选自assemblyai
作者:Ryan O'Connor
机器之心编译
编辑:蛋酱
2022 年 4 月初,OpenAI 的开创性模型 DALL-E 2 登场,为图像生成和处理领域树立了新的标杆。只需输入简短的文字 prompt,DALL-E 2 就可以生成全新的图像,这些图像以语义上十分合理的方式将不同且不相关的对象组合起来,就像通过输入 prompt「a bowl of soup that is a portal to another dimension as digital art」,便生成了下面的图像。
![]()
DALL-E 2 甚至可以修改现有图像,创建处保有其显著特征的图像变体,并在两个输入图像之间进行插值。DALL-E 2 令人印象深刻的结果让许多人想知道,这样一个强大的模型究竟是如何工作的。
在本文中,我们将深入了解 DALL-E 2 如何创造出众多令人惊艳的图像。将提供大量背景信息,并且解释级别将涵盖范围,因此本文适合具有多个机器学习经验级别的读者。
1. 首先,DALL-E 2 展示了深度学习中扩散模型(Diffusion Model)的强大功能,因为 DALL-E 2 中的先验和图像生成子模型都是基于扩散的。虽然在过去几年才开始流行,但扩散模型已经证明了自身价值,一些关注深度学习研究的人也期望在未来看到更多进展。
2. 其次,展示了使用自然语言作为训练深度学习 SOTA 模型的手段的必要性和力量。这一点并非源于 DALL-E 2,但重要的是认识到, DALL-E 2 的力量是源于可在互联网上获得大规模匹配的自然语言 / 图像数据。使用这些数据消除了手动标注数据集的高成本和相关瓶颈,但这类数据嘈杂、未经处理的性质也反映了深度学习模型必须具备面对真实数据的鲁棒性。
3. 最后,DALL-E 2 重申了 Transformer 的地位,鉴于它们具有令人印象深刻的并行性,因此对于在网络规模数据集上训练的模型来说是至高无上的。
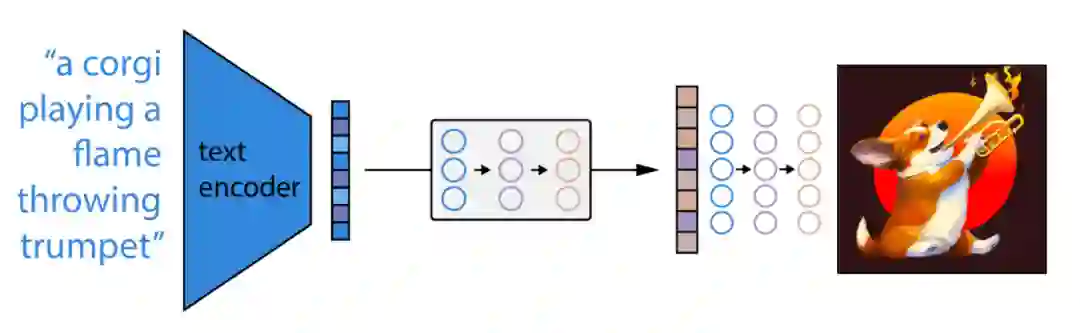
在深入了解 DALL-E 2 的工作原理之前,让我们先大致了解一下 DALL-E 2 如何生成图像。虽然 DALL-E 2 可以执行各种任务,包括上面提到的图像处理和插值,但我们将在本文中专注于图像生成任务。
![]()
1. 首先,将文本 prompt 输入到经过训练以将 prompt 映射到表征空间的文本编码器中;
2. 接下来,称为先验的模型将文本编码映射到相应的图像编码,该图像编码捕获文本编码中包含的 prompt 的语义信息;
3. 最后,图像解码模型随机生成图像,该图像是该语义信息的视觉表现。
从鸟瞰的角度来看,这就是它的全部了。当然,还有很多有趣的实现细节,我们将在下面讨论。
现在是时候分别深入了解上述每个步骤了。让我们先来看看 DALL-E 2 如何学会链接相关的文本和视觉概念。
输入「泰迪熊在时代广场骑滑板」后,DALL-E 2 输出如下图像:
![]()
DALL-E 2 怎么知道像「泰迪熊」这样的文本概念,应该在视觉空间中如何体现?DALL-E 2 中的文本语义与其视觉表征之间的联系是由另一个名为 CLIP 的 OpenAI 模型学习的。
