独家下载!阿里如何用 AI 写代码?

背景分析

那就不得不提一个我们再熟悉不过的场景了,它就是设计稿自动生成代码(Design2Code,以下简称 D2C),阿里经济体前端委员会-前端智能化方向当前阶段就是聚焦在如何让 AI 助力前端这个职能角色提效升级,杜绝简单重复性工作,让前端工程师专注更有挑战性的工作内容!
相关产品分析
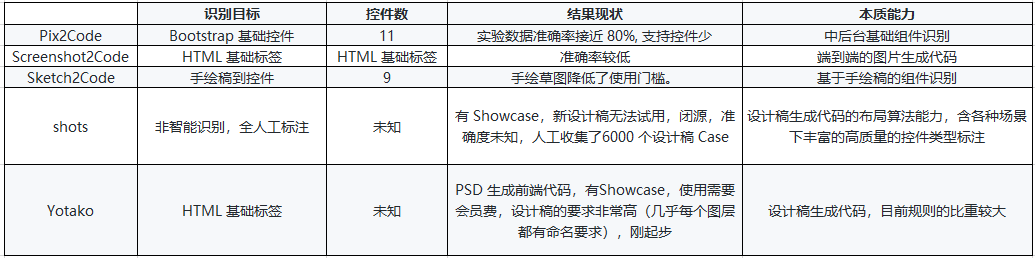
-
深度学习目前在图片方面的目标检测能力适合较大颗粒度的可复用的物料识别(模块识别、基础组件识别、业务组件识别)。 -
完整的直接由图片生成代码的端到端模型复杂度高,生成的代码可用度不高,要达到所生成代码工业级可用,需要更细的分层拆解和多级子网络模型协同,短期可通过设计稿生成代码来做 D2C 体系建设。 -
当模型的识别能力无法达到预期准确度时,可以借助设计稿人工的打底规则协议; 一方面人工规则协议可以帮助用户强干预得到想要的结果,另一方面这些人工规则协议其实也是高质量的样本标注,可以当成训练样本优化模型识别准确度。
问题分解

视图代码

★ 设计稿要求高问题
★ 可维护性问题
-
合理布局嵌套: 包括绝对定位转相对定位、冗余节点删除、合理分组、循环判断等方面; -
元素自适应: 元素本身扩展性、元素间对齐关系、元素最大宽高容错性; -
语义化: Classname 的多级语义化; -
样式 CSS 表达: 背景色、圆角、线条等能用 CV 等方式分析提取样式,尽可能用 CSS 表达样式代替使用图片; -
……

合理分组示意
逻辑代码
-
接口字段绑定: 从可行性上分析还是高的,根据视觉稿的文本或图片判断所属哪个候选字段,可以做,但性价比不高,因为接口数据字段绑定太业务,通用性不强。 -
动效: 这部分的开发输入是交互稿,而且一般动效的交付形式各种各样参差不齐,有的是动画 gif 演示,有的是文字描述,有的是口述; 动效代码的生成更适合用可视化的形式生成,直接智能生成没有参考依据,考虑投入产出比不在短期范围内。 -
业务逻辑: 这部分开发的依据来源主要是 PRD,甚至是 PD 口述的逻辑; 想要智能生成这部分逻辑代码,欠缺的输入太多,具体得看看智能化在这个子领域能解决什么问题。
★ 逻辑代码生成思考


-
由历史源代码分析猜测高频出现的函数块(逻辑块)的语义,实际得到的就是组件库或者基础函数块的语义,可在代码编辑时做代码块推荐等能力。 -
由视觉稿猜测部分可复用的逻辑点,如这里的字段绑定逻辑,可根据这里文本语义 NLP 猜测所属字段,部分图片元素根据有限范围内的图片分类,猜测所属对应的图片字段(如下图示例中的,氛围修饰图片还是 Logo 图片); 同时还可以识别可复用的业务逻辑组件,比如这里的领取优惠券逻辑。
-
字段绑定: 智能识别设计稿中的文本和图片语义分类,特别是文字部分。 -
可复用的业务逻辑点: 根据视图智能识别,并由视图驱动自由组装,含小而美的逻辑点(一行表达式、或一般不足以封装成组件的数行代码)、基础组件、业务组件。 -
无法复用的新业务逻辑: PRD 需求结构化(可视化)收集,这是一个高难度任务,还在尝试中。
小结

