Allen-Zhu and Li, 2017b; Yu et al., 2017)具有 O( ε^(-7/2)) 数量级的运行时间。本文提出的算法的运行时间的数量级为 O(ε^(-10/3)),这比目前最先进的方法的性能还要好。
至此,我们已经讨论了以下问题:
随着神经网络变大、变深,其损失函数往往会陷入鞍点。鞍点的误差大于局部和全局最小值,因此,我们希望避免算法陷入鞍点。
如果算法到达了一个驻点,我们希望
a. 判断该点是局部最小值还是鞍点
b. 如果该点是鞍点,我们需要跳出该鞍点
目前我们看到的论文都关注如何解决上述问题。然而,到达鞍点并跳出鞍点还只是这个方向的研究的冰山一角。它们是对随机梯度下降(SGD)算法的改进,以帮助算法更好地达到局部最小值。随机梯度下降的另一个重要方面是梯度▽ f_i(*x*) 的方差。下一篇论文将讨论一种减小 SGD 方差的新方法。
在我们进入下一篇文章之前,我将给出一个关于梯度下降和随机梯度下降的快速直观的介绍。
梯度下降是机器学习社区中几乎每个人都熟悉的术语。更具体地说,随机梯度下降在解决机器学习中的优化问题的方面取得了巨大的成功。
对于函数 f(x) 的优化问题,其中子函数 f_i(x) 的个数为 n。
如果 f 是凸的,已知批量梯度下降可以实现线性的收敛。然而,在实际应用程序中,n 通常非常大,这使得 f(使用批处理梯度下降法)的计算开销非常大。因此,我们引入了随机梯度下降方法,其中索引 i ∈{1,2,…,n-1, n},服从均匀分布,用于更新当前的 x。然而,作为牺牲,在强凸性条件下,随机方法不具有梯度下降的线性收敛速度。这是因为当 w 接近真正的最小值(即 x)时,f_i(x) 的方差可能很大,导致估计 w 在 x 附近振荡。这两种方法的可视化结果如下:
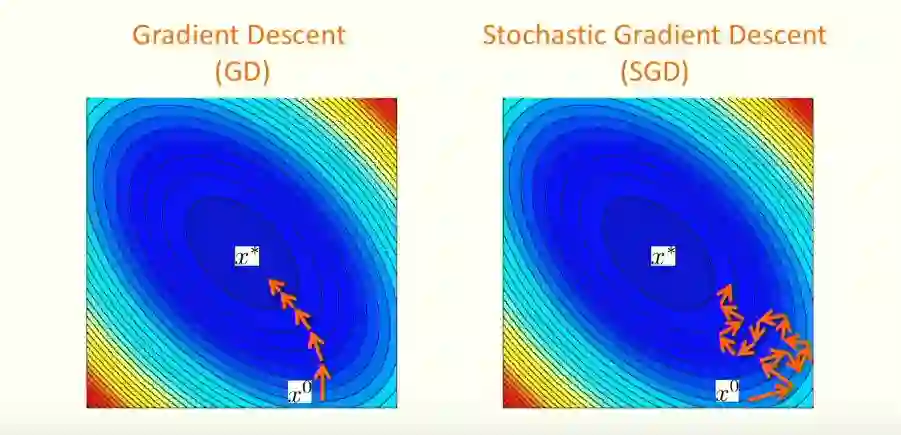
正如我们所看到的,在准确性和计算开销之间有一个平衡。在梯度下降方法中,所采取的步骤更精确,但是需要更高的计算成本。在随机梯度下降中,所采取的每个步骤的计算开销很小,但似乎也会随机地朝着最小值的一般方向前进。SGD 通常需要更多的步骤来达到最小值,但是它在梯度计算上的低成本使得它在实践中(对于大尺寸的问题)更加可行。
论文 3:SEGA: Variance Reduction via Gradient Sketching
论文链接:https://arxiv.org/pdf/1809.03054.pdf
你为什么需要读这篇文章?
在一个有限和形式的问题中,优化目标是在执行随机梯度下降时选择一个▽ f_{i}(*x*) 来减小方差。如果读者在他们的工作中用到过随机梯度下降方法,本文会提供一种针对这个问题的新的视角。如果读者在他们的工作中使用随机梯度下降,这篇文章可以提供一个针对于在不需要有限和目标函数结构的情况下进行方差缩减的问题的新的视角。它为方差缩减技术提供了一些新的见解,因此我们接下来一起回顾这篇论文。
近些年,研究人员提出了随机平均梯度增强(SAGA)和随机方差缩减梯度(SVRG)等方法。然而,这些技术并不是本文讨论的重点。
本文探索了一种基于随机迭代方法的新技术。该方法基于草图和项目框架。高屋建瓴地说,草图是指从一个较难的问题开始,然后随机生成一个包含原问题所有解的简单问题。我将在这里对这项技术进行更详细的讨论。我的目的是为读者介绍这种方法,作为看待这个问题的另一种视角。
预备知识
考虑线性系统 Ax = b,其中 A∈R^(m*n),x∈R^n,b∈R^m。此外, 假设存在线性系统的一个特解 x ∈R^n。令 S∈R^(m*q)为与 A 具有相同行数的随机矩阵但其列数较少(即 q << m)。我们将 S^{T}Ax = S^{T}b 称为最终描绘出的线性系统。S^{T}Ax = S^{T}b 的行数相对较小,因此更容易解决。
点 x* 可以通过迭代过程找到,这个迭代过程使用一系列的概要矩阵逐渐提炼出 Ax = b 的近似解,而不是用单笔草图法。令 x^k∈R^n 为我们当前对 Ax = b 的解的估计。我们可以通过将 x^k 投影到解空间上在如下所示形式描绘出的系统中改进对解的估计。
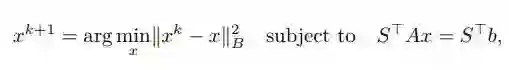
其中,S 是在每一次迭代独立于预先指定的分布绘制而来,B 是一个正定矩阵。更进一步而言,B 被用于定义 B 的内积和引导出如下 N-norm:
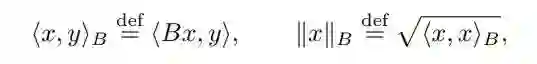
出于简化问题的考虑,我们可以在下文中很安全的假设 B 为单位矩阵。
上述最小化问题有一个带有如下所示的封闭解的迭代过程。
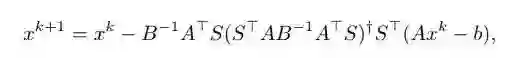
其中 † 为 Moore-Penrose 伪逆。我们使用封闭形式表达式进行更新,结果表明,如果 A 列满秩,假设 S 分布温和,则迭代收敛。
直观地看,由于我们认为原系统 Ax = b 很复杂,我们可以用一个更简单的系统替换它——一个随机的原始系统的草图,其解集 {x | S^T Ax = S^T b} 包了含所有的原始系统的解。x^(k + 1) 可以被认为是最接近 x^k 的点,它可以作为原始版本的线性系统的解。草图系统通常会有很多的解,为了找到最好的 x^(k + 1),我们需要一种方法从解集中来选择它。这个想法需要试图保留尽可能多的目前学到的信息,这些信息是在当前的点 x^k 上提炼而来的。
