【干掉英伟达?】DeepMind CEO哈萨比斯投资的AI芯片,性能超越GPU 100倍

【AI WORLD 2017世界人工智能大会倒计时 12 天】
“AI达摩”齐聚世界人工智能大会,AI WORLD 2017议程嘉宾重磅发布
2017年11月8日,北京国家会议中心举办的AI World 2017世界人工智能大会,AI Vision会场,我们请到了中国自动化学会副理事长王飞跃、英特尔中国研究院院长宋继强、三星电子中国研究院院长张代君、爱奇艺CTO汤兴等技术和产业领袖参与圆桌讨论。想要现场感受顶级科学家风采,当面请教技术问题?点击阅读原文或扫描文末二维码,马上参会!
抢票链接:http://www.huodongxing.com/event/2405852054900?td=4231978320026
大会官网:http://www.aiworld2017.com
新智元编译
来源:graphcore.ai
作者:Dave Lacey 编译:马文
【新智元导读】被DeepMind联合创始人哈萨比斯投资的AI芯片公司 Graphcore,宣称自己的IPU芯片相比市场同类产品性能提升10~100倍,并且在训练和推理两方面都同样出色。现在他们发布初步的测试基准证实他们的宣言,对比GPU,在某些任务上IPU的性能提升甚至超过200倍。

Graphcore 的 IPU(Intelligence Processing Unit,智能处理单元)是一种新的AI加速器,为当前和未来的机器学习工作负载带来了前所未有的性能水平。它的独特的大规模并行多任务计算、单个IPU或跨多个IPU的同步执行、创新的数据交换结构和大量片上SRAM的组合,在各类的机器学习算法中同时为训练过程和推理过程提供了前所未闻的性能。
这家公司的投资人包括DeepMind联合创始人哈萨比斯、Uber首席科学家Zoubin Ghahramani,OpenAI的Greg Brockman等。企业投资则来自Atomico、戴尔、三星等。
Graphcore的目标是成为“机器智能处理器市场的领导者”,这家公司的产品叫做IPU(intelligence processing unit)智能处理单元。Graphcore首席执行官Nigel Toon曾经在2011年把当时的公司卖给英伟达,现在,他们正式走上舞台与英伟达展开竞争。
在昨天发表的官方博客中,Graphcore表示,当我们在2016年10月公布我们的A轮融资时,我们就IPU的性能作了3点声明:
与其他AI加速器相比,它的性能提升了10倍至100倍
它在训练和推理两方面都同样出色
它让机器学习开发者得以在模型和算法方面进行创新,这些模型和算法即使在当前最好的替代架构上也不工作
自那时起,我们一直被要求提供更多关于这些声明的细节。今天,我们很高兴地分享3个证实这些早期目标的初步基准。
我们从一开始就明白,一个完整的解决方案需要的不仅仅是新的芯片设计。软件基础设施需要全面、易于使用,以便机器学习开发者能够快速使硬件适应他们的需要。因此,我们一直致力于提供一个完整的软件堆栈,以确保IPU从一开始就可以用于实际的应用程序。
我们的 Poplar® 图形编程框架和应用程序库提供了这些功能。我们已经开发一个 TensorFlow 的端口以使 Poplar 库支持其他机器学习框架。有了这些软件工具,我们可以通过周期精确的芯片模拟和真正的硬件来运行各种各样的实际应用。
有了这个实验平台,我们可以执行一系列不同的机器学习应用程序,并从IPU系统的初步性能结果的粗略估计得到改进,当我们有生产系统时,IPU 系统将能够进一步改善。
卷积神经网络(CNN)在图像处理任务中有广泛的应用。一个典型的CNN模型包含执行多个卷积运算的几个层。卷积运算具有必须从训练算法学习的参数。训练通常通过随机梯度下降法进行,包括在图像数据上反复地运行模型,计算模型的梯度,然后更新模型的参数。
在训练机器学习模型时,batch size是需要与当前参数组并行处理的数据项数。batch size 限制了更新这些参数的频率,因为必须在更新之前处理整个批。过大的 batch size 可能不适合训练你的模型。IPU系统的一个特性是,即使对于较小的 batch size,它们的性能也很好。
下面的图表显示了在 ImageNet 数据集训练 ResNet-50 这个神经网络来学习图像分类时的估计性能,以每秒训练的图像数量计算:
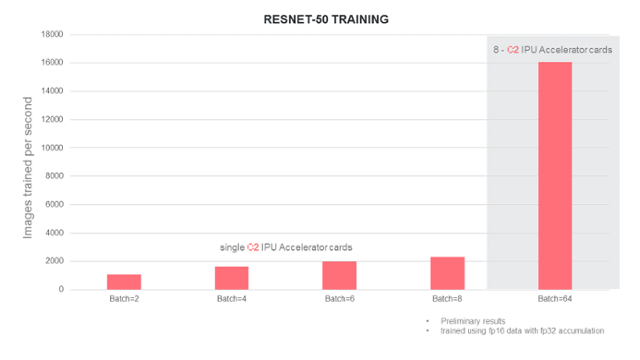
即使在较小的 batch size 下,性能提升也很可观。当我们扩展到使用8个C2加速器卡时,只使用了 batch size=64。
在这个空间的任何一点上,使用IPU系统的性能相对于现有技术都是巨大的飞跃。例如,使用300W GPU加速器(与C2加速器相同的功率预算)的话,有记录的最佳性能是每秒约580张图像。
循环神经网络(Recurrent networks)用于处理序列数据,例如在语言翻译或文本转语音(text-to-speech)的应用中。LSTM(long short-term memory,长短期记忆)网络是循环神经网络的一种形式,它包含几个不同的元素,用于选择在产生输出时是否要记住或忘记正在处理的序列的历史数据。
所有循环神经网络都具有对当前芯片架构来说是一个挑战的数据依赖(data dependency)。数据依赖限制了可用的并行数量,并且从内存中获取的每个数据的操作数量也受到限制。IPU 和 Poplar 库可以更好地处理这些限制,因为它们可以获得大量片上内存,并且IPU中计算和数据移动具有灵活性。
对于执行推断的服务器,将会有时延约束,即从请求推断到获得结果所需的最小时间。下面的图表显示了IPU与GPU相比,对于不同的时延约束,单层LSTM网络的性能:

这个单层LSTM的参数来自百度DeepBench套件,该套件描述了在深度学习应用程序中使用的典型循环神经网络层。
最后我们来看一下生成神经网络。这是每次产生新的数据的循环神经网络。具体来说,WaveNet网络每次会生成一个音频波形,以提供文本转语音的功能。以下我们会讨论 Deep Voice,这是 WaveNet 的一个变体。
我们的应用实验已经考虑了两类性能指标。首先,样本的生成速度怎么样?具体来说,样本需要足够快地生成,以形成实时音频流(例如16Khz)。如果可以生成实时音频流,我们就可以考虑一次可以产生多少个频道(生成不同的语音)。
下面的图表显示了IPU与原始论文的其他平台相比,Deep Voice 生成算法的性能:
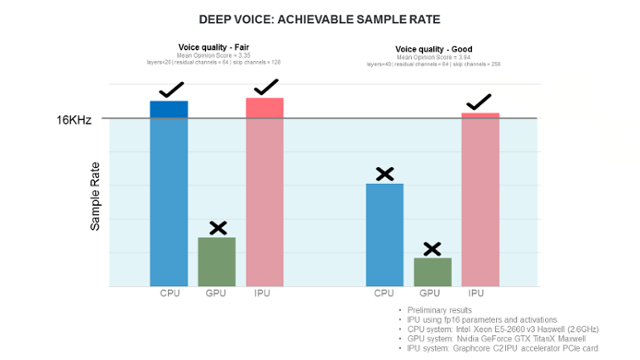
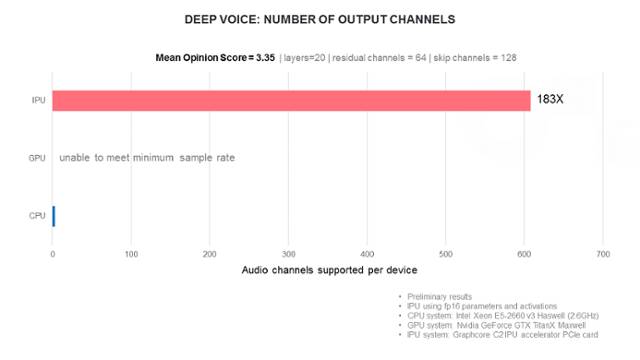
这些应用都仅是初尝者。IPU和Poplar软件栈提供了一个完全灵活、可编程的平台。我们很期待用户在未来几年将会为这个平台带来什么样的应用。
随着产品发布的临近,我们开始与早期客户共享Poplar 框架,我们将在接下来的几个月里公开文档和代码。
原文:https://www.graphcore.ai/posts/preliminary-ipu-benchmarks-providing-previously-unseen-performance-for-a-range-of-machine-learning-applications
深入了解AI 技术进展和产业情况,参加新智元世界人工智能大会,马上抢票!

【AI WORLD 2017世界人工智能大会倒计时 12 天】点击图片查看嘉宾与日程。
抢票链接:http://www.huodongxing.com/event/2405852054900?td=4231978320026
AI WORLD 2017 世界人工智能大会购票二维码:



