CVPR 2018机器学习图像压缩挑战揭晓
在这个数字时代,显而易见,图像压缩极为重要——如果完全不进行压缩,500万像素的彩色图像需要15兆空间存储,对于大多数网站和移动应用而言,这都太大了。自上世纪80年代引入JPEG以来,信号处理社区在图像压缩方面取得了许多明显的进展,包括最近提出的现代图像编解码技术(例如,BPG和WebP)。不过,很大程度上,这些现代编解码器,使用的仍然是与JPEG类似的像素转换技术。
2016年,Ballé等基于Generalized Divisive Normalization网络层的工作(arXiv:1607.05006),Toderici等基于循环神经网络的工作(arXiv:1608.05148),标志着基于神经网络的图像压缩技术,首次取得与JPEG相当乃至略优的表现。
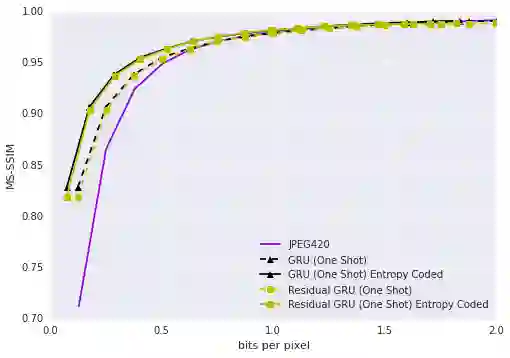
Toderici等提出的基于循环网络的图像压缩方法,表现与JPEG相当
2017年,这一领域发展迅速。Ballé等基于卷积过滤器和非线性激活的工作(arXiv:1611.01704),Theis等基于自动编码器的工作(arXiv:1703.00395)以及Agustsson等的改进(使用soft-to-hard熵最小化方法训练,arXiv:1704.00648),Santurkar等基于生成式模型的工作(arXiv:1703.01467),Rippel等基于自动编码器和对抗训练的工作(arXiv:1705.05823),表现渐渐超越了现代图像压缩的工业标准。

Rippel等,2017
一方面,这一领域进展迅速,另一方面,高分辨率手机图像和专门硬件(例如,GPU)的流行,意味着这一领域具有广阔的应用前景。为了鼓励这一领域的进展,吸引更多机器学习社区的关注,Google、ETH、Twitter、Amazon、Disney Research、Netflix联合赞助了CVPR 2018的学习图像压缩挑战(CLIC)。
数据集
目前,评测学习图像压缩(learned image compression)的常用标准为:
Kodak PhotoCD数据集,图像分辨率768x512,约40万像素;
