开发 | 如何加速神经语言模型训练?东北大学小牛翻译团队有妙招
AI科技评论按:本文为东北大学自然语言处理实验室(小牛翻译团队)成员肖桐、李垠桥为AI科技评论撰写的独家稿件,得到了其指点和审核,AI科技评论在此表示感谢。
团队简介:东北大学自然语言处理实验室(小牛翻译团队)由姚天顺教授于1980年创立,长期从事机器翻译及语言分析方面的研究。小牛翻译团队所研发的NiuTrans系统开源版和小牛翻译企业版已经被来自 60 余个国家的2000多个机构使用,并支持44种语言的翻译。团队在CWMT、NTCIR等评测中取得多项第一、第二的成绩,发表AI、IJCAI、AAAI、ACL等期刊及会议论文40余篇,并于2016年获得中文信息处理领域最高奖钱伟长中文信息科学技术奖(一等奖)。
一、神经语言模型简介
语言作为人类之间进行沟通交流的桥梁,在历史发展的长河中扮演着极其重要的角色。而随着人工智能时代的到来,人们更加希望语言不仅仅能够在人和人之间进行信息的传递,也能让机器“理解”人所说的话。而在这个过程中十分重要的一个环节就是给人所说的语言建立一个科学有效的模型,具体来说就是让机器有能力从众多文字序列中找到合适的字符组合表达语义,与人类进行正常的沟通。
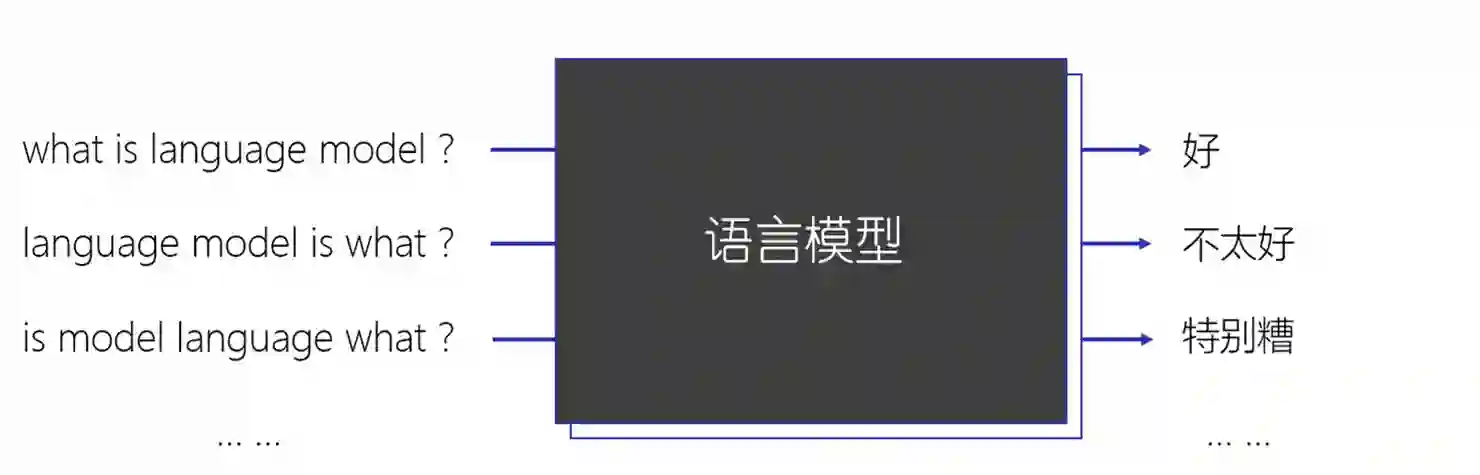
上图的例子中,我们将语言模型作为一个黑盒,它能够对三个输入的“句子”进行一个评判,判断其语言学上的合理性,这便是语言模型要做的工作。具体来说,它通过链式法则对整个文字序列作为句子的可能性进行量化,对每个词语出现在当前位置(指历史单词出现后该词语出现)的概率求乘积得到整句话的概率。
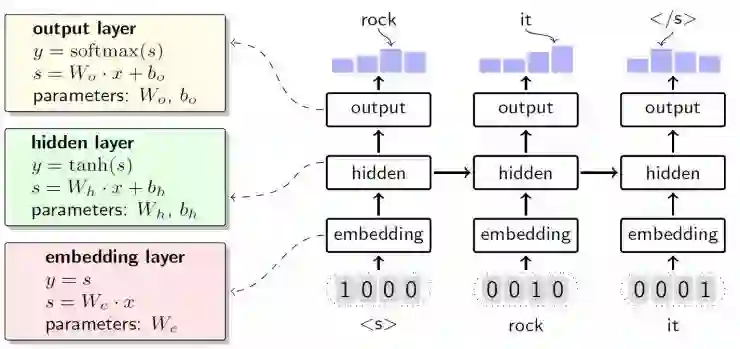
那要如何知道每个词出现时的概率呢?在神经语言模型中,其整体结构如上图所示(图为循环神经语言模型[1]),输入层将离散表示的词汇转化成连续空间上的词向量,不同词汇之间的向量距离能够反映词语之间的相似性。隐藏层将输入层传递来的词向量进行更深层次的表述。输出层结合隐藏层所传递来的信息对可能出现在下一个位置的词进行预测,获得词汇表中每个词的预测概率,有了它我们就能够按照链式法则对句子的概率进行预测了。
二、更快地训练神经语言模型
