教程:使用iPhone相机和openCV来完成3D重建(第三部分)

本文为 AI 研习社编译的技术博客,原标题 :
Tutorial: Stereo 3D reconstruction with OpenCV using an iPhone camera. Part III.
作者 | Omar Padierna
翻译 | Succi、alexchung
校对 | Pita 审核 | Lam-w 整理 | 立鱼王
原文链接:
https://medium.com/@omar.ps16/stereo-3d-reconstruction-with-opencv-using-an-iphone-camera-part-iii-95460d3eddf0
注:本文的相关链接请访问文末【阅读原文】
欢迎阅读关于立体重建三部分教程的第三部分,也是最后一部分。
快速回顾一下:
在第一部分,我们简要介绍了立体三维重建所需的步骤以及工作原理。
在第二部分,我们分析了一个计算相机矩阵和失真系数的脚本。这些是三维重建过程中所必需的相机固有参数。
一旦相机被校准,我们就可以利用来自同一物体的一对图片完成重建。在大多数立体重建的应用程序中,每张照片来自两个独立的相机,如下图所示

由Daniel Lee所提供的用于3D重建的典型双摄像头系统
人们这样做的原因是因为将两个相机放在同一高度(如我们的眼睛)是很重要的。在本教程中,我们只是使用手机摄像头,因此我们不需要进行类似的设置。如果你想制作自己的双摄像头系统以获得更好的效果,你可以阅读Daniel Lee的博客。
我们仍然需要一对图片来生成视差图。在这种情况下,需要有人拍摄我的两张照片,同时小心地水平移动相机,确保没有垂直移动(这说起来容易做起来难)。如果通过手动或者你自己操作太困难,你可以使用三脚架。

