「深度学习撞墙」激辩到第 N 回合,Gary Marcus 回怼 LeCun:你们对我说的话有误解。
![]()
符号处理是逻辑学、数学和计算机科学中常见的过程,它将思维视为代数操作。近 70 年来,人工智能领域最根本的争论就是人工智能系统应该建立在符号处理的基础上还是类似于人脑的神经系统之上。
实际上还有作为中间立场的第三种可能——混合模型。通过将神经网络的数据驱动学习与符号处理的强大抽象能力相结合,混合模型试图获得两全其美的能力。这也是我个人职业生涯大部分时间的工作方向。
在最近发表于 NOEMA 杂志的
一篇文章
中,图灵奖得主、Meta 首席人工智能科学家 Yann LeCun 和 LeCun 实验室的「常驻哲学家」Jacob Browning 也卷入了这场争论。这篇文章似乎提供了新的替代方案,但仔细检查后就会发现文章观点既不新鲜也不令人信服。
Yann LeCun 和 Jacob Browning 在发表于 NOEMA 杂志的文章中首次正式回应「
深度学习撞墙了
」这个观点,表示「从一开始,批评者就过早地认为神经网络已经遇到了不可翻越的墙,但每次都被证明只是一个暂时的障碍。」
在文章的开头,他们似乎反对混合模型,混合模型通常被定义为是结合了神经网络深度学习和符号处理的系统。但到最后,LeCun 一反常态,用很多话承认混合系统的存在——它们很重要,它们是一种可能的前进方式,而且我们一直知道这一点。文章本身就是矛盾的。
至于为什么会出现这种矛盾,我唯一能想到的原因是 LeCun 和 Browning 以某种方式相信:学习了符号处理的模型并不是混合模型。但学习是一个发展中的问题(系统是如何产生的?),而已经发展好的系统如何运作(是用一种机制还是两种)是一个计算问题:无论以哪种合理的标准来衡量,同时利用了符号和神经网络两种机制的系统都是一个混合系统。(也许他们真正想说的是,AI 更像是一种习得的混合系统(learned hybrid),而不是先天的混合系统(innate hybrid)。但习得的混合系统仍然是混合系统。)
在 2010 年左右,符号处理被深度学习的支持者看作是一个糟糕的词;而到了 2020 年,了解符号处理的来源成了我们的首要任务。
我认为符号处理要么是与生俱来的,要么是其他东西间接地促成了符号处理的获得。我们越早弄清楚是什么基础允许系统学习符号抽象,我们就能够越早地构建适当利用世界上所有知识的系统,系统也将更安全、更可信和可解释。
然而,首先我们需要了解人工智能发展史上这场重要辩论的来龙去脉。
早期的人工智能先驱 Marvin Minsky 和 John McCarthy 认为符号处理是唯一合理的前进方式,而神经网络先驱 Frank Rosenblatt 认为人工智能将更好地建立在类似神经元的「节点」集合并可处理数据的结构上,以完成统计数据的繁重工作。
这两种可能并不相互排斥。人工智能所使用的「神经网络」并不是字面上的生物神经元网络。相反,它是一个简化的数字模型,与实际生物大脑有几分相似,但复杂度很小。原则上,这些抽象神经元可以以许多不同的方式连接起来,其中一些可以直接实现逻辑和符号处理。早在 1943 年,该领域最早的论文之一《A Logical Calculus of the Ideas Inmanent in Nervous Activity》就明确承认了这种可能性。