现在,读者已经熟悉了草图与投影的概念和使用方法,我们将继续探讨这篇论文的内容。作者提出了一种随机一阶优化方法——SkEtched GrAdient (SEGA),该方法通过迭代逐步建立梯度的方差缩减估计值,该估计值来自于从理想状态获得的梯度的随机线性测量(草图)。
SEGA 在每次迭代中使用最新草图提供的信息,通过草图和投影操作更新梯度的当前估计值。这些梯度随后被用于通过随机松弛过程计算真实梯度的无偏估计。接着,SEGA 使用这个无偏估计执行梯度步。
本文的主要贡献
考虑下面的优化问题:

其中 f 为 R^n →R 的映射,它是平滑的凸函数,而 R(x) 是封闭的凸正则化项。作者没有假设我们可以得到真正的梯度▽f(x)。然而,假设理想状态 oracle 提供梯度的随机草图(它只是一种线性变换),我们可以用它来驱动迭代过程。具体而言,在矩阵 S∈R^(n*b)(b≥1,可以将其固定,但并不一定需要这么做)上给定一个固定的分布 D,和一个查询点 x ∈R^n,oracle 提供了算法的随机线性变换的梯度
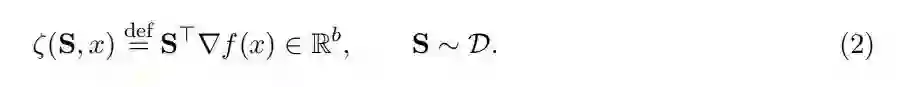
SEGA 算法
令 x^k 为当前这一轮的迭代,并令 h^k 为当前的 f 的梯度估计。接着,该算法查询理想状态 oracle,并接受以梯度(2)的形式描绘出的梯度信息。该算法将基于新的梯度信息更新 h^k。这一步是使用我们设置的草图和投影过程完成的
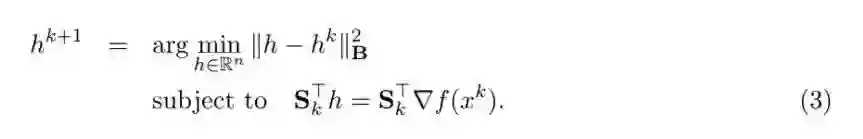
(3)的封闭解为
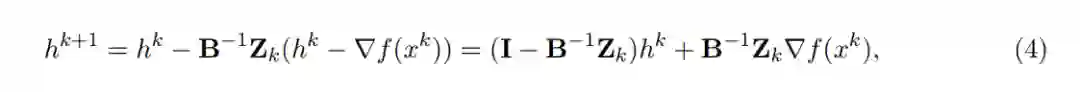
其中 Z_k 被定义为 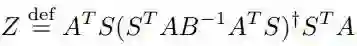
读者可以看到 h^{ k + 1 } 是一个有偏估计量(因为它是在(2)的迭代 k 中选择出来的)。因此,需要引入一个无偏估计量。我们定义以下向量:
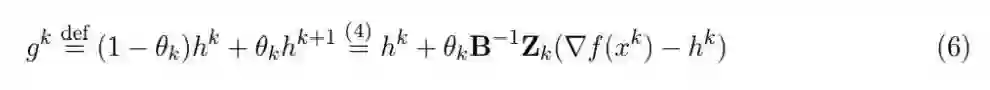
其中,θ_k=θ(S_k)且 E_D[ θ_k *Z*_k ] = *B*. *g*^k 是梯度的无偏估计,它将在算法中被使用。为了说明这一点,我将具体的推导过程附在下面:
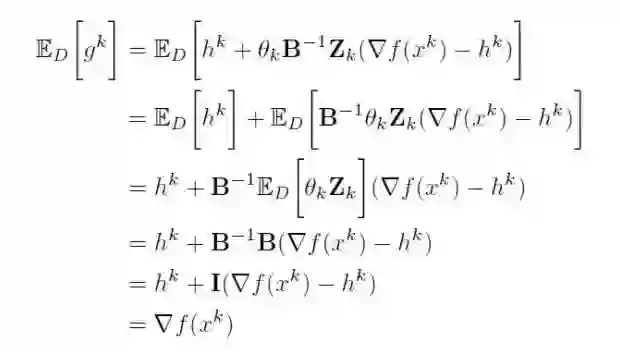
SEGA 算法如下所示:

其中,prox_{αR}() 是近似算子。图中显示了 SEGA 算法与随机坐标下降(CD)相对比的一个实例。我们将只关注 SEGA 算法,不会深入讨论随机坐标下降。但是我们可以看到,与之前的图形化解释相比,SEGA 的步骤紧跟「最佳」路径,准确率不断提高,直至达到最优点。
让我们暂时讨论一下近似算子。我将使用 Rockafellar 的经典著作「凸优化」中的定义。对于凸函数 h(),其近似算子定义如下:
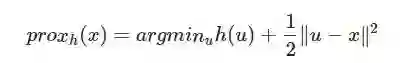