CLIP 接受了数亿张图像及其相关标题的训练,以了解给定文本片段与图像的关联程度。也就是说,CLIP 不是试图预测给定图像的标题,而是学习任何给定标题与图像的相关程度。这种对比而非预测的目标使 CLIP 能够学习同一抽象目标的文本和视觉表示之间的联系。整个 DALL-E 2 模型取决于 CLIP 从自然语言中学习语义的能力,所以让我们看看如何训练 CLIP 以了解其内部工作原理。
1. 首先,所有图像及其相关标题都通过它们各自的编码器,将所有对象映射到一个 m 维空间。
2. 然后,计算每个(图像,文本)对的余弦相似度。
3. 训练目标是同时最大化 N 个正确编码图像 / 标题对之间的余弦相似度,并最小化 N 2 - N 个不正确编码图像 / 标题对之间的余弦相似度。
![]()
CLIP 对 DALL-E 2 很重要,因为它最终决定了自然语言片段与视觉概念的语义相关程度,这对于 text-conditional 图像生成至关重要。
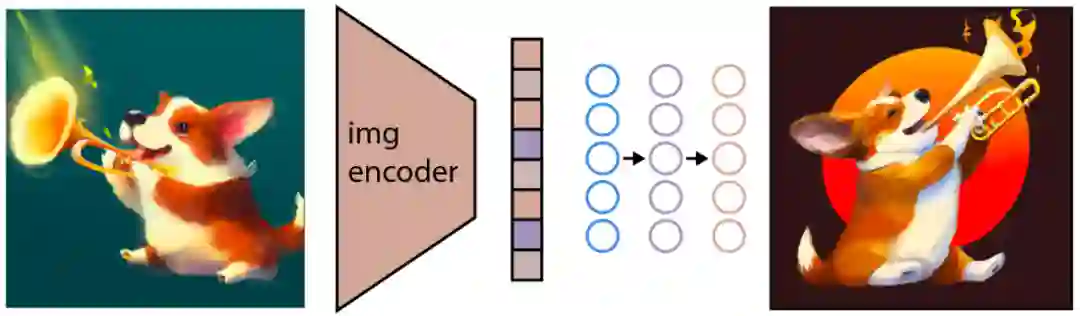
训练后,CLIP 模型被冻结,DALL-E 2 进入下一个任务——学习反转 CLIP 刚刚学习的图像编码映射。CLIP 学习了一个表征空间,在该空间中,很容易确定文本和视觉编码的相关性,但我们的兴趣在于图像生成。因此,我们必须学习如何利用表征空间来完成这项任务。
特别是,OpenAI 使用其先前模型 GLIDE (https://arxiv.org/abs/2112.10741) 的修改版本来执行此图像生成。GLIDE 模型学习反转图像编码过程,以便随机解码 CLIP 图像嵌入。
![]()
如上图所示,应该注意的是,目标不是构建一个自动编码器并在给定嵌入的情况下准确地重建图像,而是生成一个在给定嵌入的情况下保持原始图像显著特征的图像。为了执行这个图像生成,GLIDE 使用了一个扩散模型。
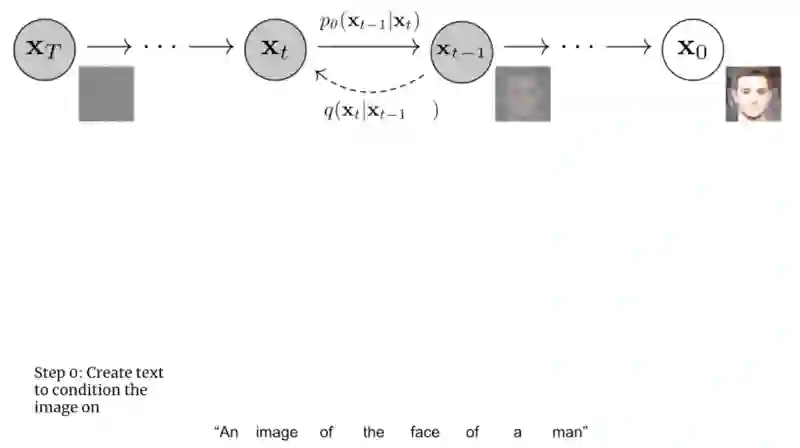
扩散模型是一项受热力学启发的发明,近年来已显著普及。扩散模型通过反转逐渐的噪声过程来学习生成数据。如下图所示,噪声过程被视为一个参数化的马尔可夫链,它逐渐向图像添加噪声以破坏图像,最终(渐近地)产生纯高斯噪声。扩散模型学习沿着这条链向后导航,在一系列时间步长上逐渐消除噪声以逆转这一过程。
![]()
如果然后将扩散模型在训练后「一分为二」,则可以使用它通过随机采样高斯噪声来生成图像,然后对其进行去噪以生成逼真的图像。有些人可能会认识到,这种技术很容易让人联想到使用自编码器生成数据,而扩散模型和自动编码器实际上是相关的。
虽然 GLIDE 不是第一个扩散模型,但它的重要贡献在于修改了它们以允许生成文本条件图像。特别是,人们会注意到扩散模型从随机采样的高斯噪声开始。起初,还不清楚如何调整此过程以生成特定图像。如果在人脸数据集上训练扩散模型,它将可靠地生成逼真的人脸图像;但是如果有人想要生成一张具有特定特征的脸,比如棕色的眼睛或金色的头发怎么办?