随着在语音识别、机器翻译等领域对语言模型性能需求的日益增长,我们迫切地希望能够进一步改善神经语言模型的性能。一般来说使用更大量的训练数据来训练更复杂的模型结构将会获得更优的模型性能,但与此同时带来的问题在于其训练所花费的时间消耗也相应地变长了。面对这种情况,如何有效地减少训练神经语言模型占用的时间成为了亟待解决的问题。
那么如何加快神经语言模型的训练呢?在处理器的发展过程中,前期主要通过提升硬件主频来提升设备的运算速度,而后期由于受到物理环境等客观因素的限制,逐渐将方向转到多核并行上来提升计算速度。类似于该过程,在神经网络的训练加速中也主要有两种方法,一种是通过提高硬件的性能来对训练进行加速,另一种是通过增加参与运算的设备数量来达到加速的目的。前者就是对目前来说的一种主流思想,这种方法通过逐渐将神经网络中矩阵运算相关的操作由CPU向GPU迁移,达到加速的目的。后者是我们要研究的重点,希望能在更多的设备上对神经语言模型进行训练。
三、多设备并行的训练方法及优化
面对着更多的训练数据,我们要如何在多台设备上进行网络的训练呢?一种常见的方法就是数据并行[2],该方法由Jeffrey Dean等人提出,其核心思想就是将训练数据分散到多台设备上同时进行训练,并维护同一套网络参数。具体的过程为,在网络中设置一个参数服务器,用来保存全局的网络参数,其余每台设备在计算好自己的权重梯度后将其发送给参数服务器,由参数服务器将梯度更新到全局最新的权重中来,最后将最新的参数返回给设备服务器完成一个minibatch的更新。
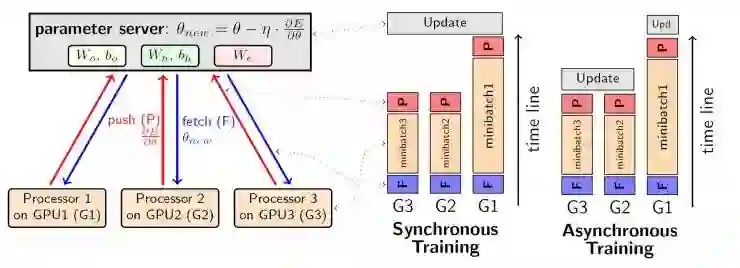
上述方法中存在两种参数同步的策略,一种是同步地进行参数更新,另一种为异步。二者的区别在于参数服务器向每个设备返回更新后的参数的时机不同。前者需要等待收集到全部设备上发送来的梯度后再进行权重的更新,而后者每当参数服务器收到一个梯度后便将其更新到自身权重中,并把当前权重值返回给设备,过程如上图所示。由于异步的方式加速效果有限,同时会对模型收敛产生一定程度的负面影响,因此在实际情况中一般较少使用。
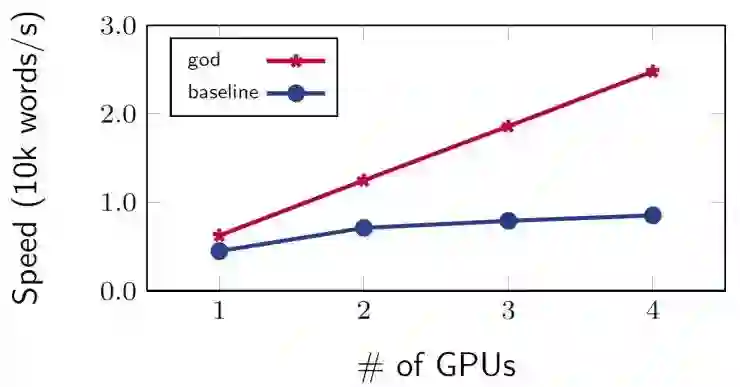
理想情况下,由于数据并行将数据分散到了多台设备上进行训练,因此系统训练速度应该同设备数量的增长而线性增大,但实际结果并不尽如人意。我们在一台机器上使用多台GPU设备对神经语言模型进行训练,速度图像如上图所示,并没有达到所期待的几张卡速度就翻几倍的现象。造成这个问题的原因是什么呢?
我们可以看到,在数据并行的过程中,权重矩阵以及梯度需要在设备之间进行频繁的数据传输,不论是机器内部设备之间的传递还是机器之间的,这部分的传输速度相对设备的计算性能均相去甚远。也就是说,虽然我们使用了多台设备进行协同训练,成功地将运算分散到多台设备上并行执行,但是在这个过程中为了维护同一套网络参数,反而在设备间的数据传输上投入了不小的精力,导致整体的速度提升受到制约。在之前提到的四卡实验中,数据传输所花费的时间就占据了整个训练耗时的50%左右,给系统并行效率造成严重的负面影响。针对上述问题,众多科研人员也纷纷提出各种策略,希望能降低多设备训练中数据传输耗时对并行效果造成的不良影响,这里主要介绍三种常见的优化方法。
第一种加速策略叫做All-Reduce[3],它将原本中央化的传输结构改为环形,取消了参数服务器的设置,让设备和设备之间以一种有向环的结构进行数据的传输,使得系统内带宽的利用率更高,数据传输更加高效。
第二种方式叫做double-buffering,通过双缓冲区协同工作的方法,将神经网络训练过程中梯度计算和数据传递两部分进行时间上的重叠,使得单位时间能够执行更多的minibatch。
此外还有一种更加简单粗暴的方式叫做模型平均[4],该方法在每一轮的训练过程中,不进行设备间的参数同步,只有当每一轮训练结束后才进行参数的平均。这样做有效降低了数据传输的频次从而达到了加速的效果,对于带宽较低的物理环境(如设备处于多台机器上,使用以太网进行连接)常常使用它对系统进行优化。
四、基于采样的方式进行数据传输
面对数据传输在并行中的大量耗时,我们希望能进一步减小这部分所花费的时间。我们知道传输时间等于所要传输的数据量除以系统中的带宽,因此在不对数据并行模式进行修改的前提下,我们只能通过两种手段对其进行加速,分别是提升传输速度以及减小数据传输的数量。All-Reduce的方法就属于第一类,通过数据传输结构的变化提升了传输性能。那么我们换一种思想,能否从第二个角度,也就是减少所要传输的数据量来对数据传输时间进行优化呢?

我们拥有有限的带宽,希望能尽可能快地完成权重梯度的传递,那么一种方式就是对所要传输的梯度矩阵进行采样,使得需要被传输的数据量更少,这样花费在这部分的时间也会相应地降低。定下了整体的优化方向之后,接下来的问题就是我们要按照哪种策略来进行采样呢?
