图灵奖得主Yann LeCun:最新《自主人工智能之路》报告,附视频与70页ppt
转载机器之心
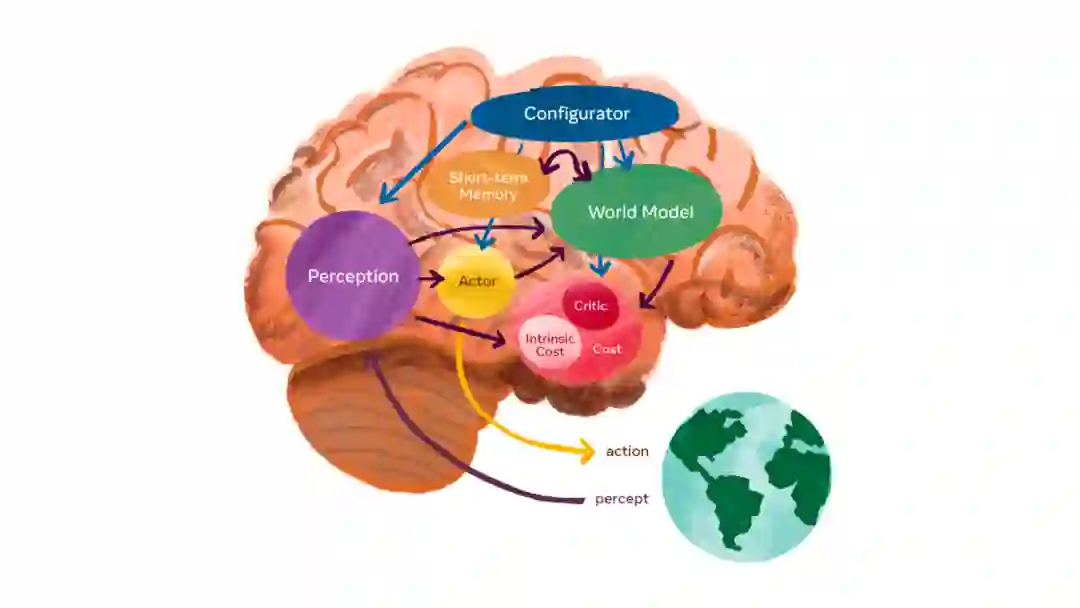
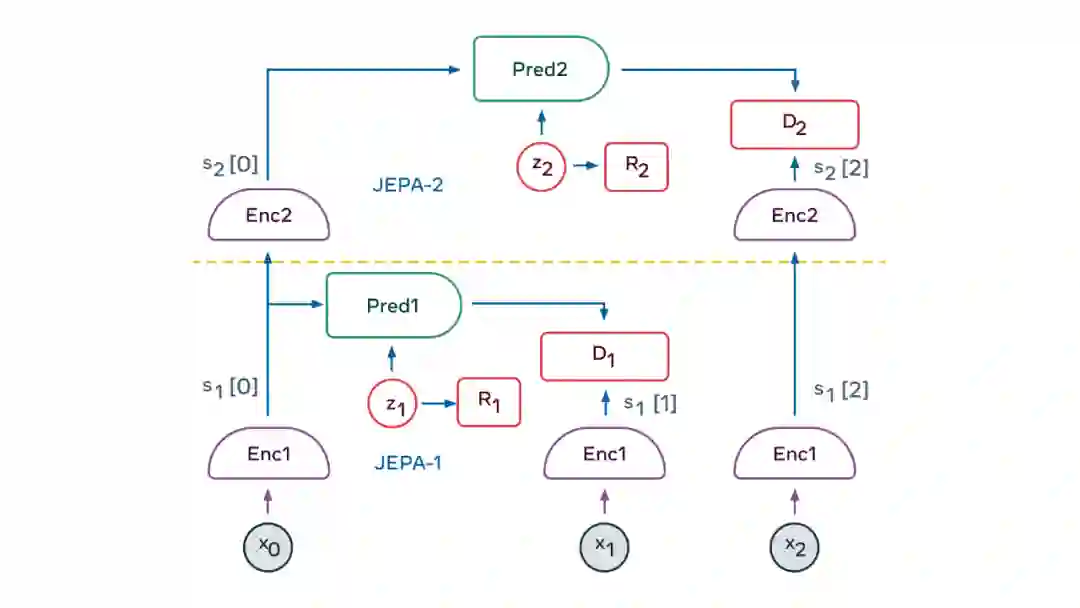
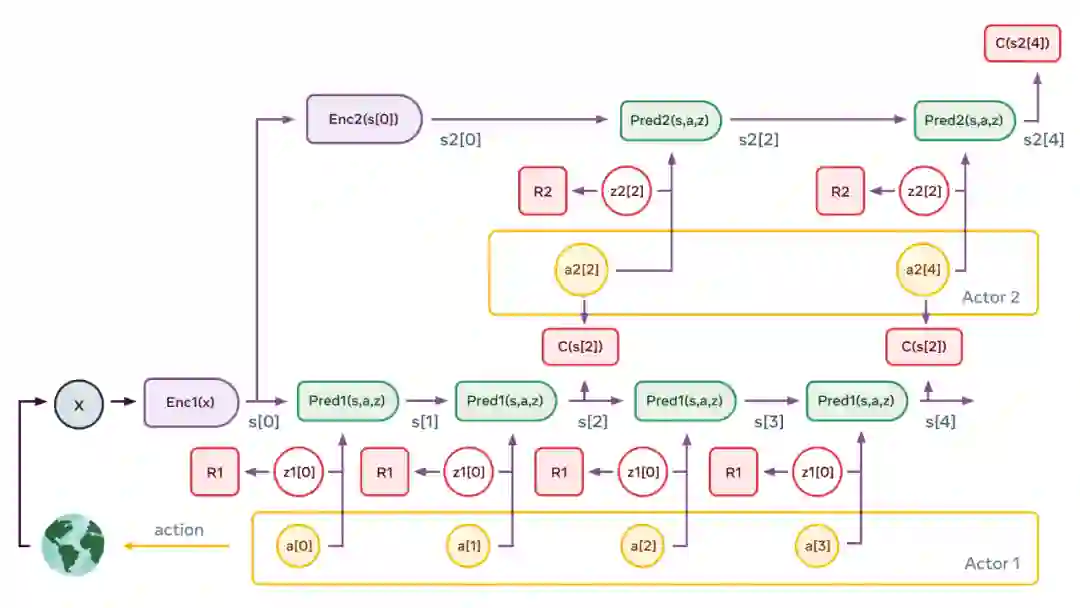
LeCun 认为,构造自主 AI 需要预测世界模型,而世界模型必须能够执行多模态预测,对应的解决方案是一种叫做分层 JEPA(联合嵌入预测架构)的架构。该架构可以通过堆叠的方式进行更抽象、更长期的预测。LeCun 和 Meta AI 希望分层 JEPA 可以通过观看视频和与环境交互来了解世界是如何运行的。


