如何用 100 行 Python 代码实现新闻爬虫?
每天我都要坐地铁上班,而地铁里完全没有手机信号。但我希望在坐地铁的时候读些新闻,于是就写了下面这个新闻爬虫。
我并没有打算做很漂亮的应用,所以只完成了原型,它可以满足我最基本的需求。其思路很简单:
找到新闻源;
用Python抓取新闻;
利用BeautifulSoup分析HTML并提取出内容;
转换成容易阅读的格式并通过邮件发送。
下面详细介绍每个部分的实现。
▌新闻源:Reddit
我们可以通过Reddit提交新闻链接并为之投票,因此Reddit是个很好的新闻来源。但接下来的问题是:怎样才能获取每天最流行的新闻?
在考虑抓取之前,我们应该先考虑目标网站有没有提供API。因为使用API完全合法,更重要的是它能提供机器可读的数据,这样就无需再分析HTML了。
幸运的是Reddit提供了API。我们可以从API列表(https://www.reddit.com/dev/api/)中找到所需的功能:/top。该功能可以返回Reddit或指定subreddit上最流行的新闻。
接下来的问题是:这个API怎么用?
仔细阅读了Reddit的文档(https://github.com/reddit-archive/reddit/wiki/OAuth2)之后,我找到了最有效的用法。
第一步:在Reddit上创建一个应用。登录之后前往“preferences → apps”页面,底部有个名为“create another app...”的按钮。点击后创建一个“script”类型的应用。我们不需要提供“about url”或“redirect url”,因为这个应用不对公众开放,也不会被别人使用。
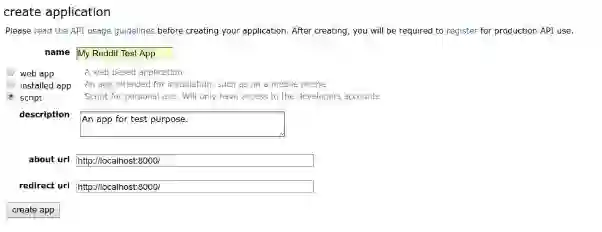
应用创建之后,可以在应用信息里找到App ID和Secret。
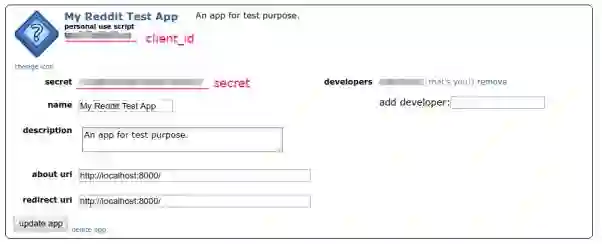
下个问题是如何使用App ID和Secret。由于我们只需获取指定SubReddit上最流行的新闻,而无需访问任何与用户相关的信息,所以理论上来说我们无需提供用户名或密码之类的个人信息。Reddit提供了“Application Only OAuth”(https://github.com/reddit-archive/reddit/wiki/OAuth2#application-only-oauth)的形式,通过这种方式,应用可以匿名访问公开的信息。运行下面这条命令:

该命令会返回access token:

太好了!有了access token之后就可以大展拳脚了。
最后,如果不想自己写API的访问代码的话,可以使用Python客户端:https://github.com/praw-dev/praw
先做一下测试,从/r/Python获取最流行的5条新闻:
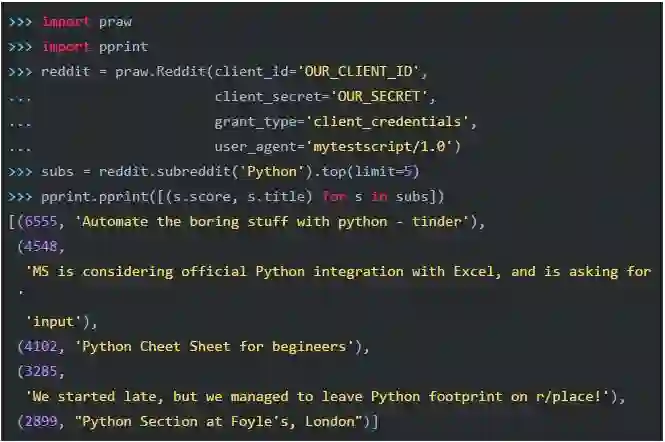
成功了!
▌抓取新闻页面
下一步的任务是抓取新闻页面,这其实很简单。通过上一步我们可以得到Submission对象,其URL属性就是新闻的地址。我们还可以通过domain属性过滤掉那些属于Reddit自己的URL:

我们只需要抓取该URL即可,用Requests很容易就可以做到:
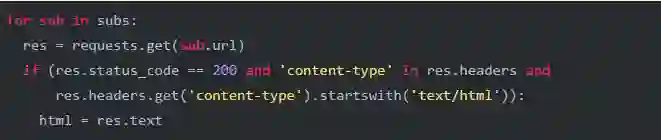
这里我们略过了content type不是text/html的新闻地址,因为Reddit的用户有可能会提交直接指向图片的链接,我们不需要这种。
▌提取新闻内容
下一步是从HTML中提取内容。我们的目标是提取新闻的标题和正文,而且可以忽略其他不需要阅读的内容,如页首、页脚、侧边栏等。
这项工作很难,其实并没有通用的完美解决办法。虽然BeautifulSoup可以帮我们提取文本内容,但它会连页首页脚一起提取出来。
不过幸运的是,我发现目前网站的结构比以前好很多。没有表格布局,也没有<font>和<br>,整个文章页面清晰地用<h1>和<p>标出了标题和每个段落。而且绝大部分网站会把标题和正文放在同一个容器元素中,比如像这样:
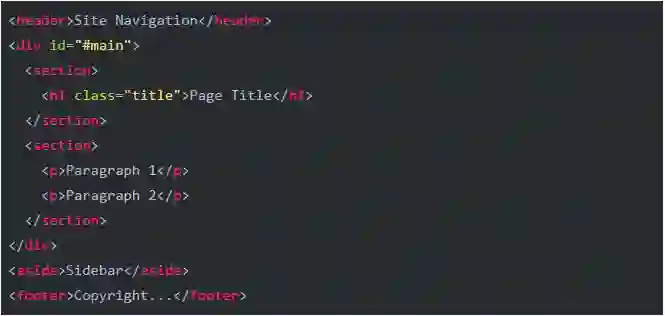
这个例子中顶层的<div id="#main">就是用于标题和正文的容器。所以可以利用如下算法找到正文:
找到<h1>作为标题。出于SEO的目的,通常页面上只会有一个<h1>;
找到<h1>的父元素,检查该父元素是否包含足够多的<p>;
重复第2步,直到找到一个包含足够多<p>的父元素,或到达<body>元素。如果找到了包含足够<p>的父元素,则该父元素就是正文的容器。如果在找到足够的<p>之前遇到了<body>,说明页面不包含任何可供阅读的内容。
这个算法虽然非常简陋,并没有考虑任何语义信息,但完全行得通。毕竟,算法运行失败时只需要忽略掉那篇文章就行了,少读一篇文章没什么大不了的……当然你可以通过解析<header>、<footer>或#main、.sidebar等语义元素来实现更准确的算法。
用这个算法可以很容易地写出解析代码:
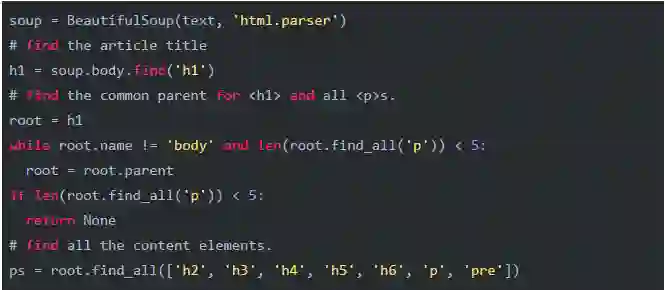
这里我利用len(root.find_all('p')) < 5作为正文过滤的条件,因为真正的新闻不太可能少于5个段落。大家可以根据需要调整这个值。
▌转换成易于阅读的格式
最后一步是将提取出的内容转换为易于阅读的格式。我选择了Markdown,不过你可以写出更好的转换器。
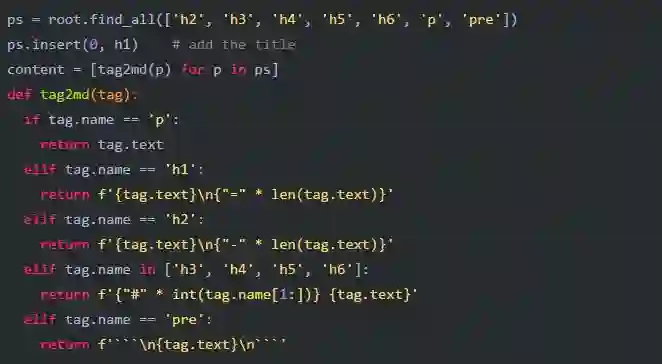
本例中我只提取了<h#>和<p>、<pre>,所以简单的函数就能满足要求:
▌完整的代码
我在Github上分享了完整的代码,链接如下:
https://gist.github.com/charlee/bc865ba8aac295dd997691310514e515
正好100行 ,跑一下试试:
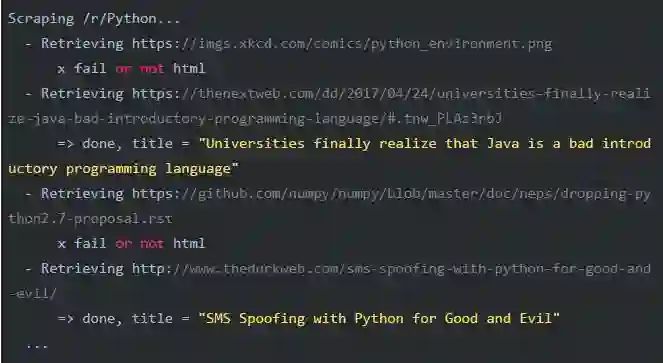
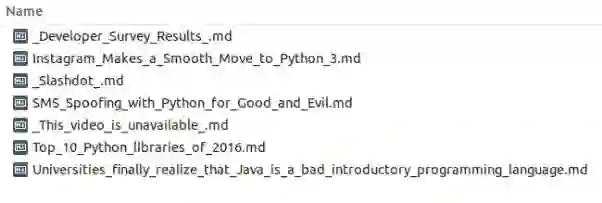
抓取的新闻文件:
最后需要做的是将这个脚本放在服务器上,设置好cronjob每天跑一次,然后将生成的文件发到我的信箱。
我没有花太多时间关注细节,所以其实这个脚本还有很多值得改进的地方。有兴趣的话你可以继续添加更多的功能,如提取图像等。
文章经授权转自:CSDN
参与「程序员专属信用卡」调研
让我们打造最适合程序员的信用卡!
美食、购物、航旅…优惠折扣等着你哦~
扫码参与投票