我胖我傲娇
一旦我们拍完照片,就可以开始敲代码了。我们将从加载相机矩阵和显示上面得到的图片开始。友情提示,请记住可以在原文找到完整的脚本。
#=========================================================# Stereo 3D reconstruction#=========================================================#Load camera parametersret = np.load('./camera_params/ret.npy')K = np.load('./camera_params/K.npy')dist = np.load('./camera_params/dist.npy')#Specify image pathsimg_path1 = './reconstruct_this/left2.jpg'img_path2 = './reconstruct_this/right2.jpg'#Load picturesimg_1 = cv2.imread(img_path1)img_2 = cv2.imread(img_path2)#Get height and width. Note: It assumes that both pictures are the same size. They HAVE to be same sizeh,w = img_2.shape[:2]
然后我们基于自由缩放参数,去计算最优相机矩阵。实际上,如果我们改变图像大小,该算法需要重新计算相机矩阵。虽然我们实际上没有改变它,但我注意到通过这种算法获得的相机矩阵,在摆脱失真时会得到更好的结果。
#Get optimal camera matrix for better undistortionnew_camera_matrix, roi = cv2.getOptimalNewCameraMatrix(K,dist,(w,h),1,(w,h))#Undistort imagesimg_1_undistorted = cv2.undistort(img_1, K, dist, None, new_camera_matrix)img_2_undistorted = cv2.undistort(img_2, K, dist, None, new_camera_matrix)#Downsample each image 3 times (because they're too big)img_1_downsampled = downsample_image(img_1_undistorted,3)img_2_downsampled = downsample_image(img_2_undistorted,3)
最后,一旦图像没有失真,我们就对它们进行降采样。降采样有两个功能:
1)提高图像处理速度2)在计算视差图时,帮助进行参数调整。
了解特征匹配算法中使用的图像大小是非常重要的。这是因为对于我们正在使用的算法,我们需要指定窗口大小。窗口大小越大,对应计算所需的时间就越长。
如果窗口大小不够大,视差就无法正确计算,并且会的到一个包含各种噪声的深度图(或不完整的深度图)。这对我们的目标是不利的,因此最好对图像进行降采样。本教程不讨论用于对图像进行降采样的函数,但它会在完整脚本的顶部进行声明。
需要重点指出的是,通过对图像进行降采样,不可避免地会丢失信息,以至于深度精度也会受到影响。在我看来,如果深度精度对您很重要,那么最好使用基于激光或红外的传感器来制作深度图。立体深度图一般认为,并不是非常准确。
一旦图像准备好进行处理,我们就可以特征匹配算法。根据“Learning OpenCV 3”一书,立体匹配的典型技术是块匹配。Open CV提供两种块匹配的实现:立体块匹配和半全局块匹配(SGBM)。两种算法相似,但有差异。
块匹配的要点是在具有重叠可视区域的两个图像之间寻找强匹配点。通俗的讲,这意味着算法将在对于同一物体的两个图片中,寻找相同的像素(即相同的事物)。
块匹配侧重于高纹理图像(想象树的图片),半全局块匹配更关注于子像素级别匹配和具有更光滑纹理的图片(想象走廊的图片)。
在本教程中,我们使用SGBM,因为图片是在室内拍摄的,其中有很多光滑的纹理。该算法包括3个步骤,这于理解很重要。
如果不能对这些步骤有直观的理解,使用SGBM算法将非常困难,因为它接收的参数取决于理解(即使是肤浅的)它正在做什么。
算法实际上包含三个步骤:
预过滤图像,用于归一化亮度和增强纹理
使用SAD窗口沿水平极线执行相应的搜索
后过滤图像,以消除不良的相关匹配
为了完成归一化亮度和增强纹理操作,我们运行一个窗口(窗口大小至少5x5,最大21x21)在图像上。修改这个窗口大小的参数在代码中称为win_size。
然后我们通过滑动SAD窗口来计算相关性。在继续执行之前,从概念上理解什么是极线是很重要的。在 OpenCV中有一个很好的教程,介绍如何编写代码来可视化它们。
为了更好地了解极线,我们可以做以下练习。将手放在脸部中间并闭上左眼。然后做对位操作(即闭上你的右眼,打开你的左眼)。您会注意到手的位置略有变化。
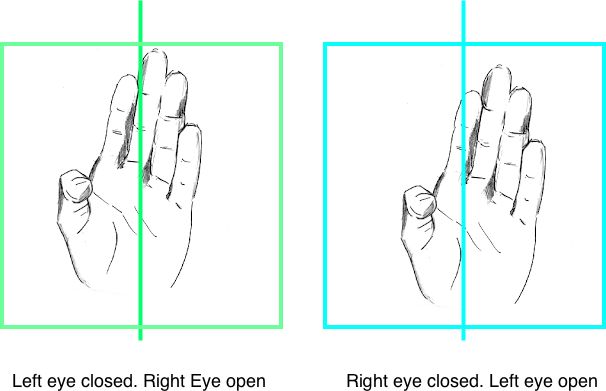
一个就我理解的直观解释,可能并不是很好
因为你的眼睛处于不同的位置,一只眼睛可以看到另一只眼睛无法看到的东西。如果只有一只眼睛打开,就无法看到你手上的3D点,因为所有点都投射到与你的脸相同的图像平面上(即你看不到背后的东西)。
然而,另一只眼睛可以同时看到它的相对部分正在看什么以及由于它们之间的分离出现的背后的一些东西。再试一次,看看你自己,你会注意到,只要一只眼睛,你会看到某些东西(特别是在背景中),而你不能用另外一只眼睛看到。
好的,那又怎样呢?好吧,当你改变哪只眼睛是打开,哪只眼睛闭合时,你会无意识地将焦点移向你感兴趣的东西(在这种情况下是你的手),你可以通过跟随一条线来实现。这条线被称为“极线”。
通过将双眼得到的信息结合起来,你就可以对你所看到的东西的三维坐标进行三角测量,这就是你理解深度的方法。
相机是相同的原理,当您使用两个平行相机拍摄一张照片(或者在一种情况下,使用同一个相机但通过移动得到的两张照片)时,你知道一张照片将包含沿极线的另一张照片的点。
OpenCV对极线几何有更正式(更好)的解释和图片寿命。去查看它是一个不错的想法。
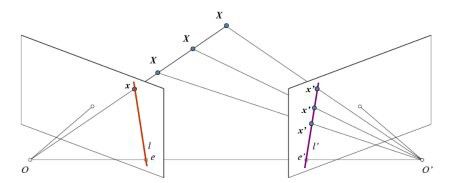
对极几何的解释, 紫色线是兴趣点x所在的极线。
为什么极线相关?因为对于不失真图像,外极线将是水平的,我们确定兴趣点能够沿着外极线找到。这样,通过SGBM算法遍历它们,就能可以找到匹配项。
这就是第二步的全部内容。然而,我们需要告诉它在多大程度上视差(即偏移量)是可以接受的。为此,我们必须指定最小和最大差异。这里的目标是通过减去它们来计算差异的数量,这是一种指定图像中像素可以移动的可接受范围的方法。
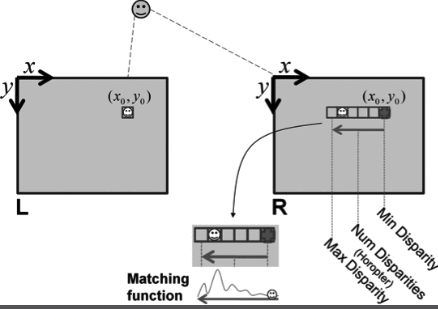
最小和最大差异的解释。感谢Bradski和Kaehler的“学习OpenCV”
最后一步是进行一些后处理。在进行特征匹配之后可能存在假证样本(即错误匹配),为了纠正这些错误,OpenCV有一个唯一性比率,它是匹配值的阈值。
最后,基于块的匹配可能在目标边界附近存在问题(因为一张图片可以看到“后面”,而另一张则看不到,还记得吗?)这就形成了一个由许多微小差异组成的区域,称为“斑点”。为了保护它们,我们必须设置一个斑点窗口,接受这些“斑点”的区域。
在SGBM算法的特定情况下,有一个名为dis12maxdiff的参数,它指定从左到右计算的视差与从右到左计算的视差之间允许的最大差异。
如果视差之间的差异超过阈值,该像素将被宣布为未知。
如果想对这些算法有更多(更好)的了解,建议阅读Gari Bradski和Adrian Kaehler合著的《Learning Open CV 3》一书。它还有c++版本的3D重建。
在代码中,这意味着我们必须定义SGBM对象并设置参数,然后计算视差,就像这样:
#Set disparity parameters#Note: disparity range is tuned according to specific parameters obtained through trial and error.win_size = 5min_disp = -1max_disp = 63 #min_disp * 9num_disp = max_disp - min_disp # Needs to be divisible by 16#Create Block matching object.stereo = cv2.StereoSGBM_create(minDisparity= min_disp,numDisparities = num_disp,blockSize = 5,uniquenessRatio = 5,speckleWindowSize = 5,speckleRange = 5,disp12MaxDiff = 1,P1 = 8*3*win_size**2,#8*3*win_size**2,P2 =32*3*win_size**2)#32*3*win_size**2)#Compute disparity mapprint ("\nComputing the disparity map...")disparity_map = stereo.compute(img_1_downsampled, img_2_downsampled)#Show disparity map before generating 3D cloud to verify that point cloud will be usable.plt.imshow(disparity_map,'gray')plt.show()
请注意,这些参数与我所拍摄的照片非常匹配。在实践中,这将需要手工进行微调,并进行大量的尝试和错误。这就是为什么在将视差图转换为点云之前将其可视化非常方便的原因。
经过反复的尝试,视差图变成了这样。