GLIDE 通过使用额外的文本信息增强训练来扩展扩散模型的核心概念,最终生成 text-conditional 图像。我们来看看 GLIDE 的训练过程:
![]()
以下是使用 GLIDE 生成的图像的一些示例。作者指出,在照片写实和字幕相似性方面,GLIDE 的性能优于 DALL-E。
![]()
DALL-E 2 使用修改后的 GLIDE 模型以两种方式使用投影的 CLIP 文本嵌入。第一种是将它们添加到 GLIDE 现有的时间步嵌入中,第二种是通过创建四个额外的上下文 token,它们连接到 GLIDE 文本编码器的输出序列。
GLIDE 对 DALL-E 2 很重要,因为它允许作者通过在表示空间中调整图像编码,轻松地将 GLIDE 的文本条件照片级逼真图像生成功能移植到 DALL-E 2 。因此,DALL-E 2 修改后的 GLIDE 学习生成以 CLIP 图像编码为条件的语义一致的图像。还需要注意的是,反向扩散过程是随机的,因此通过修改后的 GLIDE 模型多次输入相同的图像编码向量很容易产生变化。
虽然修改后的 GLIDE 模型成功地生成了反映图像编码捕获的语义的图像,但我们如何实际去寻找这些编码表征?换句话说,我们如何将 prompt 中的文本条件信息注入图像生成过程?
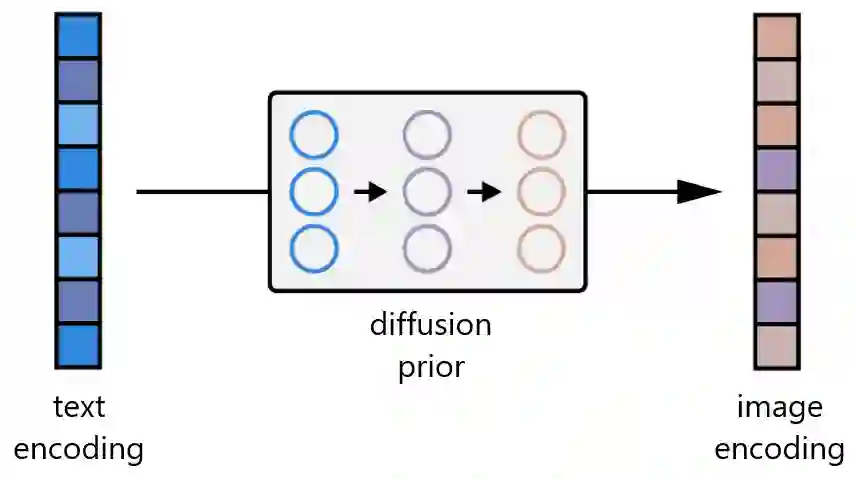
回想一下,除了我们的图像编码器,CLIP 还学习了一个文本编码器。DALL-E 2 使用另一个模型,作者称之为先验模型,以便从图像标题的文本编码映射到其相应图像的图像编码。DALL-E 2 作者对先验的自回归模型和扩散模型进行了实验,但最终发现它们产生的性能相当。鉴于扩散模型的计算效率更高,因此它被选为 DALL-E 2 的先验模型。
![]()
DALL-E 2 中的扩散先验由一个仅有解码器的 Transformer 组成。它使用因果注意力 mask 在有序序列上运行:
5. 最终编码,其来自 Transformer 的输出用于预测无噪声 CLIP 图像编码。
至此,我们拥有了 DALL-E 2 的所有功能组件,只需将它们链接在一起即可生成文本条件图像:
1. 首先,CLIP 文本编码器将图像描述映射到表征空间。
2. 然后扩散先验从 CLIP 文本编码映射到相应的 CLIP 图像编码。
3. 最后,修改后的 GLIDE 生成模型通过反向扩散从表征空间映射到图像空间,生成许多可能的图像之一,这些图像在输入说明中传达语义信息。
![]()
1. Deep Unsupervised Learning using Nonequilibrium Thermodynamics (https://arxiv.org/abs/1503.03585)
2. Generative Modeling by Estimating Gradients of the Data Distribution (https://arxiv.org/abs/1907.05600)
3. Hierarchical Text-Conditional Image Generation with CLIP Latents (https://arxiv.org/pdf/2204.06125.pdf)
4. Diffusion Models Beat GANs on Image Synthesis (https://arxiv.org/abs/2105.05233)
5. Denoising Diffusion Probabilistic Models (https://arxiv.org/pdf/2006.11239.pdf)
6. Learning Transferable Visual Models From Natural Language Supervision (https://arxiv.org/pdf/2103.00020.pdf)
7. GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models (https://arxiv.org/pdf/2112.10741.pdf)
原文链接:https://www.assemblyai.com/blog/how-dall-e-2-actually-works/
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com