对于那些熟悉 epigraph 的读者来说,下面的例子可以提供一种直观的解释:考虑 g(x) = 1/2 || x ||^{2},h() 函数可能不平滑。函数 (h \Box g)(u) = inf_{u} h(u) + g(u - x) 被称为卷积的下确界,对应于从集合 epi h + epi g 中得到的函数,h\Box g 是一个 h() 的平滑后或正则化后的形式。
对于那些不熟悉 epigraph(函数图上或上方的点集合)的读者,可以简单地将其理解为,我们希望找到一个最小化 h(u) 的点,同时它又接近于 x(prox_h 的参数)。
在本文中,近似算子的定义如下:
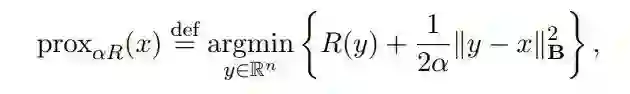
其中 R() 为(1)中定义的凸正则化项。
因此,算法 1 应该是很直观的。经过初始化后,我们在每一步都进行采样得到草图矩阵 S,计算并估计梯度 g^k,使用 g^k 更新当前点 x^ k, 最后我们计算用于下一轮迭代的有偏估计量 h^{ k + 1 }。
对于 SEGA 算法更直观的理解
在这里,我将尝试从优化的角度提供一种对 SEGA 算法更直观的理解。让我们仔细看看(3)中草图和投影法的流程:
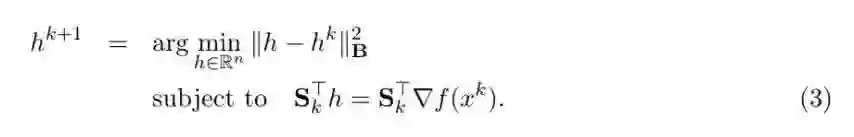
这与我们在预备知识章节讨论过的通用公式的形式是一致的。
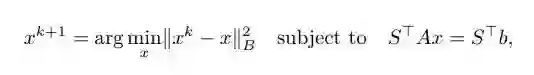
我们将使用这个通用的公式进一步为 SEGA 算法提供一个直观的理解方式并且实现在几何/视觉形式上的解释。回想一下,我们之前说过系统 Ax = b 有一个解 x*。为了便于解释,假设已知 x*和 B 是单位矩阵。然后,可以将上述内容重新表述为以下形式:
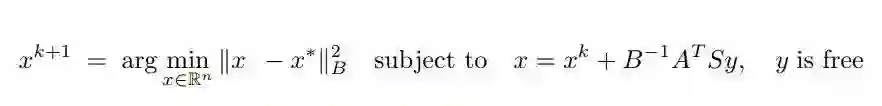
我们可以通过下面的式子解读该公式。选择一个随机的包含 x^k 的仿射空间,并且约束该方法从这个空间选择下一个迭代的点。然后,我们试着在这个空间上达到最优,换句话说,我们选择 x^(k+1)作为最接近 x * 的点。我们可以从线面的几何的角度来理解: x^(k+1)是两个仿射空间唯一的交集。
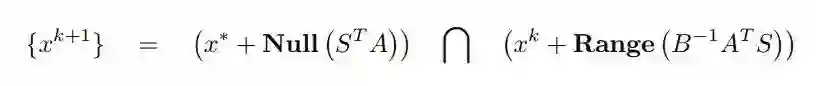
由于任意矩阵的零空间是其转置的范围空间的正交补,我们知道任何时候在零空间 Null(S^TA) 中的任何点将与 Range(A^T S)(A^T S 的列空间)。最后,我们现在可以从下图中看到这个理论的可视化结果:
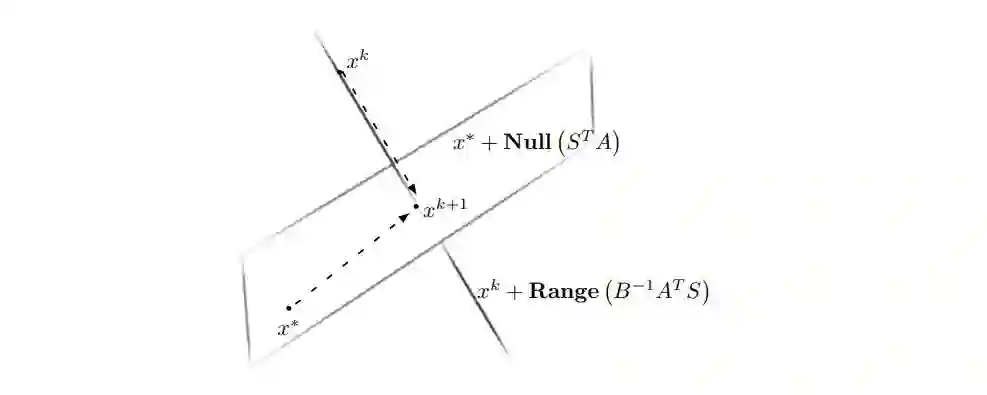
因此,我们可以看到,在下一轮迭代中,x^(k+1) 将成为两个随机仿射空间(x^{k} + Range(A^T S) 和 x* + Null(S^T A))的交点:我们可以等价地将 x^(k+1) 看成 x^k 在 x* + Null(S^TA) 上的投影。
