如何使用 Keras 实现无监督聚类

雷锋网 AI 研习社按:本文为雷锋字幕组编译的技术博客,原标题 A、Word2Vec — a baby step in Deep Learning but a giant leap towards Natural Language Processing,作者为机器学习工程师 Suvro Banerjee
翻译 | 程炜 李昊洋 整理 | 孔令双
原文链接:
https://medium.com/@chengweizhang2012/how-to-do-unsupervised-clustering-with-keras-9e1284448437
由于深度学习算法在表达非线性表征上的卓越能力,它非常适合完成输入到有标签的数据集输出的映射。这种任务叫做分类。它需要有人对数据进行标注。无论是对 X 光图像还是对新闻报道的主题进行标注,在数据集增大的时候,依靠人类进行干预的做法都是费时费力的。
聚类分析,或者称作聚类是一种无监督的机器学习技术。它不需要有标签的数据集。它可以根据数据成员的相似性对它们进行分组。
你为什么需要关注它呢?让我来讲讲几个理由。

聚类的应用
推荐系统,通过学习用户的购买历史,聚类模型可以根据相似性对用户进行区分。它可以帮助你找到志趣相投的用户,以及相关商品。
在生物学上,序列聚类算法试图将相关的生物序列进行分组。它根据氨基酸含量对蛋白进行聚类。
图像和视频聚类分析根据相似性对它们进行分组。
在医疗数据库中,对每个病人来说,真正有价值的测试(比如葡萄糖,胆固醇)都是不同的。首先对病人进行聚类分析可以帮助我们对真正有价值的特征进行分类,从而减少特征分散。它可以增加分类任务的准确性,比如在癌症病人生存预测上。
在一般用途上,它可以生成一个数据的汇总信息用于分类,模式发现,假设生成,以及测试。
无论如何,对于数据科学家来说,聚类都是非常有价值的工具。
如何才是好的聚类
一个好的聚类方法应该生成高质量的分类,它有如下特点:
群组内部的高相似性:群组内的紧密聚合
群组之间的低相似性:群组之间各不相同
为 K-Means 算法设置一个基线
传统的 K-Means 算法速度快,并且可以广泛应用于解决各种问题。但是,它的距离度量受限于原始的数据空间。因此在输入数据维度较高时,它的效率就会降低,比如说图像集。
让我们来训练一个 K-Means 模型对 MNIST 手写字体进行聚类分析到 10 个群组中。
from sklearn.cluster import KMeans
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x = np.concatenate((x_train, x_test))
y = np.concatenate((y_train, y_test))
x = x.reshape((x.shape[0], -1))
x = np.divide(x, 255.)
# 10 clusters
n_clusters = len(np.unique(y))
# Runs in parallel 4 CPUs
kmeans = KMeans(n_clusters=n_clusters, n_init=20, n_jobs=4)
# Train K-Means.
y_pred_kmeans = kmeans.fit_predict(x)
# Evaluate the K-Means clustering accuracy.
metrics.acc(y, y_pred_kmeans)
评估得到 K-Means 聚类算法的准确度在 53.2%。后面我们会将它与深度嵌入聚类模型进行比较。
一个自动编码器,通过前训练,学习无标签数据集初始压缩后的表征。
建立在编码器之上的聚类层将输出送给一个群组。基于当前评估得到的 K-Means 聚类中心,聚类层完成权重值的初始化。