Tecnick数据集,约一百四十万像素。
而本次挑战提供了更贴近实际应用场景的数据集,图像类别广泛,分辨率不等(512至2048),文件尺寸不等(几百K到几M),并分为专业(Dataset P)、移动端(Dateset M)两部分。数据集由赞助方之一的ETH(苏黎世联邦理工学院)提供,分训练集(P 1.9GB、M 3.8GB)、验证集(P 129MB、M 226MB)、测试集(P 365 MB、M 645MB)。当然,除了使用CLIC官方提供的训练集外,参加挑战的团队还可以使用其他数据进行训练(如ImageNet)。

CLIC图像数据集
挑战参加者需要提交压缩后的图像,以及配套的解码器(CLIC提供了官方的docker镜像,作为解码器运行环境)。另外,还需要提交一份不超过4页的算法描述(之所以限定不超过4页,是为了不影响挑战参加者在其他场合发表相关论文,例如,CVPR 2018规定论文长度需要超过4页)。
评估标准
CLIC使用的评估指标是PSNR、MS-SSIM、MOS,这些是业界通用的图像质量评估(Image Quality Assessment,IQA)标准。下面我们将简单介绍一下这些指标。
评估图像质量,最简单直接的方法,就是人工评分。为了尽量减少误差,可以多找些人,取评分的均值。这就是平均主观得分(Mean Opinion Score),简称MOS。
然而,MOS有两个问题:
成本高昂,耗时漫长。
影响因素多。比如显示设备、照明条件、评分员的视力状况,都可能影响评分。另外,一些擅长“编造”细节(生成原图中不存在,但看起来很逼真的细节)的算法(比如GAN)的评分容易出现偏高的现象。
因此,除了主观评分,我们还需要客观评分指标。
就图像压缩而言,我们有原图作为标准,属于全参考图像评估(Full Reference Image Quality Assessment),简称FR-IQA。这类评估着重比较和原图的差异。
比较和原图的差异,最容易想到的方法就是逐像素比较。由于像素之差可能是正值,也可能是负值,为了避免正负抵消,因此我们取一下平方。最后,取下均值就可以了。这称为均方误差(Mean-Square Error,MSE)。
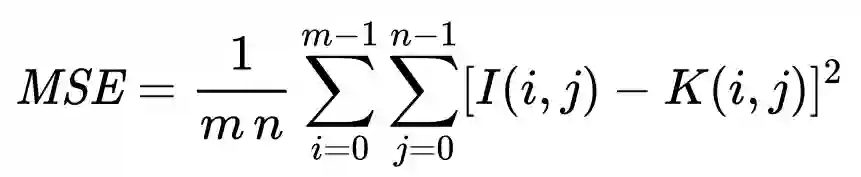