原视频链接:https://www.youtube.com/watch?v=DokLw1tILlw
PPT 链接:https://drive.google.com/file/d/1Txb9ykr03Lda-oTLXbnlQsEe46V8mGzi/view


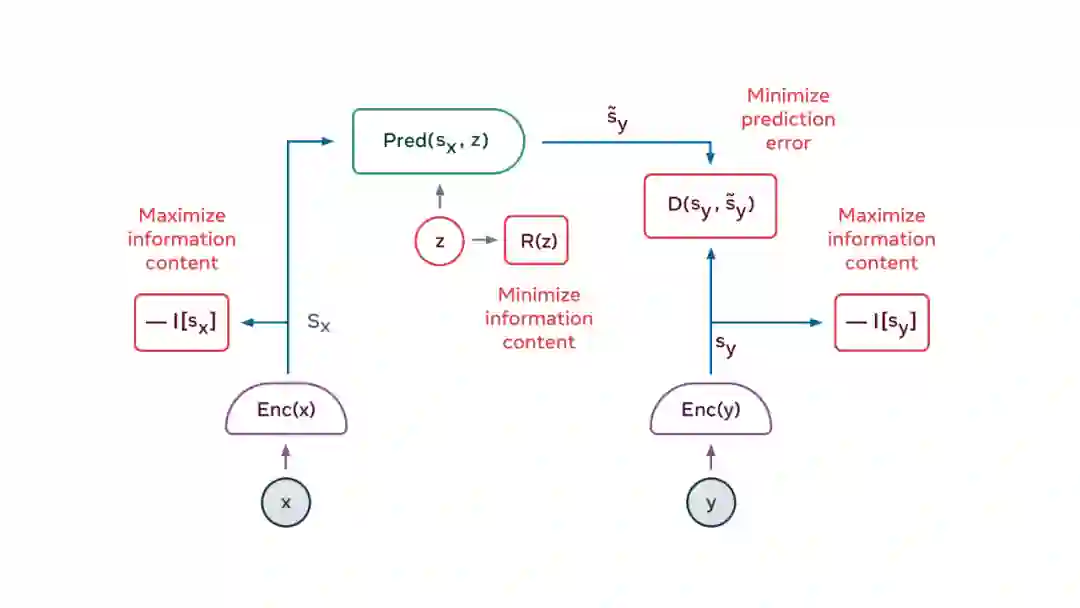
使 x 的表示最大限度地提供关于 x 的信息
使 y 的表示最大限度地提供关于 y 的信息
使得从 x 的表示中最大限度地预测 y 的表示成为可能
让预测器使用来自潜变量的、尽可能少的信息来表示预测中的不确定性。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“AI70” 就可以获取《图灵奖得主Yann LeCun:最新《自主人工智能之路》报告,附视频与70页ppt》专知下载链接



登录查看更多
相关内容
Arxiv
0+阅读 · 2022年4月20日



相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月20日