我自己的视差图
如你所见,这个视差图在我的衬衫区域有很多死点和斑点。此外,我的嘴不见了,似乎噪声很多。这是因为我没有很好地调整SBGM参数。
当图片被适当地扭曲和SGBM算法很好地调整后,会得到平滑的视差图,如下图所示。这个视差图来自 cones dataset。
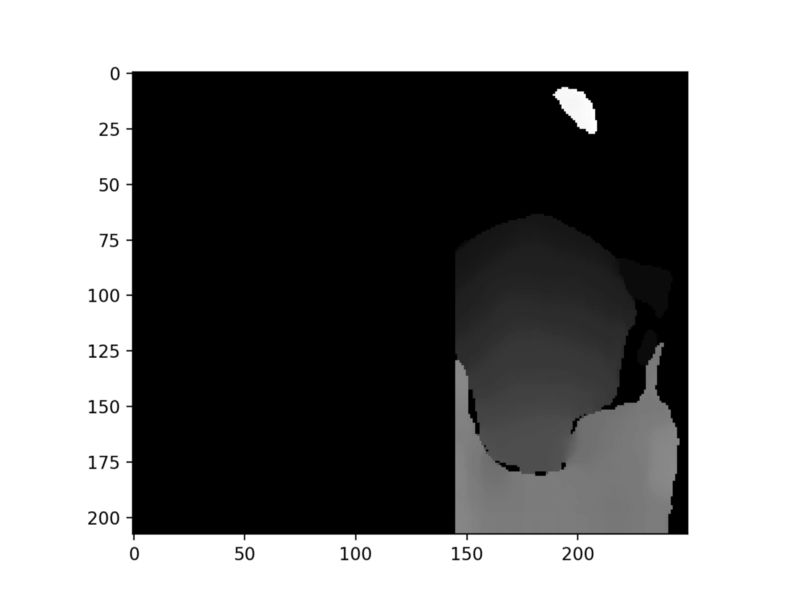
平滑的视差图.
优化视差图的最佳方法是在算法上构建GUI并实时优化视差图,以获得更平滑的图像。在未来,我将上传一个GUI进行实时微调,同时我们将使用这个视差图。
一旦我们计算了视差图,我们就必须得到图像中使用的颜色的数组。由于我们对图像进行了下采样,需要得到图像的高度和宽度。
更重要的是我们需要得到变换矩阵。这个矩阵负责将深度和颜色重新投射到三维空间中。OpenCV的文档有一个转换矩阵的例子。
大多数例子将使用OpenCV文档中的转换矩阵。就我而言,事情没有那么顺利。我发现了一个更通用的矩阵,我的矩阵就是以此为基础的。

