RabbitMQ 负载均衡 ( 2 ) :HAProxy
(点击上方公众号,可快速关注)
来源:朱小厮,
blog.csdn.net/u013256816/article/details/77150922
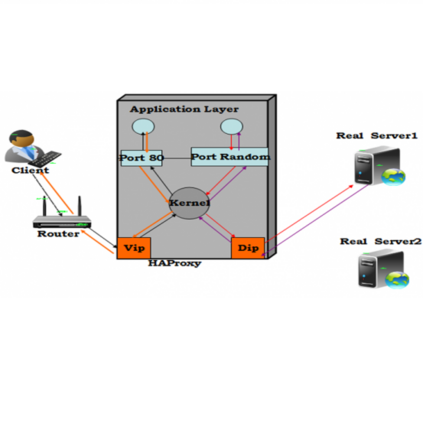
HAProxy提供高可用性、负载均衡以及基于TCP和HTTP应用的代理,支持虚拟主机,它是免费、快速并且可靠的一种解决方案,包括Twitter,Reddit,StackOverflow,GitHub在内的多家知名互联网公司在使用。HAProxy实现了一种事件驱动、单一进程模型,此模型支持非常大的并发连接数。
安装HAProxy
首先需要去HAProxy的官网下载HAProxy的安装文件,目前最新的版本为:haproxy-1.7.8.tar.gz。下载地址为http://www.haproxy.org/#down,相关文档地址为http://www.haproxy.org/#doc1.7。
将haproxy-1.7.8.tar.gz拷贝至/opt目录下,与RabbitMQ存放在同一个目录中。之后解压缩:
[root@node1 opt]# tar zxvf haproxy-1.7.8.tar.gz
将源码解压之后,需要运行make来将HAProxy编译为可执行程序。在执行make之前需要先选择目标平台,通常对于UNIX系的操作系统可以选择TARGET=generic。下面是详细操作:
[root@node1 opt]# cd haproxy-1.7.8
[root@node1 haproxy-1.7.8]# make TARGET=generic
gcc -Iinclude -Iebtree -Wall -O2 -g -fno-strict-aliasing -Wdeclaration-after-statement -fwrapv
-DTPROXY -DENABLE_POLL
-DCONFIG_HAPROXY_VERSION=\"1.7.8\"
-DCONFIG_HAPROXY_DATE=\"2017/07/07\" \
-DBUILD_TARGET='"generic"' \
-DBUILD_ARCH='""' \
-DBUILD_CPU='"generic"' \
-DBUILD_CC='"gcc"' \
-DBUILD_CFLAGS='"-O2 -g -fno-strict-aliasing -Wdeclaration-after-statement -fwrapv"' \
-DBUILD_OPTIONS='""' \
-c -o src/haproxy.o src/haproxy.c
gcc -Iinclude -Iebtree -Wall -O2 -g -fno-strict-aliasing -Wdeclaration-after-statement -fwrapv...
...
gcc -g -o haproxy src/haproxy.o src/base64.o src/protocol.o src/uri_auth.o ...
编译完目录下有名为“haproxy”的可执行文件。之后再/etc/profile中加入haproxy的路径,内容如下:
export PATH=$PATH:/opt/haproxy-1.7.8/haproxy
最后执行source /etc/profile让此环境变量生效。
配置HAProxy
HAProxy使用单一配置文件来定义所有属性,包括从前端IP到后端服务器。下面展示了用于3个RabbitMQ节点组成集群的负载均衡配置。这3个节点的IP地址分别为192.168.02、192.168.0.3、192.168.0.4,HAProxy运行在192.168.0.9这台机器上。
#全局配置
global
#日志输出配置,所有日志都记录在本机,通过local0输出
log 127.0.0.1 local0 info
#最大连接数
maxconn 4096
#改变当前的工作目录
chroot /opt/haproxy-1.7.8
#以指定的UID运行haproxy进程
uid 99
#以指定的GID运行haproxy进程
gid 99
#以守护进程方式运行haproxy #debug #quiet
daemon
#debug
#当前进程pid文件
pidfile /opt/haproxy-1.7.8/haproxy.pid
#默认配置
defaults
#应用全局的日志配置
log global
#默认的模式mode{tcp|http|health}
#tcp是4层,http是7层,health只返回OK
mode tcp
#日志类别tcplog
option tcplog
#不记录健康检查日志信息
option dontlognull
#3次失败则认为服务不可用
retries 3
#每个进程可用的最大连接数
maxconn 2000
#连接超时
timeout connect 5s
#客户端超时
timeout client 120s
#服务端超时
timeout server 120s
#绑定配置
listen rabbitmq_cluster 5671
#配置TCP模式
mode tcp
#简单的轮询
balance roundrobin
#RabbitMQ集群节点配置
server rmq_node1 192.168.0.2:5672 check inter 5000 rise 2 fall 3 weight 1
server rmq_node2 192.168.0.3:5672 check inter 5000 rise 2 fall 3 weight 1
server rmq_node3 192.168.0.4:5672 check inter 5000 rise 2 fall 3 weight 1
#haproxy监控页面地址
listen monitor :8100
mode http
option httplog
stats enable
stats uri /stats
stats refresh 5s
在上面的配置中“listen rabbitmq_cluster bind 192.168.0.9.5671”这里定义了客户端连接IP地址和端口号。这里配置的负载均衡算法是roundrobin,注意这里的roundrobin是加权轮询。和RabbitMQ最相关的是“ server rmq_node1 192.168.0.2:5672 check inter 5000 rise 2 fall 3 weight 1”这种,它定义了RabbitMQ服务,每个RabbitMQ服务定义指令包含6个部分:
server <name>:定义RabbitMQ服务的内部标示,注意这里的“rmq_node”是指包含有含义的字符串名称,不是指RabbitMQ的节点名称。
<ip>:<port>:定义RabbitMQ服务的连接的IP地址和端口号。
check inter <value>:定义了每隔多少毫秒检查RabbitMQ服务是否可用。
rise <value>:定义了RabbitMQ服务在发生故障之后,需要多少次健康检查才能被再次确认可用。
fall <value>:定义需要经历多少次失败的健康检查之后,HAProxy才会停止使用此RabbitMQ服务。
weight <value>:定义了当前RabbitMQ服务的权重。
最后一段配置定义的是HAProxy的数据统计页面。数据统计页面包含各个服务节点的状态、连接、负载等信息。在调用:
[root@node1 haproxy-1.7.8]# haproxy -f haproxy.cfg
运行HAProxy之后可以在浏览器上输入http://192.168.0.9:8100/stats来加载相关的页面,如下图所示:

系列
看完本文有收获?请转发分享给更多人
关注「ImportNew」,看技术干货