训练聚类模型,同时改善聚类层和编码器。
在找源代码吗?到我的 Github 上看看。
https://github.com/Tony607/Keras_Deep_Clustering
前训练自动编码器
自动编码器是一个数据压缩算法。它由编码器和解码器两个主要部分构成。编码器的工作是将输入数据压缩成较低维度的特征。比如,一个 28x28 的 MNIST 图像总共有 784 个像素。编码器可以将它压缩成 10 个浮点数组成的数组。我们将这些浮点数作为图像的特征。另一方面,解码器将压缩后的特征作为输入,通过它重建出与原始图像尽可能相近似的图像。实际上,自动编码器是一个无监督学习算法。在训练过程中,它只需要图像本身,而不需要标签。
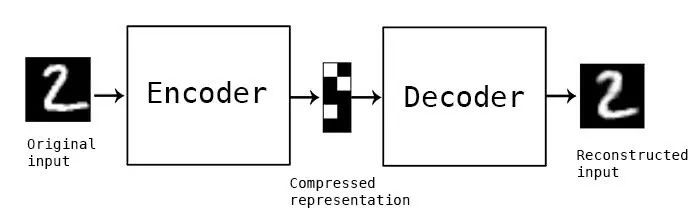
自动编码器
自动编码器是一个全连接对称模型。之所以是对称的,是因为图像的压缩和解压过程是一组完全相反的对应过程。
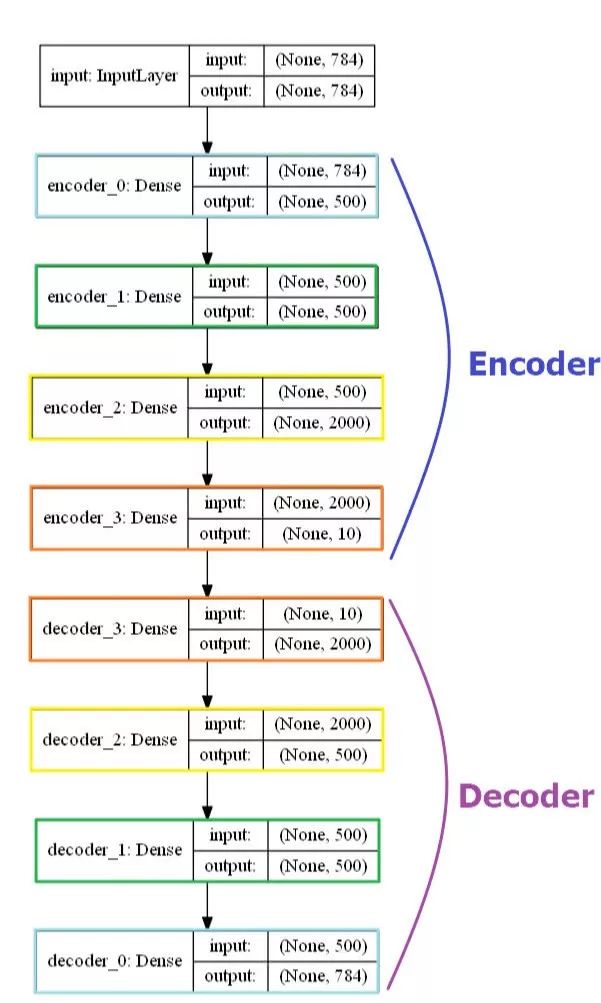
全连接自动编码器
我们将会对自动编码器进行 300 轮训练,并保存下模型权重值。
autoencoder.fit(x, x, batch_size=256, epochs=300) #, callbacks=cb)
autoencoder.save_weights('./results/ae_weights.h5')
聚类模型
通过训练自动编码器,我们已经使编码器学会了将每幅图像压缩成 10 个浮点数。你可能会想,因为输入维度减少到 10, K-Means 算法应该可以以此开始聚类?是的,我们将会使用 K-Means 算法生成聚类中心。它是 10 维特征向量空间的 10 个群组的中心。但是我们还要建立我们的自定义聚类层,将输入特征转化为群组标签概率。
这个概率是由t-分布计算得来。 T-分布,和t-分布邻域嵌入算法一样,测度了内含点和中心点之间的相似度。.正如你所猜测的那样,聚类层的作用类似于用于聚类的K-means,并且该层的权重表示可以通过训练K均值来初始化的聚类质心。
如果您是在Keras中创建自定义图层的新手,那么您可以实施三种强制方法。
build(input_shape),在这里你定义图层的权重,在我们的例子中是10-D特征空间中的10个簇,即10x10个权重变量。
call(x),层逻辑所在的地方,即从特征映射到聚类标签魔术的地方。
compute_output_shape(input_shape),在这里指定从输入形状到输出形状的形状转换逻辑。
Here is the custom clustering layer code:
class ClusteringLayer(Layer):
"""
Clustering layer converts input sample (feature) to soft label.
# Example
```
model.add(ClusteringLayer(n_clusters=10))
```
# Arguments
n_clusters: number of clusters.
weights: list of Numpy array with shape `(n_clusters, n_features)` witch represents the initial cluster centers.
alpha: degrees of freedom parameter in Student's t-distribution. Default to 1.0.
# Input shape
2D tensor with shape: `(n_samples, n_features)`.
# Output shape
2D tensor with shape: `(n_samples, n_clusters)`.
"""
def __init__(self, n_clusters, weights=None, alpha=1.0, **kwargs):
if 'input_shape' not in kwargs and 'input_dim' in kwargs:
kwargs['input_shape'] = (kwargs.pop('input_dim'),)
super(ClusteringLayer, self).__init__(**kwargs)
self.n_clusters = n_clusters
self.alpha = alpha
self.initial_weights = weights
self.input_spec = InputSpec(ndim=2)
def build(self, input_shape):
assert len(input_shape) == 2
input_dim = input_shape[1]
self.input_spec = InputSpec(dtype=K.floatx(), shape=(None, input_dim))
self.clusters = self.add_weight((self.n_clusters, input_dim), initializer='glorot_uniform', name='clusters')
if self.initial_weights is not None:
self.set_weights(self.initial_weights)
del self.initial_weights
self.built = True
def call(self, inputs, **kwargs):
""" student t-distribution, as same as used in t-SNE algorithm.
q_ij = 1/(1+dist(x_i, µ_j)^2), then normalize it.
q_ij can be interpreted as the probability of assigning sample i to cluster j.
(i.e., a soft assignment)
Arguments:
inputs: the variable containing data, shape=(n_samples, n_features)
Return:
q: student's t-distribution, or soft labels for each sample. shape=(n_samples, n_clusters)
"""
q = 1.0 / (1.0 + (K.sum(K.square(K.expand_dims(inputs, axis=1) - self.clusters), axis=2) / self.alpha))
q **= (self.alpha + 1.0) / 2.0
q = K.transpose(K.transpose(q) / K.sum(q, axis=1)) # Make sure each sample's 10 values add up to 1.
return q
def compute_output_shape(self, input_shape):
assert input_shape and len(input_shape) == 2
return input_shape[0], self.n_clusters
def get_config(self):
config = {'n_clusters': self.n_clusters}
base_config = super(ClusteringLayer, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
接下来,我们在预先训练的编码器之后堆叠聚类层以形成聚类模型。 对于聚类层,我们初始化它的权重,聚类中心使用k-means对所有图像的特征向量进行训练。
clustering_layer = ClusteringLayer(n_clusters, name='clustering')(encoder.output)
model = Model(inputs=encoder.input, outputs=clustering_layer)
# Initialize cluster centers using k-means.
kmeans = KMeans(n_clusters=n_clusters, n_init=20)
y_pred = kmeans.fit_predict(encoder.predict(x))
model.get_layer(name='clustering').set_weights([kmeans.cluster_centers_])
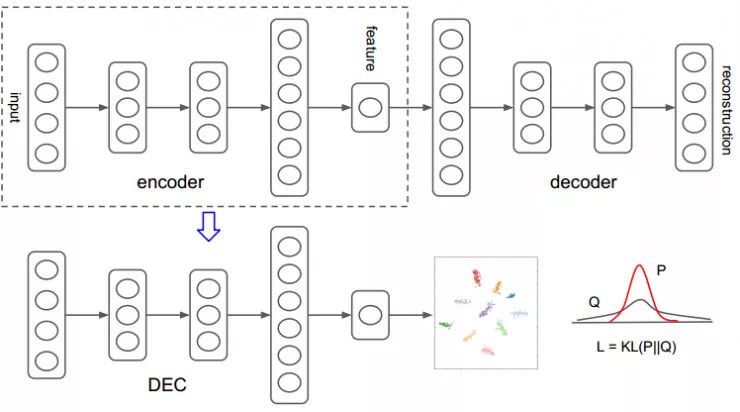
聚类模型结构
训练聚类模型
辅助目标分布和KL散度损失
下一步是同时改进聚类分配和特征表示。 为此,我们将定义一个基于质心的目标概率分布,并根据模型聚类结果将KL偏差最小化。
我们希望目标分配具有以下属性:
加强预测,即提高群集纯度。
更加重视高可信度地分配的数据点。
防止大集群扭曲隐藏的特征空间。
通过首先将q(编码特征向量)提升到第二幂然后按每个簇的频率进行归一化来计算目标分布。
def target_distribution(q):
weight = q ** 2 / q.sum(0)
return (weight.T / weight.sum(1)).T
有必要通过在辅助目标分布的帮助下从高置信度分配中学习来迭代地细化群集。 在特定次数的迭代之后,更新目标分布,并且训练聚类模型以最小化目标分布与聚类输出之间的KL散度损失。 培训策略可以被看作是一种自我训练的形式。 就像在自我训练中一样,我们采用初始分类器和未标记的数据集,然后用分类器标记数据集以训练其高置信度的预测。
损失函数,KL散度或Kullback-Leibler散度是衡量两种不同分布之间行为差异的指标。 我们希望将其最小化,以便目标分布尽可能接近聚类输出分布。
在以下代码片段中,目标分布每180次训练迭代更新一次。
model.compile(optimizer=SGD(0.01, 0.9), loss='kld')
maxiter = 8000
update_interval = 140
for ite in range(int(maxiter)):
if ite % update_interval == 0:
q = model.predict(x, verbose=0)
p = target_distribution(q) # update the auxiliary target distribution p
# evaluate the clustering performance
y_pred = q.argmax(1)
if y is not None:
acc = np.round(metrics.acc(y, y_pred), 5)
idx = index_array[index * batch_size: min((index+1) * batch_size, x.shape[0])]
model.train_on_batch(x=x[idx], y=p[idx])
index = index + 1 if (index + 1) * batch_size <= x.shape[0] else 0
每次更新后,您将看到聚类准确度稳步提高。
评估指标
该度量标准表明它已达到96.2%的聚类精度,考虑到输入是未标记的图像,这非常好。 让我们仔细研究它的精确度。
该度量需要从无监督算法和地面实况分配中获取一个集群分配,然后找到它们之间的最佳匹配。
最好的映射可以通过在scikit学习库中实现的匈牙利算法有效地计算为linear_assignment。
from sklearn.utils.linear_assignment_ import linear_assignment
y_true = y.astype(np.int64)
D = max(y_pred.max(), y_true.max()) + 1
w = np.zeros((D, D), dtype=np.int64)