20 世纪 50 年代的 Frank Rosenblatt 以及 1980 年代的 David Rumelhart 和 Jay McClelland,提出了神经网络作为符号处理的替代方案;Geoffrey Hinton 也普遍支持这一立场。
这里不为人知的历史是,早在 2010 年代初期,LeCun、Hinton 和 Yoshua Bengio 对这些终于可以实际应用的多层神经网络非常热情,他们希望完全消灭符号处理。到 2015 年,深度学习仍处于无忧无虑、热情洋溢的时代,LeCun、Bengio 和 Hinton 在 Nature 上撰写了一份关于深度学习的宣言。这篇文章以对符号的攻击结束,认为「需要新的范式来通过对大型向量的操作取代基于规则的符号表达式操作」。
事实上,那时的 Hinton 非常确信符号处理是一条死胡同,以至于同年他在斯坦福大学做了一个名为「Aetherial Symbols」的演讲——将符号比作科学史上最大的错误之一。
类似地,20 世纪 80 年代,Hinton 的合作者 Rumelhart 和 McClelland 也提出了类似的观点,他们在 1986 年的一本著作中辩称:符号不是「人类计算的本质」。
当我在 2018 年写了一篇文章为符号处理辩护时,LeCun 在 Twitter 上称我的混合系统观点「大部分是错误的」。彼时,Hinton 也将我的工作比作在「汽油发动机」上浪费时间,而「电动发动机」才是最好的前进方式。甚至在 2020 年 11 月,Hinton 还声称「深度学习将无所不能」。
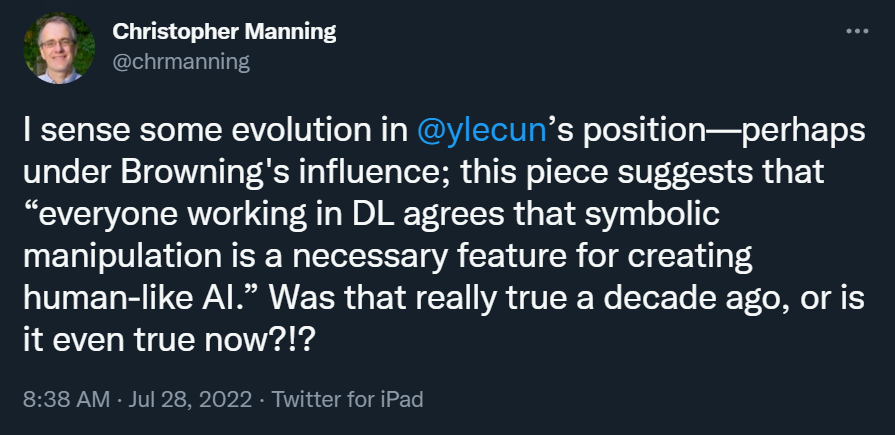
因此,当 LeCun 和 Browning 现在毫不讽刺地写道:「在深度学习领域工作的每个人都同意符号处理是创建类人 AI 的必要特征」,他们是在颠覆几十年的辩论史。正如斯坦福大学人工智能教授 Christopher Manning 所说:「LeCun 的立场发生了一些变化。」
2010 年代,机器学习社区中许多人断言(没有真正的论据):「符号在生物学上不可信」。而十年后,LeCun 却正在考虑一种包含符号处理的新方案,无论符号处理是与生俱来的还是后天习得的。LeCun 和 Browning 的新观点认为符号处理是至关重要的,这代表了深度学习领域的巨大让步。
人工智能历史学家应该将 NOEMA 杂志的文章视为一个重大转折点,其中深度学习三巨头之一的 LeCun 首先直接承认了混合 AI 的必然性。
值得注意的是,今年早些时候,深度学习三巨头的另外两位也表示支持混合 AI 系统。计算机科学家吴恩达和 LSTM 的创建者之一 Sepp Hochreiter 也纷纷表示支持此类系统。而 Jürgen Schmidhuber 的 AI 公司 NNAISANCE 近期正围绕着符号处理和深度学习的组合进行研究。
LeCun 和 Browning 的文章的其余内容大致可以分为三个部分:
例如,LeCun 和 Browning 说:「Marcus 认为,如果你一开始没有符号处理,那你后面也不会有(if you don’t have symbolic manipulation at the start, you’ll never have it)。」而事实上我在 2001 年的《代数思维(The Algebraic Mind)》一书中明确表示:我们不确定符号处理是否是与生俱来的。