目标检测 2014-2019 年 paper
技术方案
-
识别能力: 即对设计稿的识别能力。 智能从设计稿分析出包含的图层、基础组件、业务组件、布局、语义化、数据字段、业务逻辑等多维度的信息。 如果智能识别不准,就可视化人工干预补充纠正,一方面是为了可视化低成本干预生成高可用代码,另一方面这些干预后的数据就是标注样本,反哺提升智能识别的准确率。 -
表达能力: 主要做数据输出以及对工程部分接入 -
通过 DSL 适配将标准的结构化描述做 Schema2Code -
通过 IDE 插件能力做工程接入 -
算法工程: 为了更好的支撑 D2C 需要的智能化能力,将高频能力服务化,主要包含数据生成处理、模型服务部分 -
样本生成: 主要处理各渠道来源样本数据并生成样本 -
模型服务: 主要提供模型 API 封装服务以及数据回流

前端智能化 D2C 能力概要分层
智能识别技术分层
-
物料识别层: 主要通过图像识别能力识别图像中的物料(模块识别、原子模块识别、基础组件识别、业务组件识别)。 -
图层处理层: 主要将设计稿或者图像中图层进行分离处理,并结合上一层的识别结果,整理好图层元信息。 -
图层再加工层: 对图层处理层的图层数据做进一步的规范化处理。 -
布局算法层: 转换二维中的绝对定位图层布局为相对定位和 Flex 布局。 -
语义化层: 通过图层的多维特征对图层在生成代码端做语义化表达。 -
字段绑定层: 对图层里的静态数据结合数据接口做接口动态数据字段绑定映射。 -
业务逻辑层: 对已配置的业务逻辑通过业务逻辑识别和表达器来生成业务逻辑代码协议。 -
出码引擎层: 最后输出经过各层智能化处理好的代码协议,经过表达能力(协议转代码的引擎)输出各种 DSL 代码。

D2C 识别能力技术分层
技术痛点
-
识别问题定义不准确: 问题定义不准确是影响模型识别不准的首要因素,很多人认为样本和模型是主要因素,但在这之前,可能一开始的对问题的定义就出现了问题,我们需要判断我们的识别诉求模型是否合适做,如果合适那该怎么定义清楚这里面的规则等。 -
高质量的数据集样本缺乏: 我们在识别层的各个机器智能识别能力需要依赖不同的样本,那我们的样本能覆盖多少前端开发场景,各个场景的样本数据质量怎么样,数据标准是否统一,特征工程处理是否统一,样本是否存在二义性,互通性如何,这是我们当下所面临的问题。 -
模型召回低、存在误判: 我们往往会在样本里堆积许多不同场景下不同种类的样本作为训练,期望通过一个模型来解决所有的识别问题,但这却往往会让模型的部分分类召回率低,对于一些有二义性的分类也会存在误判。
★ 问题定义

-
第一步: 尽可能多地找出相关的设计稿,一个个枚举里面的图片类型。 -
第二步: 对图片类型进行合理归纳归类,这是最容易有争论的地方,定义不好有二义性会导致最有模型准确度问题。 -
第三步: 分析每类图片的特征,这些特征是否典型,是否是最核心的特征点,因为关系到后续模型的推理泛化能力。 -
第四步: 每类图片的数据样本来源是否有,没有的话能否自动造; 如果数据样本无法有,那就不适合用模型,可以改用算法规则等方式替代先看效果。
★ 样本质量

数据样本工程体系
★ 模型

D2C 场景
过程思考
-
初期,我们可以在设计稿里手动约定循环体的协议来达成 -
根据图层的上下文信息可做一些规则的判断,来判断是否是循环体 -
利用机器学习的图层特征,可尝试做规则策略的更上游的策略优化 -
生成循环体的一些正负样本来通过深度模型进行学习
业务落地
2019 双十一落地

D2C 代码生成用户更改情况
整体落地情况
-
模块数 12681 个, 周新增 540 个左右; -
用户数 4315 个,周新增 150 个左右; -
自定义DSL: 总数 109 个;
-
设计稿全链路还原: 通过 Sketch、PhotoShop 插件一键导出设计稿图层,生成自定义的 DSL 代码。 -
图像链路还原: 支持用户自定义上传图片、文件或填写图片链接,直接还原生成自定义的 DSL 代码。
后续规划
-
继续降低设计稿要求,争取设计稿 0 协议,其中分组、循环的智能识别准确度提升,减少视觉稿协议的人工干预成本。 -
组件识别准确度提升,目前只有 72% 的准确度,业务应用可用率低。 -
页面级和项目级还原能力可用率提升,依赖页面分割能力的准确度提升。 -
小程序、中后台等领域的页面级还原能力提升,含复杂表单、表格、图表的整体还原能力。 -
静态图片生成代码链路可用度提升,真正可用于生产环境。 -
算法工程产品完善,样本生成渠道更多元,样本集更丰富。 -
D2C 能力开源。
 福利来了
福利来了







登录查看更多
相关内容

Arxiv
3+阅读 · 2019年5月10日




相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2019年5月10日