SEGA 是一种方差缩减方法
如前所述,仔细观察图 1,你会发现,梯度估计是对于▽f(x^k) 的一种更好的近似,在迭代中 x^k 越来越接近最优点。因此,g^k 的方差是梯度趋于零的一个估计量,这意味着 SEGA 是一种方差缩减算法。
SEGA 的收敛结果
本文的一个关键理论贡献是,讨论了 SEGA 算法的收敛性。它说明了 SEGA 的迭代可以线性收敛到最优解。在不涉及数学细节的情况下,作者证明了上述定理在光滑性假设下成立。
结论
本文提出了一种在新的随机线性一阶理想状态下的复合优化问题的求解方法。本文提出的算法 SEGA 是基于方差缩减的方法,这是通过「草图和投影」更新梯度估计实现的。
在本文中,笔者重点对草图和投影过程及进行了解释,目的是帮助读者更好地理解算法背后的几何意义,并希望能够为读者提供对 SEGA 算法更好的直观理解。然而,在对算法进行分析时,收敛的理论结果也很重要。原文作者给出了许多证明,从而得出了该算法收敛性的推论。此外,他们展示了进一步的扩展方法,与投影梯度下降相比会更快。如果这篇文章足够吸引读者的话,笔者会把这些细节留给他们自己去阅读。
总结和延伸阅读
出于以下的原因,我在本文中选择了 3 篇论文进行分析并和大家分享。
就我个人而言,在尝试解决一个优化问题的过程中,我经常会经历这样的过程:定义和形式化表达问题,确定解决问题的算法,推导出预期的结果或解,并最终实现算法。很多时候,到目前为止一切似乎都很完美,但是一旦我开始进行仿真,往往一切都会出乎意料之外。
很多时候,我发现发生这些意外错误的原因来自于该问题的一些最小的细节,即算法陷入了一个鞍点,但找不到一个下降方向, 下一轮迭代的解并不在可行解空间中,因此需要被投影回来,收敛太慢是因为我不确定步长应该是多少,收敛太慢,是因为使用随机梯度下降时的方差等问题。
因此,我认为这三篇论文似乎可以涵盖解决优化问题的一些细节。最后,我希望在每一篇论文的评论中,读者应该学到以下几点。
论文:Escaping Saddle Points in Constrained Optimization
当我们要解决一个带约束的优化问题时,为了跳出鞍点,我们必须找到一个可行的梯度下降的方向。
为了找到这个可行的梯度下降的方向,我们可以形式化定义另一个优化问题,即找到「最优」的梯度下降方向。
论文:Third-order Smoothness Helps: Even Faster Stochastic Optimization Algorithms for Finding Local Minima
为了跳出鞍点,我们需要知道一个可行的下降方向。在这列,我们可以使用上一篇论文中描述的算法找到这种方法。
如果可以保证目标函数的三阶平滑性,我们可以在更大的步长下,更快地从这个鞍点上向梯度下降的方向跳出来。