他们还称我预计深度学习「无法取得进一步进展」,而我的实际观点并不是在任何问题上都不会再有任何进展,而是深度学习对于某些工作(例如组合性问题、因果推理问题)来说本身就是错误的工具。
他们还说我认为「符号推理对于一个模型来说是 all-or-nothing 的,因为 DALL-E 没有用符号和逻辑规则作为其处理的基础,它实际上不是用符号进行推理,」而我并没有说过这样的话。DALL·E 不使用符号进行推理,但这并不意味着任何包含符号推理的系统必须是 all-or-nothing 的。至少早在 20 世纪 70 年代的专家系统 MYCIN 中,就有纯粹的符号系统可以进行各种定量推理。
除了假设「包含习得符号的模型不是混合模型」,他们还试图将混合模型等同于「包含不可微分符号处理器的模型」。他们认为我将混合模型等同于「两种东西简单的结合:在一个模式完善(pattern-completion)的深度学习模块上插入一个硬编码的符号处理模块。」而事实上,每个真正从事神经符号 AI 工作的人都意识到这项工作并不是这么简单。
相反,正如我们都意识到的那样,问题的关键就是构建混合系统的正确方法。人们考虑了许多不同方法来组合符号和神经网络,重点关注从神经网络中提取符号规则、将符号规则直接转换为神经网络、构建允许在神经网络和符号系统之间传递信息的中间系统等技术,并重构神经网络本身。许多途径都正在探索中。
最后,我们来看一下最关键的问题:符号处理是否可以通过学习学得而不需要从一开始就内置?
我直截了当地回答:当然可以。据我所知,没有人否认符号处理是可以习得的。2001 年,我在《代数思维》的第 6.1 节中回答过这个问题,虽然我认为这不太可能,但我没有说这是绝对不可能的。相反,我的结论是:「这些实验和理论肯定不能保证符号处理的能力是与生俱来的,但它们确实符合这一观点。」
第一是「可学习性」观点:在《代数思维》整本书中,我展示了某些类型的系统(基本是当今更深层系统的前身)未能学得符号处理的各个方面,因此不能保证任何系统都能够学习符号处理。正如我书中原话:
有些东西必须是与生俱来的。但「先天」和「后天」这两者并没有真正的冲突。大自然提供了一套允许我们与环境互动的机制、一套从世界中提取知识的工具,以及一套利用这些知识的工具。如果没有一些与生俱来的学习工具,我们也根本就不会学习。
发展心理学家 Elizabeth Spelke 曾说:「我认为一个具有一些内置起点(例如对象、集合、用于符号处理的装置等)的系统将比纯粹的白板更有效地了解世界。」事实上,LeCun 自己最著名的卷积神经网络工作也能说明这一点。
第二点是人类婴儿表现出一些拥有符号处理能力的证据。在我实验室的一组经常被引用的规则学习实验中,婴儿将抽象模式的范围泛化了,超越了他们训练中的具体例子。人类婴儿隐含逻辑推理能力的后续工作会进一步证实这一点。
不幸的是,LeCun 和 Browning 完全回避了我这两个观点。奇怪的是,他们反而将学习符号等同于较晚习得的东西,例如「地图、图像表示、仪式甚至社会角色),显然没有意识到我和其他几位认知科学家从认知科学的大量文献中汲取的关于婴儿、幼儿和非人类动物的思考。如果一只小羊在出生后不久就可以爬下山坡,那么为什么一个新生的神经网络不能加入一点符号处理呢?
