学完文本知识,我就直接看懂图片了!

文 | Yimin_饭煲
2020年, OpenAI的大作GPT-3 (Language Models are few shot learners) 横空出世,震惊整个NLP/AI圈。大家在惊叹于GPT-3 1750B参数的壕无人性同时,想必对GPT-3中的Prompt方法印象深刻。简单来说,(GPT-3中的)Prompt就是为输入的数据提供模板(例如对于翻译任务 Translate English to Chinese:),在冻结语言模型参数的情况下让自回归语言模型输出答案。关于Prompt方法的具体介绍,大家可以参考CMU最新发布在arxiv上的综述 (Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing)。卖萌屋之前也转载过该论文的中文解析 《Fine-tune之后的NLP新范式:Prompt越来越火,CMU华人博士后出了篇综述文章》
GPT-3的大获成功,为NLP圈的研究者们展现了大规模自回归语言模型不需微调即可发挥出的巨大威力。同样立志于通用人工智能的DeepMind怎甘落后,进一步发掘了自回归语言模型在多模态任务上的潜力。Deepmind的研究者们发现,在冻结参数的情况下, 通过与GPT-3类似的Prompt方法,就可以让自回归语言模型处理多模态任务,在多个基准任务上(特别是小样本任务上)取得了相当优秀的效果。
论文题目:
Multimodal Few-Shot Learning with Frozen Language Models
论文链接:
https://arxiv.org/abs/2106.13884
![]() 方法:Frozen
方法:Frozen![]()
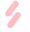 方法:Frozen
方法:Frozen作者们将本文的方法取名为Frozen。Frozen的主要目标是,利用冻结参数的预训练自回归语言模型处理多模态任务。众所周知,自回归语言模型(例如GPT-3)的训练任务是:给定前 -1个词,预测第 个词,可以写成如下的表达形式,其中 表示 个词。
我们考虑多模态任务中经典的图像标题生成任务,图像生成任务的主要目标是给定图像 , 生成描述图像的一段文字 。要想让自回归语言模型处理图像生成任务,一个非常自然的想法是,将图像转换成输入语言模型的“词汇“,这样,我们就可以先将图像对应的”词汇“输入自回归语言模型,让模型为我们输出描述图像的文字。这个想法可以表示成如下的形式. 假设图像 转换为的“词汇”是
接下来的关键是,如何将图像转换成输入语言模型的“词汇”?作者们采用的方法非常直接,使用一个传统的视觉编码器(如ResNet)提取图像的特征,再通过一个线性映射将图像 映射为 的矩阵,其中 就是语言模型“词汇”的表示维度。将图像转换为“词汇” 之后,就可以将图像直接输入语言模型了。整个模型的架构如下图表示。
正如前文所述,自回归语言模型的参数是固定的。作者们在实验中中发现,在小数据集场景下如果同时微调自回归语言模型,反而会损害泛化性能。视觉编码器的参数是通过训练过程中的梯度进行更新的,原因是语言模型和视觉编码器的结构和训练方式完全不同,需要通过训练视觉编码器,将视觉输入转化为语言模型能够“看懂”的输入形式,也就是所谓的Prompt。
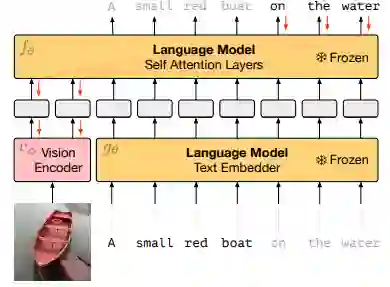
在GPT-3大获成功的三种Prompt方式里,除了上图展示的zero-shot之外,还有one-shot和few-shot两种设置。在这两种设置下,可以为模型提供一个或多个解决该问题的例子,这些例子被拼接在输入数据之前。在本文中,DeepMind的研究员们也在模型推理阶段使用了这两种设置。如下图所示
作者们使用了C4数据集预训练了大小为7B的自回归语言模型。在Conceptural Captions这一图像-标题数据集上固定自回归语言模型参数,训练视觉编码器。随后,作者们在多个多模态任务上开展了实验,让我们一起来看看结果吧~
![]() 实验结果
实验结果![]()
小样本学习术语
在开始实验结果的描述前,我们先简单描述一下小样本学习的一些常用术语,以便大家更好地理解文章。
问题归纳(Task induction) 指用来描述问题的前缀。例如在翻译任务的句子前加上 “ Translate English to Chinese"。
例子数目(n-shots) 指为模型提供例子的数量。在VQA中可以是图片-问题-答案的组合。
标签数目(Number of Ways) 指分类问题中类别的数目。
类内例子数目(Number of Inner-shots) 指分类问题中每个类别对应的例子数目。
重复数目(Number of repeats) 指每个类内例子输入模型的次数。
作者在实验中主要希望探索Frozen在以下三个方面的表现
-
Frozen能否将自回归语言模型快速迁移到多模态任务上?
-
Frozen能否充分利用自回归语言模型中的通用知识?
-
Frozen能否快速地对语言和视觉的概念进行对应?
快速适配
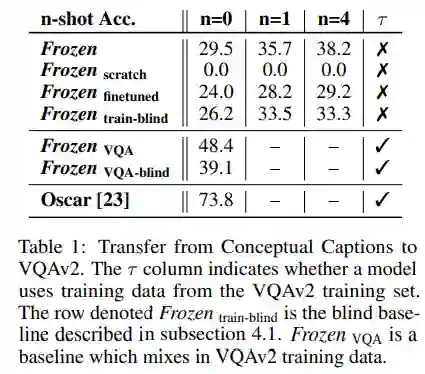
本文的模型是在图像-标题数据集上进行训练的。现实场景中多模态任务种类繁多。作者们希望研究在图像-标题数据集上训练的模型,能否迁移到其他多模态任务(e.g. VQA) 上取得好的表现(这就好比在维基百科上训练掩码语言模型任务的模型,能够迁移到下游的各种分类任务上)。在VQA v2数据集上的结果表明:模型可以迁移到小样本VQA场景下,随着例子数目 (n-shots) 的增多表现随之增长。
通用知识
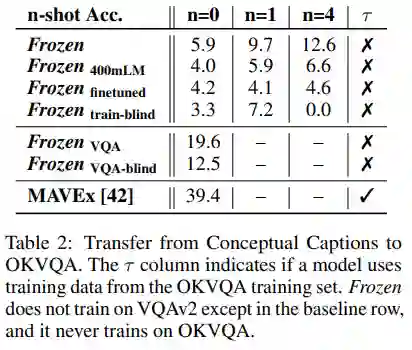
自回归语言模型训练的语料极为丰富,包含了大量的通用知识。作者们希望研究自回归语言模型中的通用知识能否为处理的多模态任务提供帮助。例如,当提供一张飞机的照片并提问“谁发明了图中的东西?“时, 图像-标题数据集可能并不会包含“怀特兄弟发明了飞机”这样的知识,而预训练语言模型的C4数据集中则大概率包含了这样的知识。作者们希望Frozen能够利用这样的知识来回答问题。在OKVQA(一个需要外部知识的VQA数据集)上开展的实验表明,Frozen确实具备应用通用知识的能力。随着自回归语言模型的参数量增长,应用通用知识的能力会提升。