简单一句话,“集中力量办大事”。在向参数服务器发送梯度的时候,从完整的梯度矩阵中抽取出对提高神经语言模型性能更有帮助的部分进行传输,减少传输的数据量,从而达到降低时间消耗的目的,如上图所示。
这种方法针对神经语言模型的不同层提出了不同的采样策略。以输出层为例,权重矩阵为W,其大小为 v*h,v 为词表大小,h为隐藏层节点数目。我们可以看到当网络在前向传播的过程中,权重的每一行都将与隐藏层的输出向量进行点乘,得到词汇表中某一词的预测概率。也就是说,输出层权重的每一行都和词表中对应位次的词相对应,这就是我们要对该层权重进行采样的一大重要依据。为了能让网络更快地收敛,我们让训练集中频繁出现的词所对应的行向量具有更高的概率被抽取出来,传递给参数服务器进行更新。具体的选取策略为:

其中,Vbase为在当前minibatch中出现的词,Vα为从词汇表中选择频繁出现的若干词,Vβ为从词汇表中随机抽取的词以保证系统具有良好的鲁棒性,在测试集上更稳定。同样,在输入层和隐藏层也有各自不同的采样策略。
举个例子,如下图所示在训练阶段,GPU1根据自身权重矩阵计算好它的权重梯度,然后通过采样的方法从中抽取第一行和第三行传递给参数服务器,同理GPU2也执行了类似的操作,抽取第二和第三行进行传输。参数服务器GPU3收到两台设备传递过来的权重梯度后对它们按行进行累加,得到最终的梯度矩阵,将其更新到网络参数中。在这个过程中由于两台设备均未采样到第四行的梯度向量,因此在更新的时候并未对其进行更新。

前述方法中我们使用采样的方式对需要传输的梯度进行抽取,尽可能频繁地去更新那些对网络性能帮助较大的部分。但其实既然我们已经决定舍弃掉了这部分梯度,为了进一步获得速度上的提升,完完全全可以不去计算它们。我们都知道神经网络的训练需要经过前向传播和反向传播两个步骤以获得权重的梯度,这里我们为它们建立两套不同的采样方式。
还是以输出层为例,在前向传播的过程中,我们依据采样方式A舍弃掉一部分进行计算,接下来在梯度的反向传输过程中按照采样方式B再次舍弃掉部分梯度的传递。方式B采样的方式同数据传输中的采样策略相同,使用Vall对行向量进行筛选,而方式A中我们从词汇表中又随机抽取出若干单词加入到Vall中,这种方式在反向传播过程中引入了一些噪声词汇,能够有效提升模型的鲁棒性。
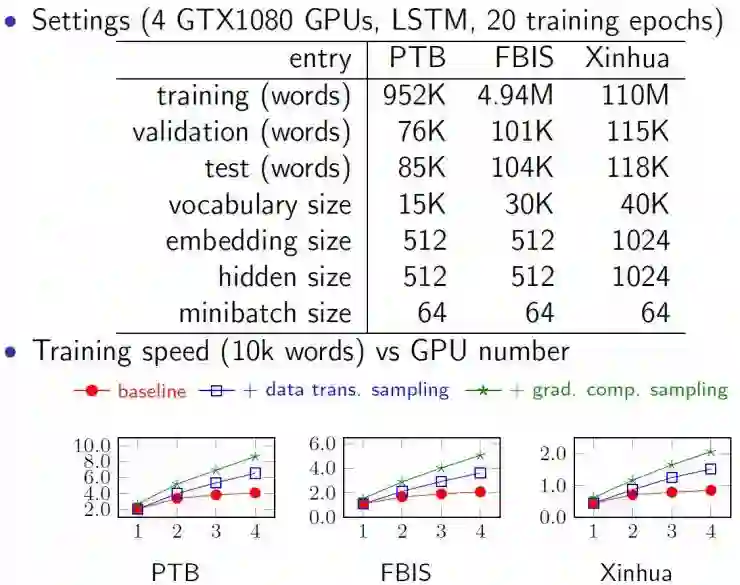
针对上述两种方法我们在PTB、FBIS以及Xinhua的数据集上进行测试,结果如上图所示,其中baseline为异步训练的结果,可以看出加速效果有限。在三个任务集上对网络进行分布式训练,我们可以看到将采样的方法应用到梯度计算中的加速效果最佳,在使用4张卡的情况下,相对异步的方法可提速2.1倍左右,相对单卡可提升4.2倍左右。
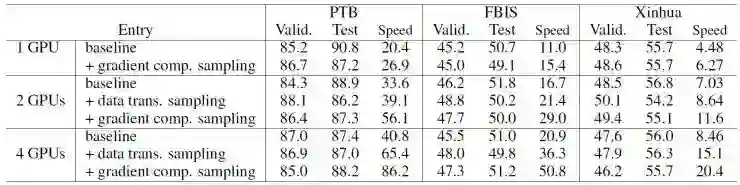
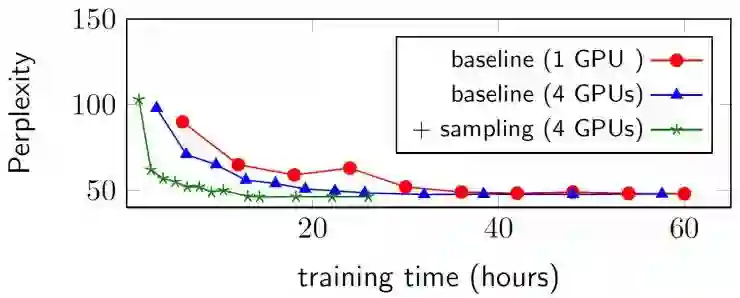
在三个数据集上训练LSTM语言模型[5]得到的性能如上图所示(指标为困惑度),我们可以看到在使用了采样的方式后模型性能与基线相差不大。下图给出了在Xinhua的数据集上,校验集困惑度随训练时间变化的曲线图,其中在4张卡的环境下使用了采样的方式后,可以看到其收敛性明显优于基线,在第五轮训练中困惑度得到明显下降,同时在8-10轮左右的时候收敛。
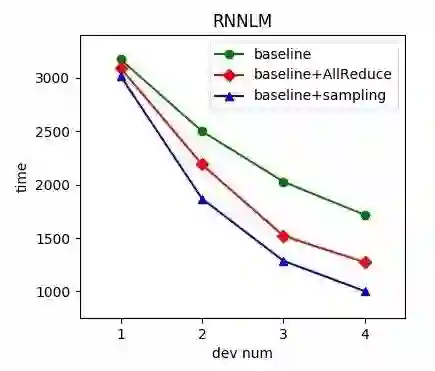