最后,令人费解的是,为什么 LeCun 和 Browning 会费尽心力地反对符号处理的先天性呢?他们没有给出反对先天性的强有力的原则性论据,也没有给出任何原则性的理由来证明符号处理是后天习得的。
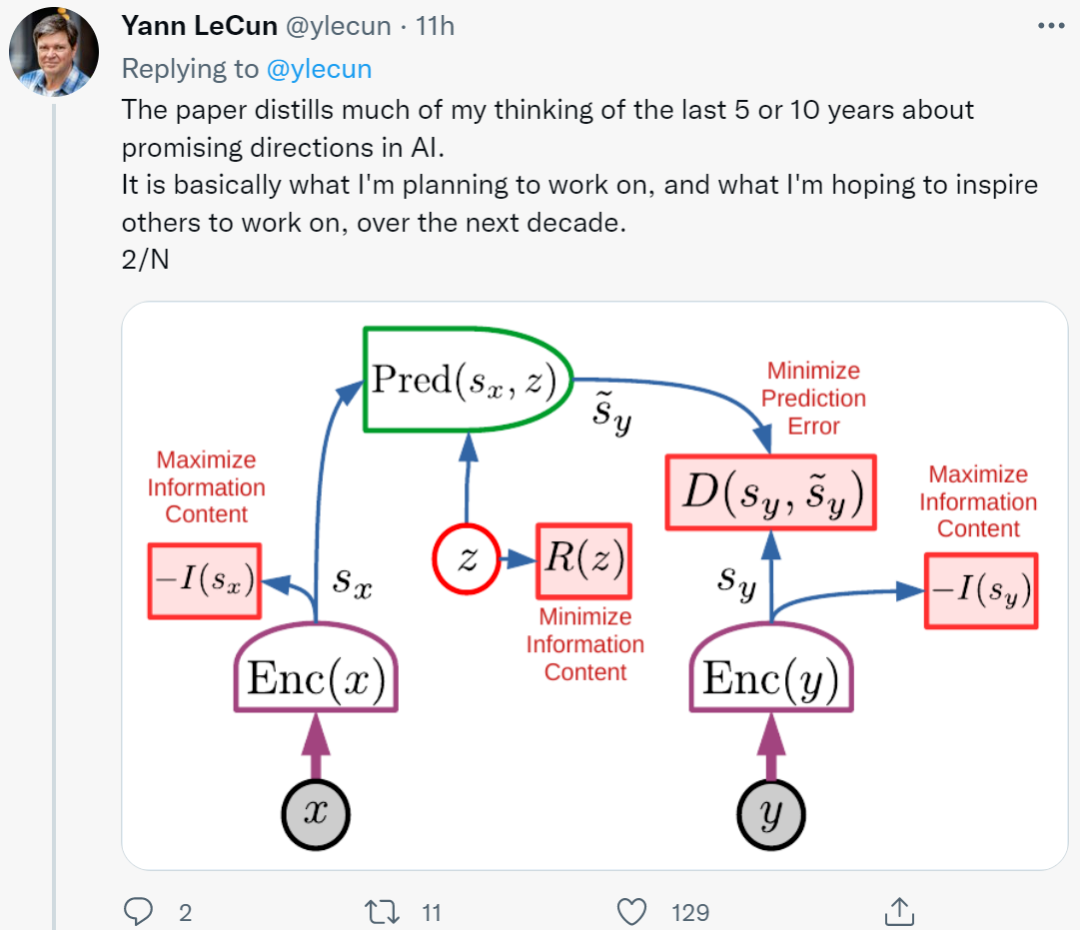
值得注意的是,LeCun 的
最新研究
包容了一些「先天的」符号处理。他最近推出的新架构总体包含六个模块,其中大部分是可调的,但所有模块都是内置的。
此外,LeCun 和 Browning 也没有具体说明如何解决语言理解和推理中众所周知的特定问题,因为语言模型没有先天的符号处理机制。
相反,他们只是用归纳的原理说明深度学习的作用:「由于深度学习已经克服了 1 到 N 的问题,我们应该相信它可以克服 N+1 的问题」。
这种观点的说服力很弱,人们真正应该思考和质疑的是深度学习的极限。
其次,还有一些强有力的具体理由可以说明深度学习已经面临原则上的挑战,即组合性、系统性和语言理解问题。这些问题依赖于「泛化」和「分布偏移(distribution shift)」。领域内的每个人现在都认识到分布偏移是当前神经网络的致命弱点。这也是《代数思维》一书中对当今深度学习系统的先驱性观点。
实际上,深度学习只是构建智能机器的一部分。这类技术缺乏表征因果关系(例如疾病与其症状之间关系)的方法,并且可能在获取抽象概念方面存在挑战。深度学习没有明显的逻辑推理方式,距离整合抽象知识还有很长的路要走。
当然,深度学习已经取得了诸多进展,它擅长模式识别,但在推理等一些基本问题上进展还远远不够,系统仍然非常不可靠。
以谷歌开发的新模型
Minerva
为例,它在训练时有数十亿个 token,但仍然难以完成 4 位数字相乘的问题。它在高中数学考试中获得 50% 的正确率,却被吹嘘为「重大进步」。因此,深度学习领域仍很难搭建起一个掌握推理和抽象的系统。现在的结论是:不仅是深度学习有问题,而是深度学习「一直都有问题」。
在「代数思维」 20 年的影响下,当前的系统仍然无法可靠地提取符号处理(例如乘法),即使面对庞大的数据集和训练也是如此。人类婴幼儿的例子表明,在正规教育之前,人类是能够归纳复杂的自然语言和推理概念的(假定是符号性质的)。
一点内置的符号主义可以大大提高学习效率。LeCun 自己在卷积方面的成功(对神经网络连接方式的内置约束)很好地说明了这种情况。AlphaFold 2 的成功一部分源于精心构建的分子生物学的先天表征,模型的作用是另一部分。DeepMind 的一篇新论文表示,他们在构建关于目标的先天知识系统推理方面取得了一些进展。