这个步长取决于 Lipschitz 常数和准确率参数。一旦确定了步长,我们就将在随机梯度下降算法中使用它。
论文:SEGA: Variance Reduction via Gradient Sketching
在随机梯度下降法中,我们希望减小估计梯度的方差(从而使每个估计与真实梯度相差不远)。
SEGA 方差缩减方法采用迭代随机算法。这是通过将一个困难(在计算方面)的问题简化为一个容易(或更轻松的问题)的问题,利用草图和投影法来解这个问题。
在平滑假设下,随着迭代逼近最优点,每一步的梯度估计都更接近真实梯度。即梯度估计值逐渐提高,从而达到方差缩减的目的。
草图和投影法在求解线性系统时也非常有用。因此,几何直觉对于理解这种方法是很重要的,这样它就可以应用于我们可能遇到的其他问题。
最后,我还列出了一些与上述问题或其他实际实施问题相关的有趣论文。我建议有兴趣的读者可以阅读一下这些论文:
Accelerated Stochastic Matrix Inversion: General Theory and Speeding up BFGS Rules for Faster Second-Order Optimization:为实现更快的二阶优化提出的通用理论以及对 BFGS 规则(一种拟牛顿算法)的加速。文介绍了许多梯度下降方法,包括计算 Hessian 矩阵的 Hessian 来提供目标函数的曲率信息。计算 Hessian 的开销是巨大的,这是求解最优化问题时的关键部分。因此,我强烈推荐读者阅读一下本文。本文与前面介绍的「SEGA: Variance Reduction via Gradient Sketching」一文相得益彰。所以有兴趣的读者最好仔细阅读一下这篇文章。
Distributed Stochastic Optimization via Adaptive SGD:实际上,随机梯度下降是一系列非常难以并行处理的算法。在本文中,作者通过将自适应性与方差缩减技术相结合提出了一种高效的分布式随机优化方法。
Adaptive Methods for Nonconvex Optimization:依赖于对过去的平方梯度的指数移动均值进行梯度衰减的自适应梯度下降算法。作者针对非凸随机优化问题,提出了一种新的分析方法,描述了增加 minibatch 规模的效果。这篇论文很有趣,因为它很实用。
Adaptive Negative Curvature Descent with Applications in Non-convex Optimization:在讨论了通过一个负曲率下降的方向跳出鞍点的重要性的基础上,本文提出了一种在负曲率下降方向的质量与计算负曲率的复杂度之间折中的办法。同样,这也是一种非常实用的优化方法。因此,我建议感兴趣的读者仔细阅读一下这篇文章。

本文为机器之心原创,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com