在本章的开始处我们提到,在不对数据并行模式进行修改的前提下数据传输的加速方式主要有两种,提升传输效率以及减少传输数量,二者分别对应我们提到的All-Reduce和采样的两种方法。我们在实验中对比了两种方式的加速效果,如下图所示,All-Reduce的方式相对基线在四张卡上可提速约25%,在基于采样的方式下提速比为41%左右。由于二者对于加速策略的出发点不同,因此理论上可以同时使用两种方式对系统进行加速。
通过以上几个实验我们可以看到,基于采样的方法在多设备上训练神经语言模型可以有效减少在数据传输中的时间消耗,为在更多设备上训练提供了可能。该方法主要包括数据传输中的采样以及梯度计算中采样,在4张GPU设备上训练,相对异步的方式可提速约2.1倍,相对单卡训练可提速4.2倍左右。该方法已被成功应用到小牛翻译核心引擎中,对于其所支持的包括汉、英、日、韩等44种语言在内的翻译系统,多设备系统的并行训练性能提升明显。
注:本文主要内容参考IJCAI 2017论文Fast Parallel Training of Neural Language Models,部分实验来自CWMT 2017论文基于数据并行的神经语言模型多卡训练分析。
参考文献
[1]Mikolov T, Karafiát M, Burget L, et al. Recurrent neural network based language model[C]// INTERSPEECH 2010, Conference of the International Speech Communication Association, Makuhari, Chiba, Japan, September. DBLP, 2010:1045-1048.
[2] Dean J, Corrado G S, Monga R, et al. Large scale distributed deep networks[C]. International Conference on Neural Information Processing Systems. Curran Associates Inc. 2012:1223-1231.
[3] Wang L, Wu W, Bosilca G, et al. Efficient Communications in Training Large Scale Neural Networks[J]. 2017.
[4] Hansen L K, Salamon P. Neural Network Ensembles[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 1990, 12(10):993-1001.
[5] Surhone L M, Tennoe M T, Henssonow S F. Long Short Term Memory[J]. Betascript Publishing, 2010.
————— 给爱学习的你的福利 —————
3个月,从无人问津到年薪30万的秘密究竟是什么?答案在这里——崔立明授课【推荐系统算法工程师-从入门到就业】3个月算法水平得到快速提升,让你的职业生涯更有竞争力!长按识别下方二维码(或阅读原文戳开链接)抵达课程详细介绍~

————————————————————