而 LeCun 和 Browning 所说的都没有改变这一切。
在工厂完全安装了符号处理设备的系统(例如几乎所有已知的编程语言)。
具有先天学习装置的系统缺乏符号处理,但在适当的数据和训练环境下,足以获得符号处理。
即使有足够的训练,也无法获得完整的符号处理机制的系统。
当前深度学习系统属于第三类:一开始没有符号处理机制,并且在此过程中没有可靠的符号处理机制。
当 LeCun 和 Browning 意识到扩展的作用,即添加更多层、更多数据,但这是不够的,他们似乎同意我最近反对扩展的论点。我们三个人都承认需要一些新的想法。
此外,在宏观层面上,LeCun 最近的主张在很多方面都非常接近我在 2020 年的主张,即我们都强调感知、推理和拥有更丰富世界模型的重要性。我们都认为符号处理扮演着重要角色(尽管可能不同)。我们都认为目前流行的强化学习技术不能满足全部需求,单纯的扩展也是如此。
符号处理最大的不同在于需要固有结构的数量,以及利用现有知识的能力。符号处理希望尽可能多地利用现有知识,而深度学习则希望系统尽可能多地从零开始。
早在 2010 年代,符号处理在深度学习支持者中还是一个不受欢迎的词,21 世纪 20 年代,我们应该将了解这一方法来源作为首要任务,即使是神经网络最狂热的支持者已经认识到符号处理对实现 AI 的重要性。一直以来神经符号社区一直关注的问题是:如何让数据驱动的学习和符号表示在一个单一的、更强大的智能中协调一致地工作?令人兴奋的是,LeCun 最终承诺为实现这一目标而努力。
原文链接:https://www.noemamag.com/deep-learning-alone-isnt-getting-us-to-human-like-ai/
WAIC黑客马拉松——蚂蚁财富双赛道
行情波动下的金融问答挑战赛
该赛道在财富社区的问答数据基础上,针对每个用户的问题,利用检索、深度学习、自然语言处理等技术,生成出流畅、准确、合理的针对该问题的回答。
AntSQL大规模金融语义解析中文Text-to-SQL挑战赛
该赛道采用金融领域的表格作为数据源,涵盖了基金的产品和属性,提供在此基础上的标注的Query-SQL对,希望选手们能在此基础上训练深度学习模型,将自然语言准确的转换为可查询的SQL语句。
-
-
-
获奖选手受邀参加2022世界人工智能大会WAIC · AI开发者日举行的颁奖典礼 ;
-
优秀选手有机会获得Offer绿色通道,入职蚂蚁财富认知智能团队;
-
邀请好友参赛即可获得
扫地机器人、空气炸锅,欢迎加入钉钉群了解详情。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com