# Confusion matrix.
for i in range(y_pred.size):
w[y_pred[i], y_true[i]] += 1
ind = linear_assignment(-w)
acc = sum([w[i, j] for i, j in ind]) * 1.0 / y_pred.size
查看混淆矩阵更直接。
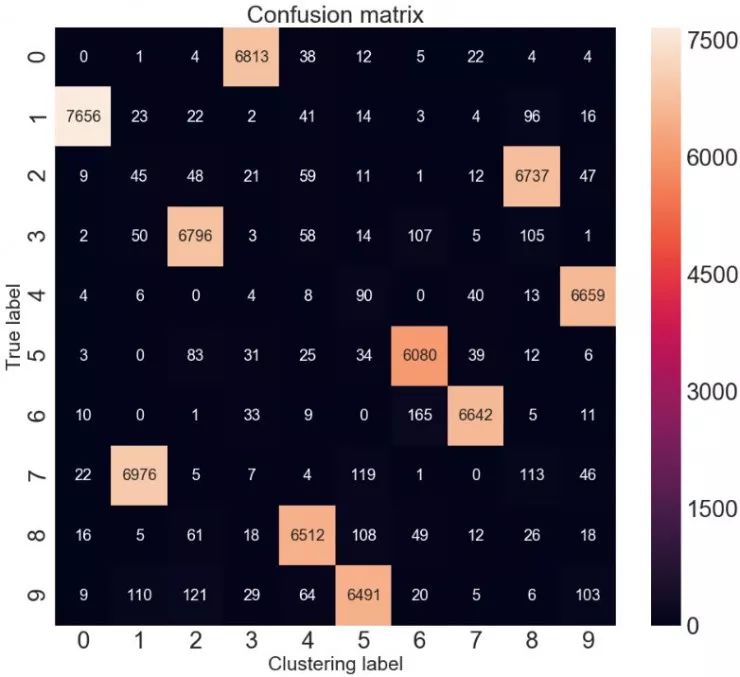
混乱矩阵
在这里,您可以手动快速匹配聚类分配,例如,聚类1与真实标签7或手写数字“7”和虎钳签证相匹配。
下面显示的混淆矩阵绘制代码片段。
import seaborn as sns
import sklearn.metrics
import matplotlib.pyplot as plt
sns.set(font_scale=3)
confusion_matrix = sklearn.metrics.confusion_matrix(y, y_pred)
plt.figure(figsize=(16, 14))
sns.heatmap(confusion_matrix, annot=True, fmt="d", annot_kws={"size": 20});
plt.title("Confusion matrix", fontsize=30)
plt.ylabel('True label', fontsize=25)
plt.xlabel('Clustering label', fontsize=25)
plt.show()
应用卷积自动编码器(实验)
由于我们正在处理图像数据集,所以值得一试卷积自动编码器,而不是仅使用完全连接的图层构建。
值得一提的是,为了重建图像,您可以选择去卷积层(Keras中的Conv2DTranspose)或上采样(UpSampling2D)层以减少伪像问题。卷积自动编码器的实验结果可以在我的GitHub上找到。
结论和进一步阅读
自动编码器在降维和参数初始化方面发挥了重要作用,然后针对目标分布对定制的聚类层进行训练以进一步提高精度。
进一步阅读
在Keras建立自动编码器 - 官方Keras博客
用于聚类分析的无监督深嵌入 - 激励我写这篇文章。
完整的源代码在我的GitHub上,一直读到笔记本的最后,因为您会发现另一种可以同时减少聚类和自动编码器丢失的另一种方法,这种方法被证明对于提高卷积聚类模型的聚类准确性非常有用。