对同一规格的图像而言,可以直接使用均方误差。但要比较不同规格的图像,直接使用均方误差有所不妥。比如,纯黑白图像,非黑即白,每个像素的值要么是1,要么是0,而通常所谓的黑白图像,其实是8位的灰度图像,每个像素的值在0到255之间。同样的MSE值,对这两种规格的图像而言,意义大不一样。因此,我们还需要将每个像素的取值范围(动态范围)纳入指标,也就是MAXI,像素可能值的最大值。
纳入MAXI后,再取下对数(因为在图像之外的某些场景中,信号可能有非常大的动态范围),我们就得到了峰值信噪比(Peak Signal-to-Noise Ratio),简称PSNR。
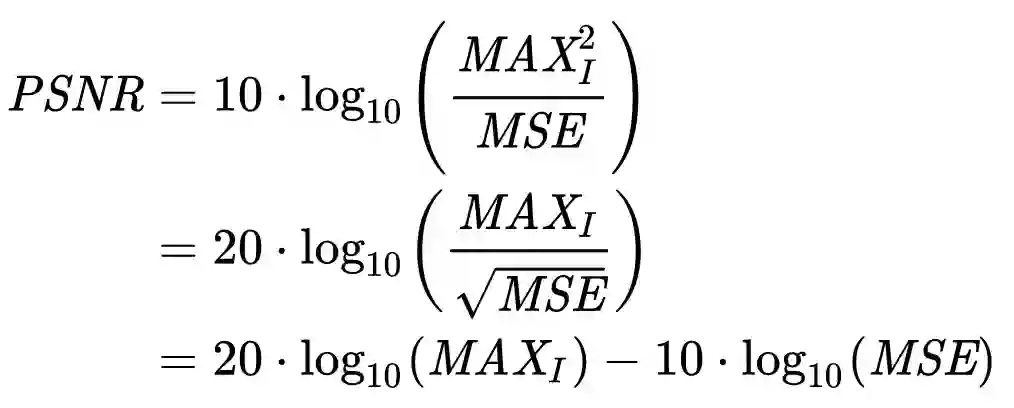
PSNR是非常简单明了的方法,计算起来也很快,因此得到了广泛应用。然而,PSNR基本上是直接比较像素的差异,没有考虑到人眼对不同类别的差异的敏感程度不同。
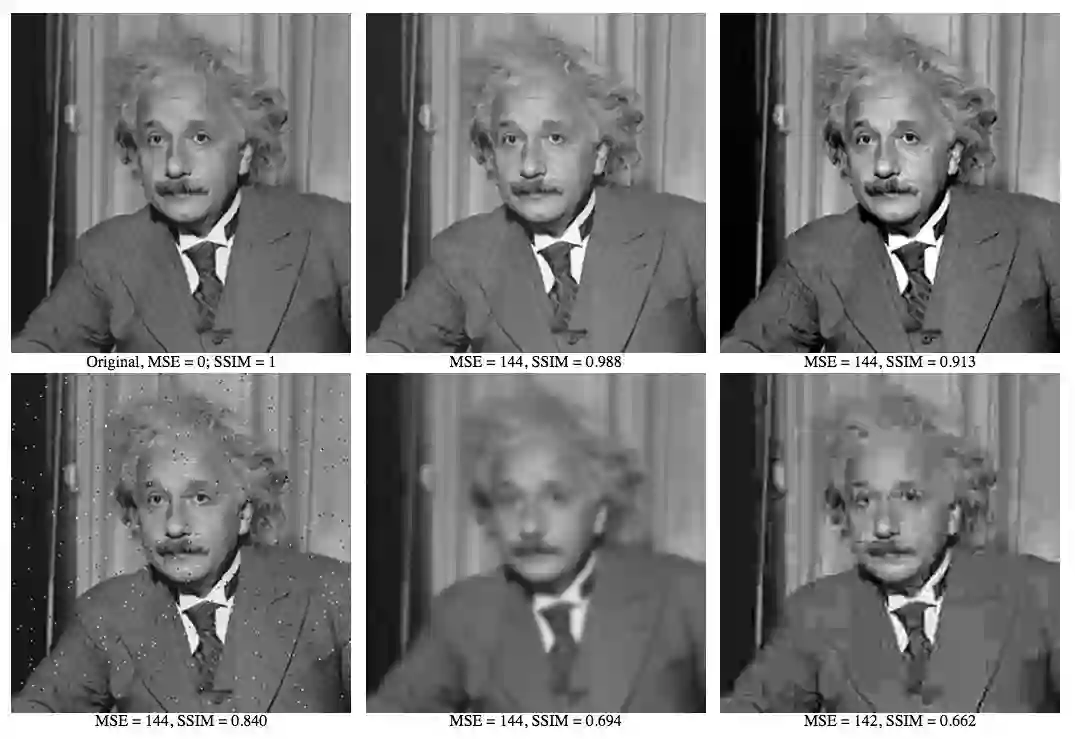
例如,上面的爱因斯坦照片PSNR值相等,但主观感觉质量差异非常大。
由此,德州大学的LIVE(Laboratory for Image and Video Engineering)实验室提出了新的结构相似性(structural similarity)指标,简称SSIM。
SSIM的主要思路是,将人类主观感知纳入考量:
在非常亮的区域,失真更难以察觉。(luminance,亮度)
在“纹理”比较复杂的区域,失真更难以察觉。(contrast,对比)
空间上相邻的像素之间形成某种“结构”,而人眼对这种结构信息很敏感。(structure,结构)
具体而言,SSIM通过以下公式测度以上三者:
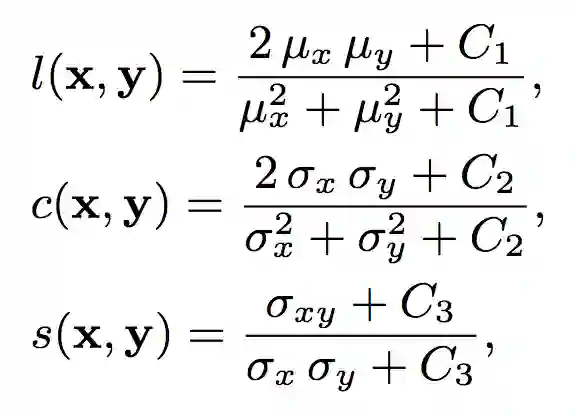
上式中,μ为均值,σ为方差,C1、C2、C3为对SSIM进行微调的常数。C1、C2、C3满足以下关系:
C1 = (K1L)2,C2 = (K2L)2,且C3 = C2/2.
其中,L为像素的动态范围,对8位灰阶图像而言,L = 255. K1、K2远小于1,默认情况下,K1 = 0.01,K2 = 0.03.