Didier Stricker教授幻灯片中的转换矩阵。
#Generate point cloud.print ("\nGenerating the 3D map...")#Get new downsampled width and heighth,w = img_2_downsampled.shape[:2]#Load focal length.focal_length = np.load('./camera_params/FocalLength.npy')#Perspective transformation matrix#This transformation matrix is from the openCV documentation, didn't seem to work for me.Q = np.float32([[1,0,0,-w/2.0],[0,-1,0,h/2.0],[0,0,0,-focal_length],[0,0,1,0]])#This transformation matrix is derived from Prof. Didier Stricker's power point presentation on computer vision.#Link : https://ags.cs.uni-kl.de/fileadmin/inf_ags/3dcv-ws14-15/3DCV_lec01_camera.pdfQ2 = np.float32([[1,0,0,0],[0,-1,0,0],[0,0,focal_length*0.05,0], #Focal length multiplication obtained experimentally.[0,0,0,1]])#Reproject points into 3Dpoints_3D = cv2.reprojectImageTo3D(disparity_map, Q2)#Get color pointscolors = cv2.cvtColor(img_1_downsampled, cv2.COLOR_BGR2RGB)#Get rid of points with value 0 (i.e no depth)mask_map = disparity_map > disparity_map.min()#Mask colors and points.output_points = points_3D[mask_map]output_colors = colors[mask_map]#Define name for output fileoutput_file = 'reconstructed.ply'#Generate point cloudprint ("\n Creating the output file... \n")create_output(output_points, output_colors, output_file)
实际生成点云的算法与我在OpenCV示例中找到的算法完全相同。它是在实际脚本中声明的,超出了本教程的范围。本质上,它重新塑造了颜色和顶点的形状,然后把它们一个叠到另一个上面。
生成的数组被写入带有特定头文件的文本文件中,该头文件保存为.ply文件。这个文件可以使用meshlab可视化。就我而言,这就是我的结果。

我自己的点云。
正如你所看到的,图像看起来有噪声、畸变,非常类似视差图的样子。根据经验,如果视差图看起来含有噪声,那么点云就会有点失真。
一个漂亮的视差图会产生这样的结果:

上面给出的平滑视差图的点云。
差不多就是这样。你可以通过改进你拍照的方式、校准的方式以及在SGBM算法中微调参数来改善结果。
如果您想要更完整的点云,那么您应该在感兴趣的对象周围拍摄几对图像,并连接所有的3D点,以获得更密集的点云。
我希望这对你们的计算机视觉实验有所帮助。下次见.
相关文章:
教程:使用iPhone相机和openCV来完成3D重建(第一部分)
教程:使用iPhone相机和openCV来完成3D重建(第二部分)
想要继续查看该篇文章相关链接和参考文献?
点击底部【阅读原文】即可访问:
https://ai.yanxishe.com/page/TextTranslation/1414

点击阅读原文,查看更多内容