概念对应
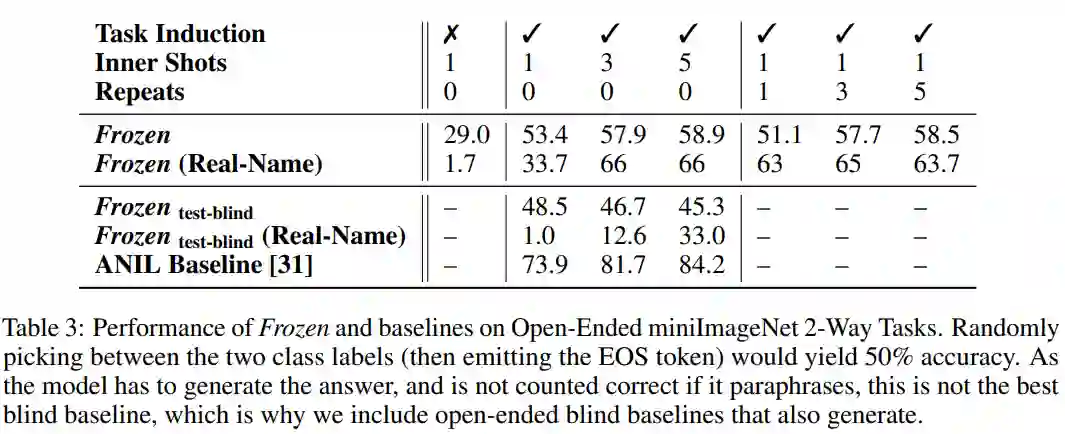
概念对应是人类在认知过程中极为重要的能力。当我们牙牙学语时,爸爸妈妈可能会指着一头狮子告诉我们这个”东西”叫“狮子”。教授几次过后,当我们再次看到狮子时,就能叫出“狮子“。在小样本学习中,概念对应是非常重要的一步。作者们在miniImageNet和FastVQA数据集上开展实验。由于在预训练过程中模型已经见到过大量的文本和图像的对应数据,无法看出模型快速对应新概念的能力。作者们首先将视觉类别对应的文本替换为无意义的词汇,之后提供少量视觉类别的样例和对应的词汇,让模型根据少量样例完成概念的对应,具体示例如下图:

在两个数据集上模型均取得了相当不错的表现。可以发现,加入问题归纳会得到更好的表现,增加类内例子数目会提升模型的性能,而增加重复数目对模型性能影响很小。


![]() 结语
结语![]()
作者们在文中多次表示,与多模态领域使用全部数据微调的SOTA相比,本文的方法还是有着较大的差距。然而,作者们仍然相信,本工作是多模态小样本学习领域Proof of Concept的工作,展现了大规模自回归语言模型的强大潜力。语言作为一种完备且通用的描述世界的方式,也许能为各种模态的任务都提供帮助。
读完本文,笔者第一时间想到的是,DeepMind的研究者们训练了一个7B的语言模型就得到了如此优秀的结果,如果能使用OpenAI的GPT-3(175B)语言模型作为Backbone,是否有机会刷新多模态领域的SOTA呢?
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
[1] Language Models are Few-Shot Learners. https://arxiv.org/abs/2005.14165
[2] Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing. https://arxiv.org/abs/2107.13586
[3] Multimodal Few-Shot Learning with Frozen Language Models. https://arxiv.org/abs/2106.13884
 后台回复关键词【
后台回复关键词【