由此,SSIM的计算公式为:
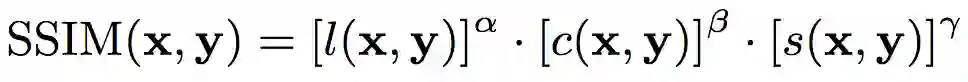
通常,我们认为以上三个因素对主观感受的影响效应相似,故取α = β = γ = 1. 通常我们使用下式计算SSIM:
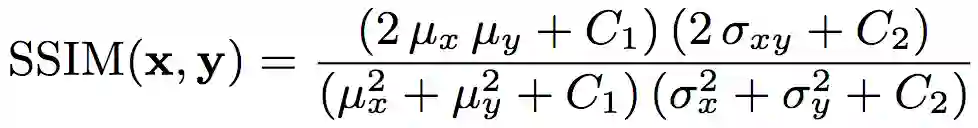
从SSIM的定义,我们可以看到SSIM满足以下性质:
对称:SSIM(x, y) = SSIM(y, x)
有界:SSIM(x, y) <= 1
唯一最大值:当且仅当x = y时,SSIM(x, y) = 1
另外,应用SSIM指标时,我们使用滑窗法。
SSIM考虑了亮度、对比、结构因素,然而,还有一个主观因素没有考虑,分辨率。显然,在不同分辨率下,人眼对图像差异的敏感程度是不一样的。比如,在高分辨率的视网膜显示器上显而易见的失真,在低分辨率的手机上可能难以察觉。因此,后来又进一步提出了MS-SSIM指标,即多尺度(Multi-Scale)SSIM。对图像进行降采样处理,在多尺度上分别计算对比比较和结构比较,最后汇总多尺度上的SSIM分数。
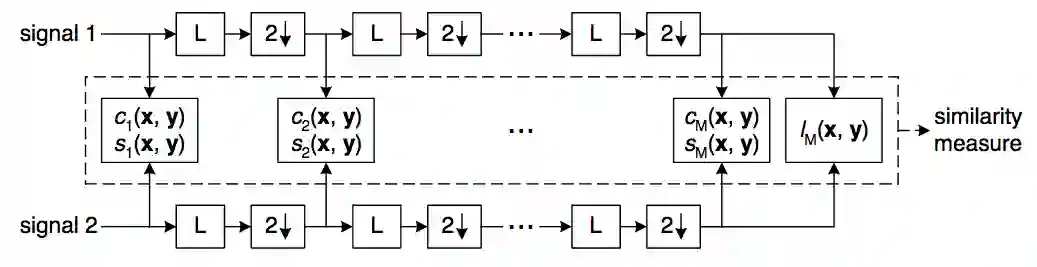
MS-SSIM过程示意图
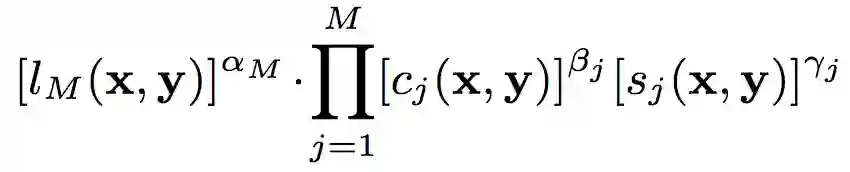
MS-SSIM计算公式
当然,尽管MS-SSIM有很多优势,但尚不足以取代PSNR。主要有两个原因:
速度。Nafchi等在Core i7 3.40GHz CPU,16GB内存的机器上运行的评测表明,对于1080x1920的图像而言,计算PSNR需要37.85毫秒,而计算MS-SSIM需要413.70毫秒。(arXiv:1608.07433)注意,这两种指标是在MATLAB 2013b上实现的,运行环境为Windows 7。不同实现和环境下,两者的差距可能会缩小。然而,不管怎么说,算法的定义决定了,MS-SSIM的计算要比PSNR复杂不少。
在许多场景下,MS-SSIM未必优于PSNR。Lin Zhang等在2011年的评测(FSIM)表明,在各图像数据集的不同失真类型上,MS-SSIM的效果不一定优于PSNR(当然,在JPEG压缩类型的失真上,MS-SSIM还是体现了明显的优势)。
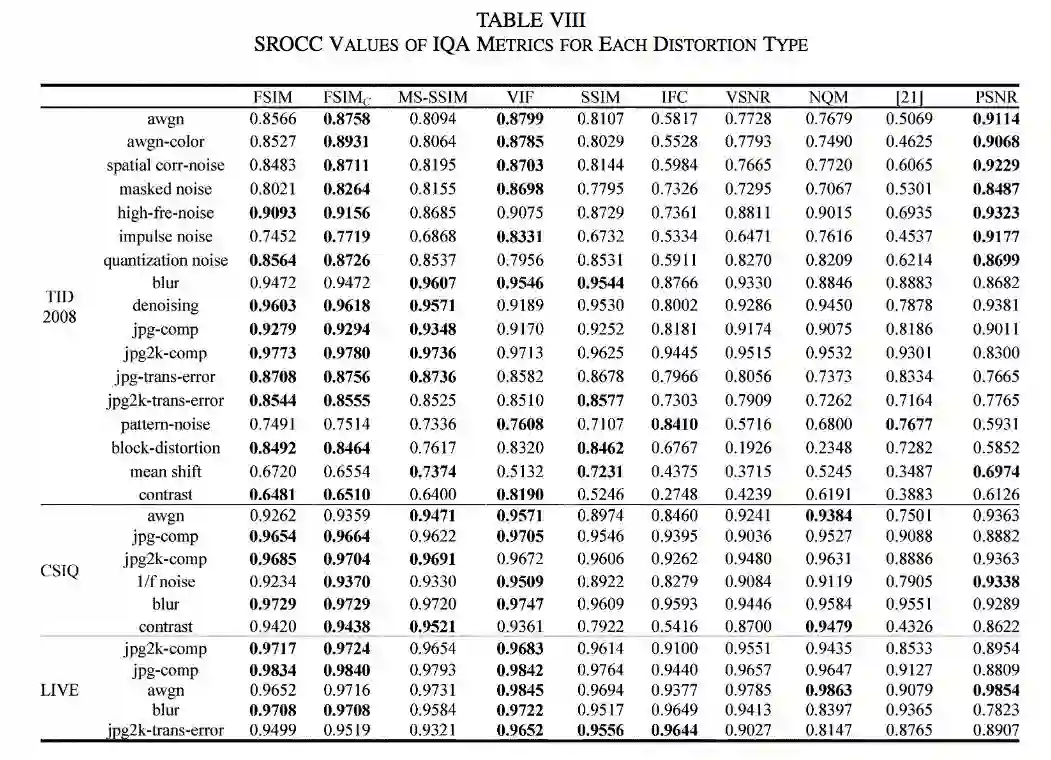
不同IQA指标的SROCC评分,分数越高越好
挑战结果
CLIC于上月底(5月31日)揭晓了结果,有三个团队获得优胜,将瓜分超过6000美元的奖金。
TucodecTNGcnn4p,主观指标MOS和客观指标MS-SSIM均为第一。
iipTiramisu,PSNR第一。
xvc,评分较高的团队中,xvc的解码速度最快。
TucodecTNGcnn4p基于端到端的深度学习算法,其中使用了层次特征融合的网络结构,以及新的量化方式、码字估计技术。
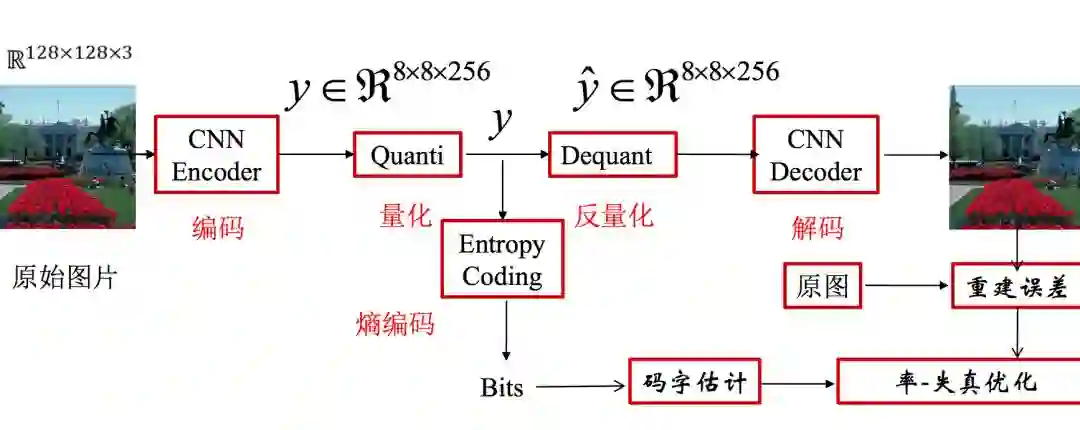
端到端深度学习图像压缩框架;图片来源:Tucodec
TucodecTNGcnn4p团队来自图鸭科技,一家专注于图像视频通信、压缩与分析的初创公司。论智很荣幸地邀请到了周雷博士,图鸭科技深度学习算法研究员,于6月14日(下周四)19:30开一场线上公开课,主题为深度学习之视频图像压缩。如有兴趣了解如何在视频图像领域应用深度学习,欢迎扫描下方二维码报名。

扫描添加论智君微信,发送“公开课”





